📝 Paper Summary
Multi-modal learning
Missing modality adaptation
ShaSpec handles missing modalities in both segmentation and classification by disentangling features into shared (modality-consistent) and specific (modality-unique) components via auxiliary alignment and classification tasks.
Core Problem
Existing multi-modal models struggle when data modalities are missing during training or testing, often requiring complex, task-specific architectures that don't generalize well between classification and segmentation.
Why it matters:
- Real-world medical data (e.g., MRI) often lacks specific sequences (modalities) due to cost or patient constraints, breaking models trained on full data.
- Current solutions are either 'dedicated' (training separate models for every missing combination) or task-specific (hard to adapt from segmentation to classification).
- Sophisticated generative approaches for missing data are often computationally heavy and unstable.
Concrete Example:
In brain tumor segmentation (BraTS), a model might expect 4 MRI modalities (Flair, T1, T1ce, T2). If T1ce is missing for a patient, standard multi-modal models fail. Dedicated approaches would require training 15 different models for all possible missing combinations.
Key Novelty
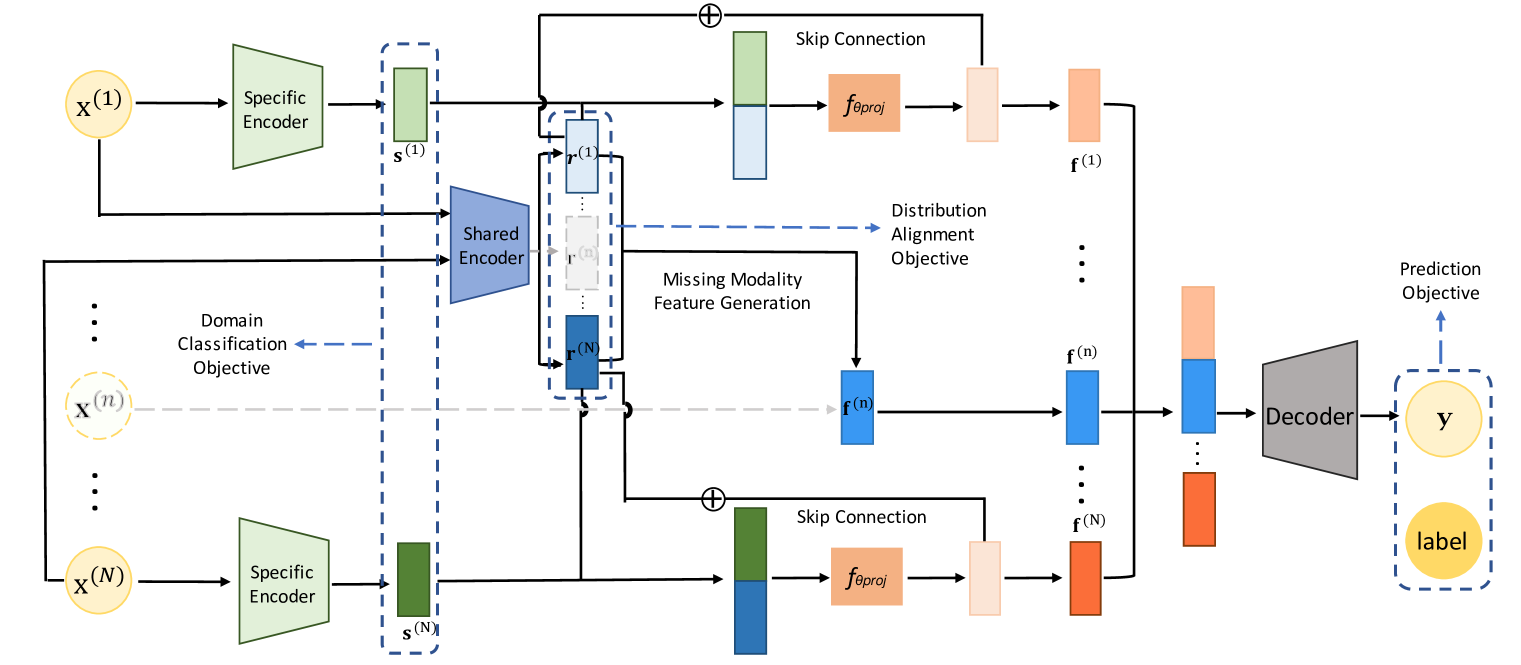
Shared-Specific Feature Modelling (ShaSpec)
- Decomposes input data into 'shared' features (consistent across all modalities) and 'specific' features (unique to each modality) using distinct encoders.
- Enforces this separation via auxiliary tasks: 'Distribution Alignment' (making shared features indistinguishable by modality) and 'Domain Classification' (ensuring specific features predict their source modality).
- Handles missing modalities by generating the missing 'shared' feature as an average of available shared features, while dropping the missing 'specific' feature.
Architecture
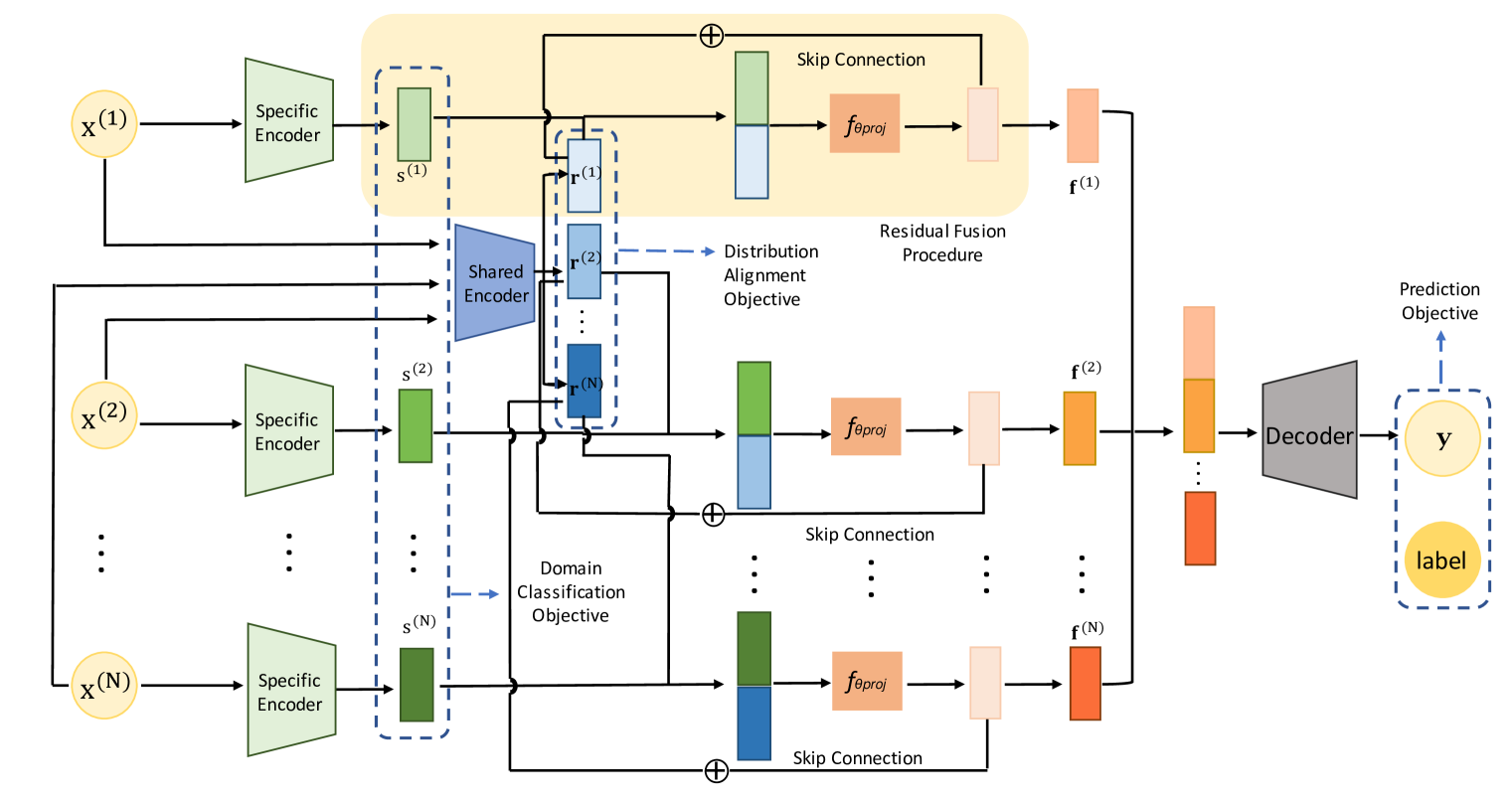
The ShaSpec architecture during full-modality training/evaluation.
Evaluation Highlights
- On BraTS2018 (Brain Tumor Segmentation), improves state-of-the-art by >3% for enhancing tumor, >5% for tumor core, and >3% for whole tumor dice scores.
- Outperforms competing methods like HeMIS and Robust-Mseg by a large margin on segmentation accuracy.
- Demonstrates versatility by achieving state-of-the-art results on both medical image segmentation and standard computer vision classification tasks.
Breakthrough Assessment
8/10
Significant performance jumps (3-5%) on established benchmarks (BraTS) with a method that is notably simpler and more generalizable (handling both segmentation and classification) than prior complex generative approaches.