📝 Paper Summary
3D Semantic Segmentation
Sensor Fusion (LiDAR + Camera)
Autonomous Driving Perception
MSeg3D improves 3D semantic segmentation by fusing LiDAR and camera features using geometry-agnostic attention to handle points outside the camera view, combined with asymmetric multi-modal data augmentation.
Core Problem
Existing multi-modal methods severely degrade or fail on LiDAR points outside the camera's field of view (FOV) and struggle with heterogeneous data augmentation, often limiting performance to just the intersected region.
Why it matters:
- LiDAR-only methods struggle with small/distant objects due to sparsity, while cameras offer rich appearance details.
- Current fusion methods (like PMF) discard or poorly handle points outside the camera FOV, requiring separate models for different regions.
- Rigid constraints on synchronous augmentation (e.g., flipping only) prevent using effective modality-specific augmentations, limiting model robustness.
Concrete Example:
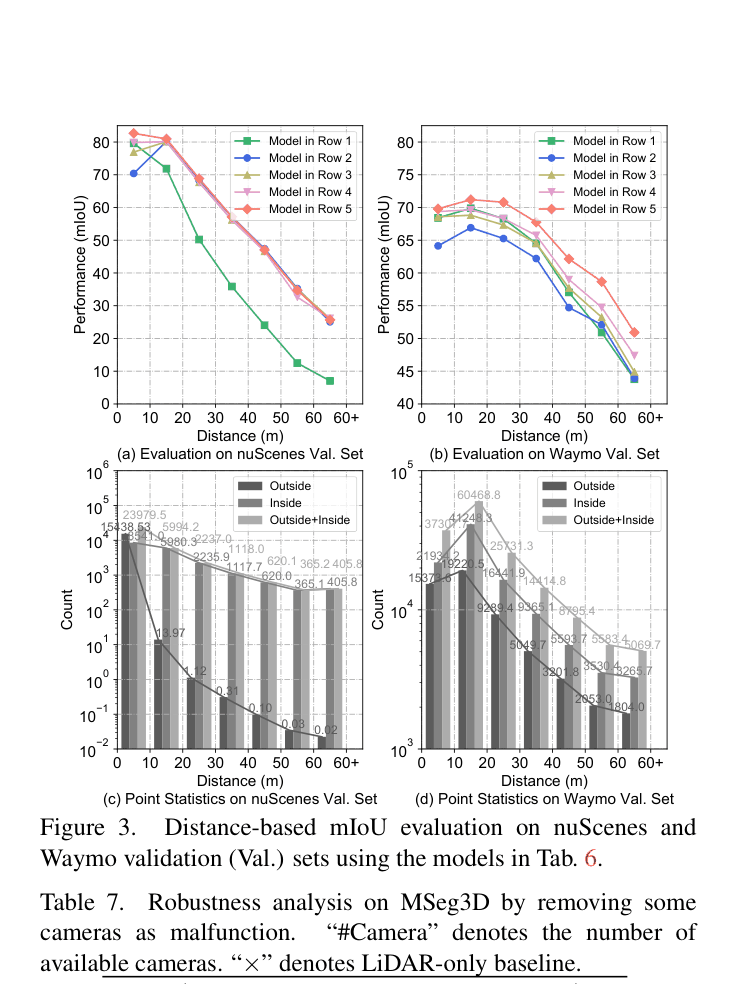
In the nuScenes dataset, points outside the camera FOV (e.g., side/rear areas if cameras are missing or limited) cannot be fused geometrically. Standard methods yield 0 gain or degrade on these 'outside' points. MSeg3D uses pseudo-camera features to segment these points effectively.
Key Novelty
Multi-modal fusion via Semantic-based Feature Fusion (SF-Phase) and Asymmetric Augmentation
- SF-Phase: Aggregates category-wise semantic embeddings from both modalities to fuse features effectively even for points without geometric correspondence (outside camera FOV).
- Cross-modal Feature Completion: Trains the LiDAR branch to predict 'pseudo-camera' features, which are used to fill in missing data for points outside the camera view during inference.
- Asymmetric Augmentation: Decouples geometric transformations (applied to LiDAR) from photometric ones (applied to images), allowing diverse augmentation without breaking sensor alignment.
Architecture
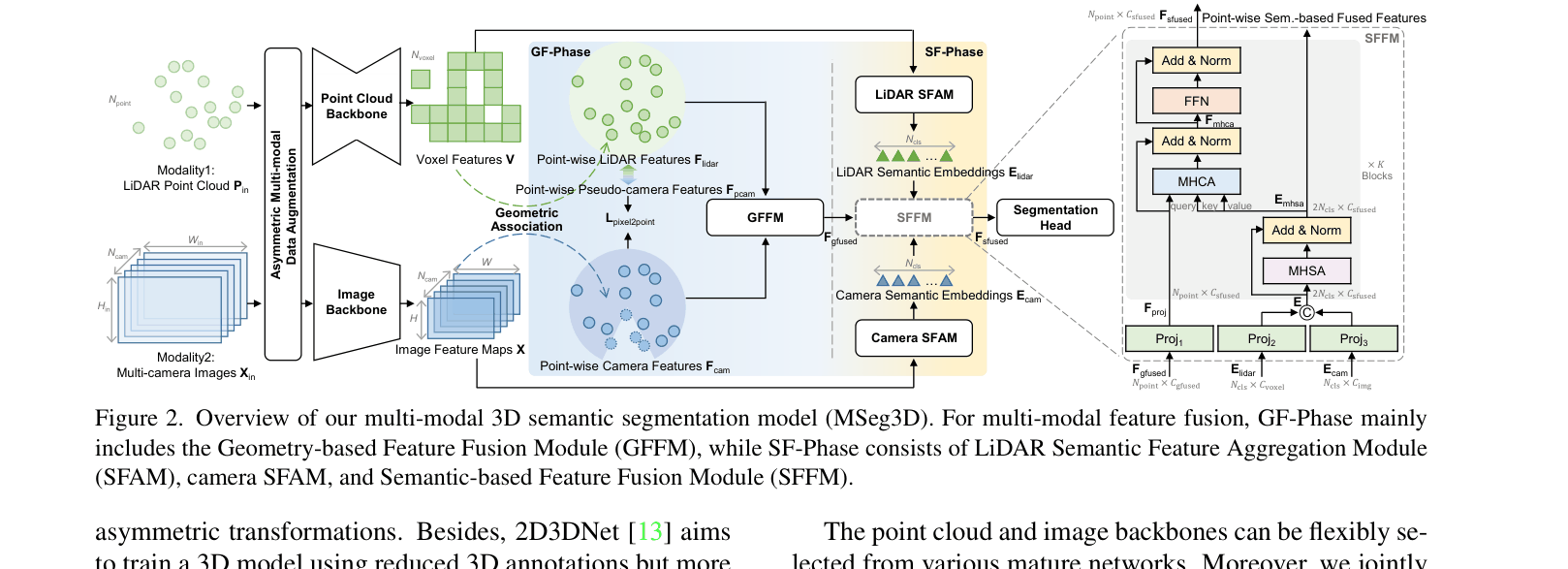
Overview of MSeg3D architecture including feature extraction, GF-Phase, SF-Phase, and auxiliary losses.
Evaluation Highlights
- Achieves 81.14 mIoU on nuScenes test set, outperforming the previous best multi-modal method (2D3DNet) by +1.18 points.
- Improves mIoU on Waymo validation set to 69.63, narrowing the gap between 'points inside FOV' (70.19) and 'all points' (69.63) to just 0.56 points.
- Robust to camera failure: Outperforms LiDAR-only baseline even with 0 cameras available (74.47 vs 72.00 mIoU on nuScenes) due to learned feature completion.
Breakthrough Assessment
8/10
Significantly advances multi-modal fusion by solving the 'points outside FOV' problem and enabling flexible augmentation, achieving SOTA on major benchmarks.