📊 Experiments & Results
Evaluation Setup
Code generation tasks where a model generates a solution, receives a critique, and revises the solution.
Benchmarks:
- CodeContests (Competitive Programming)
- LiveCodeBench (Code Generation (24.08-24.11))
- MBPP+ (Basic Programming)
- JudgeBench (Generative Reward Modeling)
Metrics:
- Pass@1
- Δ↑ (percentage of wrong solutions corrected)
- Δ↓ (percentage of correct solutions broken)
- F1 Score (for discrimination)
- Timeout Rate
- Statistical methodology: Reported standard error across 5 seeds in figures.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Performance on CodeContests using Qwen2.5-Coder as the Generator shows CTRL significantly improving over zero-shot and self-critique baselines. | ||||
| CodeContests | Pass@1 | 7.88 | 11.76 | +3.88 |
| CodeContests | Pass@1 | 8.36 | 11.76 | +3.40 |
| Multi-turn scaling capabilities of CTRL on CodeContests. | ||||
| CodeContests | Pass@1 | 7.88 | 16.24 | +8.36 |
| Weak-to-strong generalization: CTRL (Qwen-32B based) guiding GPT-4o. | ||||
| CodeContests | Pass@1 | 20.61 | 23.03 | +2.42 |
| CodeContests | Pass@1 | 20.61 | 25.45 | +4.84 |
Experiment Figures
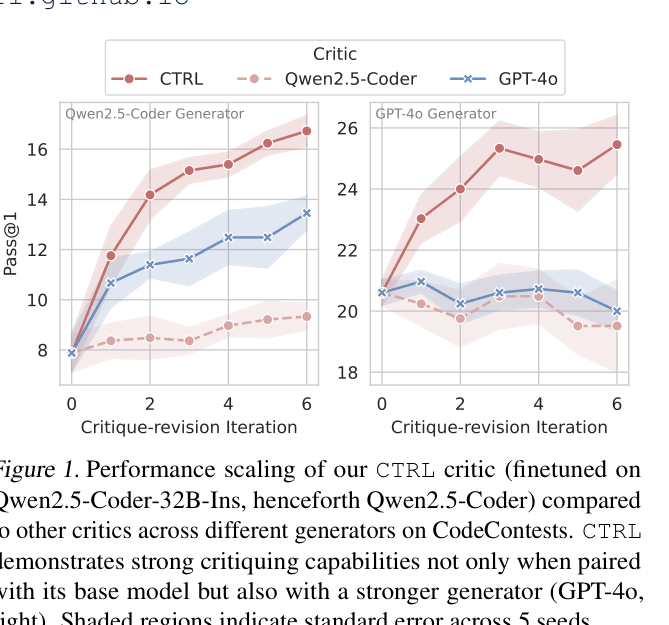
Pass@1 performance scaling over critique-revision iterations for CTRL vs. other critics.

Regression rate (error compounding) over iterations.
Main Takeaways
- CTRL significantly outperforms self-critique methods and even stronger model critics (GPT-4o) on challenging benchmarks.
- The method demonstrates 'weak-to-strong' generalization: a critic trained on a weaker model (Qwen) can effectively guide a stronger model (GPT-4o).
- RL training is crucial for reducing the regression rate (breaking correct code), which is the key enabler for multi-turn iterative improvement.
- CTRL critics act as effective generative reward models, achieving competitive discrimination performance on JudgeBench against larger models.