📝 Paper Summary
Multi-modal Instruction Tuning
3D Vision-Language Models
Evaluation Benchmarks
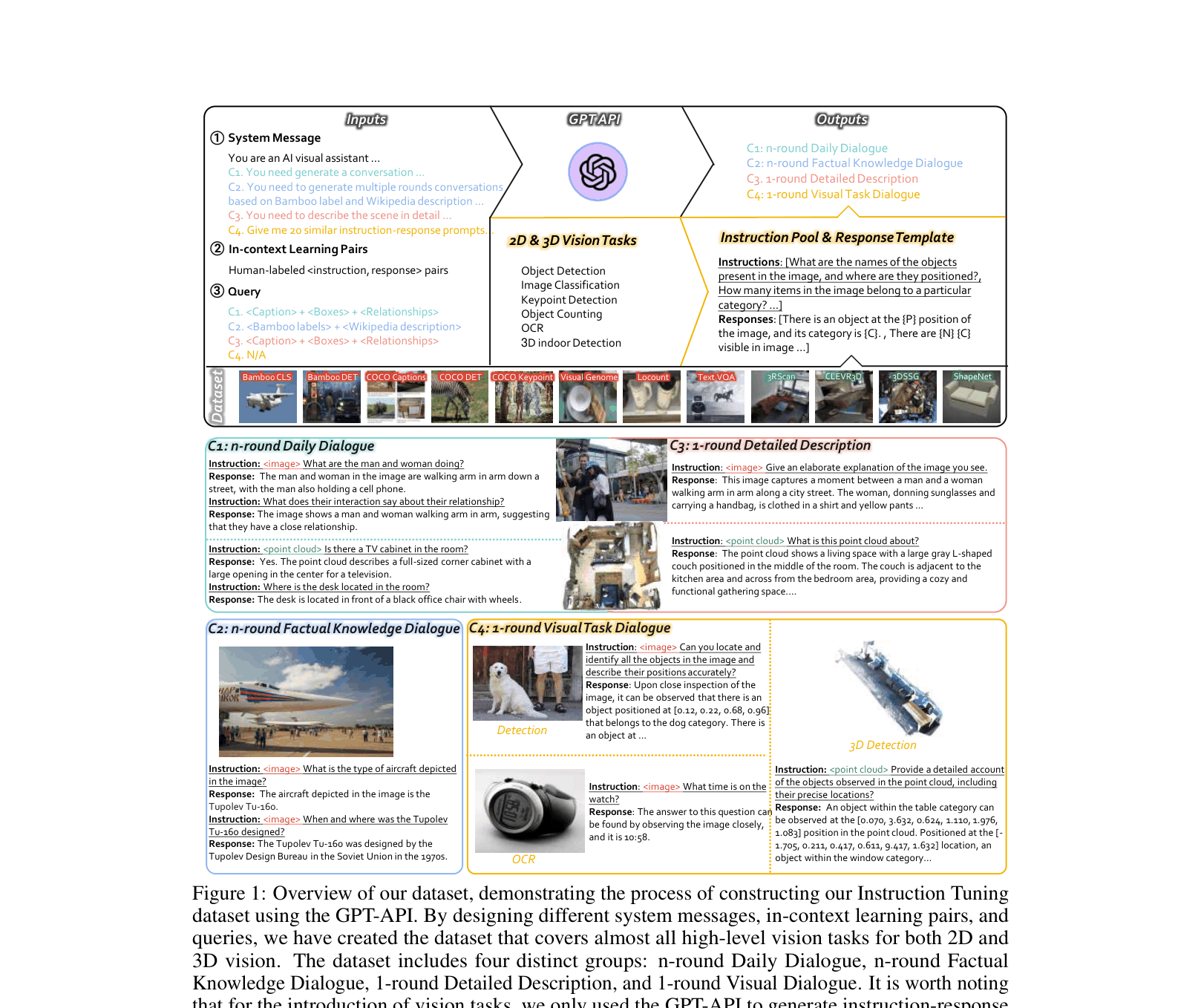
LAMM introduces a comprehensive open-source ecosystem including a multi-modal instruction-tuning dataset covering 2D images and 3D point clouds, a training framework, and a benchmark for evaluating MLLMs on vision tasks.
Core Problem
Existing Multi-modal Large Language Models (MLLMs) are either closed-source (GPT-4V) or lack comprehensive benchmarks and datasets, particularly for 3D modalities and fine-grained localization tasks.
Why it matters:
- Current open-source MLLMs struggle with fine-grained tasks like object detection and counting because their training data lacks dense visual annotations converted into language instructions
- There is a lack of standardized benchmarks to quantitatively evaluate MLLMs on traditional computer vision tasks (detection, OCR, etc.) beyond simple conversation
- 3D vision-language research is lagging behind 2D due to the scarcity of high-quality 3D instruction-following datasets
Concrete Example:
In object counting tasks (e.g., 'How many seashells are there?'), existing MLLMs like MiniGPT-4 often fail to output a number or hallucinate, whereas LAMM's dataset includes specific counting instruction templates to teach this capability.
Key Novelty
Language-Assisted Multi-Modal (LAMM) Ecosystem
- First open-source instruction tuning dataset to include 3D point clouds alongside images, enabling MLLMs to understand and reason about 3D environments
- Constructs 'Visual Task Dialogues' by converting dense vision annotations (bounding boxes, keypoints) into instruction-response pairs using GPT-API, enhancing model grounding capabilities
- Proposes two new evaluation strategies for MLLMs: a Binary Locating Metric for object grounding and a GPT-based scoring metric for caption quality
Architecture
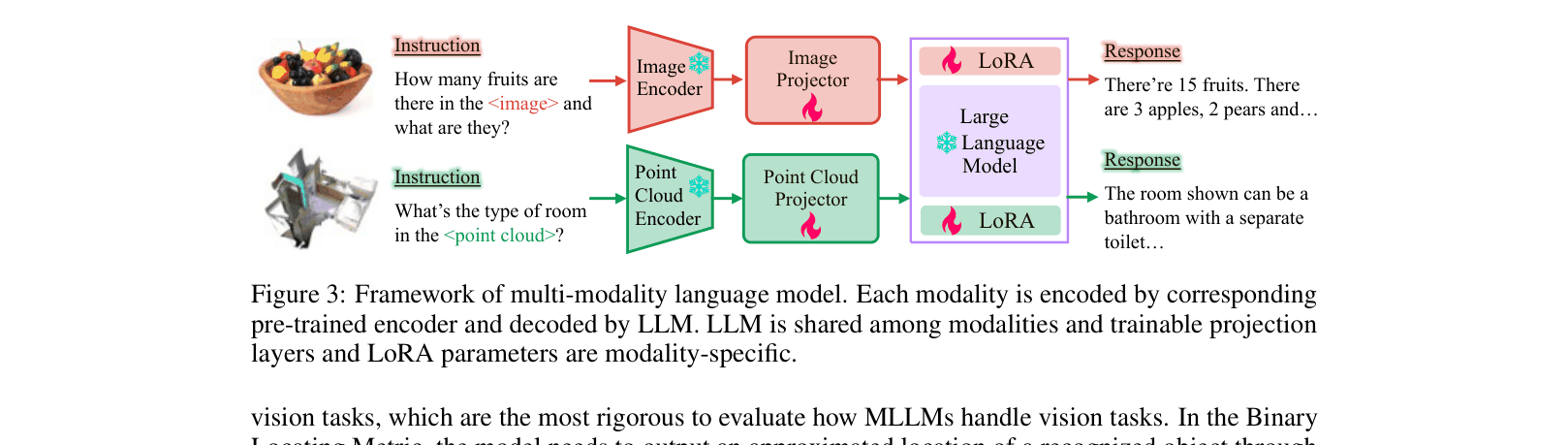
The LAMM training framework supporting multiple modalities (Images and Point Clouds) with a shared LLM.
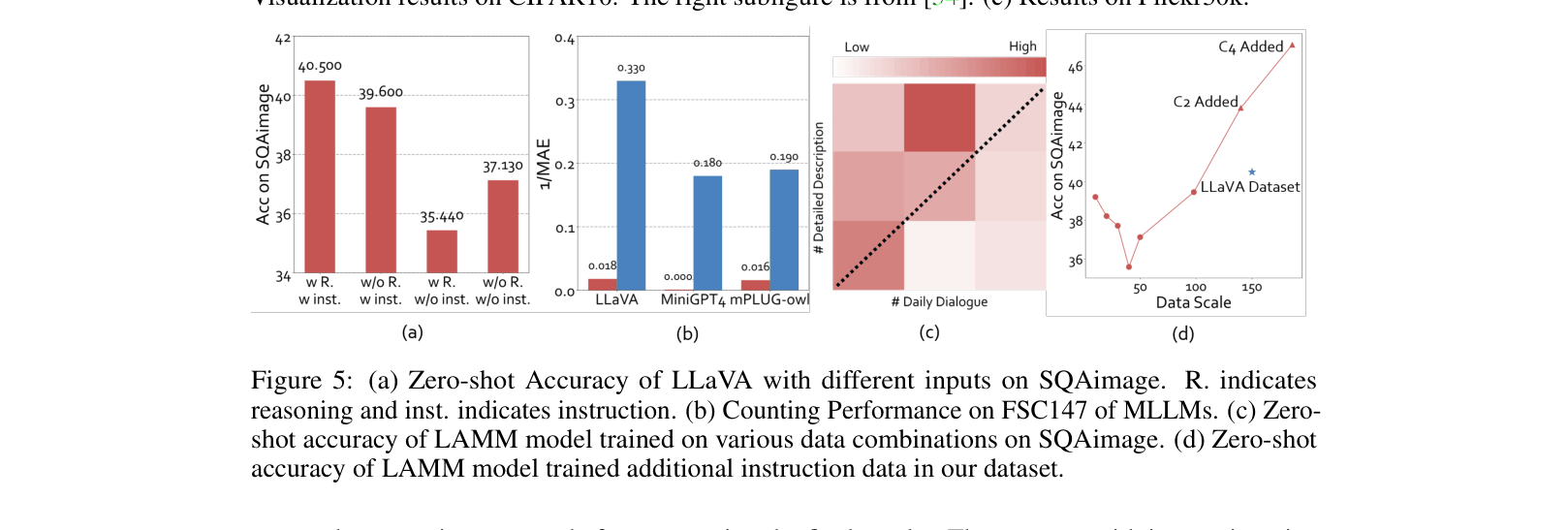
Evaluation Highlights
- LAMM baseline outperforms LLaVA by +174% relative improvement (14.73 -> 31.2) on the proposed Binary Locating Metric, demonstrating superior grounding ability
- Achieves 49.88% accuracy on ScienceQA (Image), outperforming MiniGPT-4 (43.43%) and mPLUG-owl (36.39%) in zero-shot settings
- Successfully extends MLLM capabilities to 3D tasks, achieving 26.54% accuracy on ScanQA (3D VQA) in zero-shot and 99.89% after fine-tuning (though likely overfitting due to small dataset size)
Breakthrough Assessment
8/10
Significant contribution as one of the first comprehensive benchmarks and datasets covering both 2D and 3D modalities. The framework is standard, but the dataset construction methodology and 3D extension are highly valuable.