📝 Paper Summary
Multi-modal Foundation Models
Vision-Language Pre-training
Video-Language Pre-training
mPLUG-2 introduces a modularized architecture that shares universal layers for collaboration while using modality-specific modules to prevent entanglement, enabling flexible unification of text, image, and video tasks.
Core Problem
Existing multi-modal foundation models either use a single network for all modalities, causing interference (modality entanglement), or rely heavily on separate encoders, limiting collaboration.
Why it matters:
- Jointly training on diverse modalities (text, image, video) often leads to negative interference where improving one modality degrades another
- Rigid architectures cannot flexibly select sub-modules for specific downstream tasks, leading to computational inefficiency during inference
- Balancing the gain from modality collaboration against the noise from modality entanglement is difficult in single-module architectures
Concrete Example:
A single Transformer trained on both static images and dynamic videos might struggle because spatial patterns in images interfere with the temporal motion patterns required for video understanding. mPLUG-2 solves this by using a shared spatial module but a separate 'local temporal modeling' module specifically for video frames.
Key Novelty
Modularized Multi-modal Foundation Model
- Separates the network into modality-specific encoders (handling entanglement) and shared universal layers (handling collaboration) to balance distinctiveness and synergy
- Introduces a Dual-vision Encoder that shares spatial processing for images/video but adds specific local temporal modules for video dynamics
- Uses a Universal Layers Module as a pivot to project vision and language into a shared semantic space while maintaining original modality features via cross-attention
Architecture
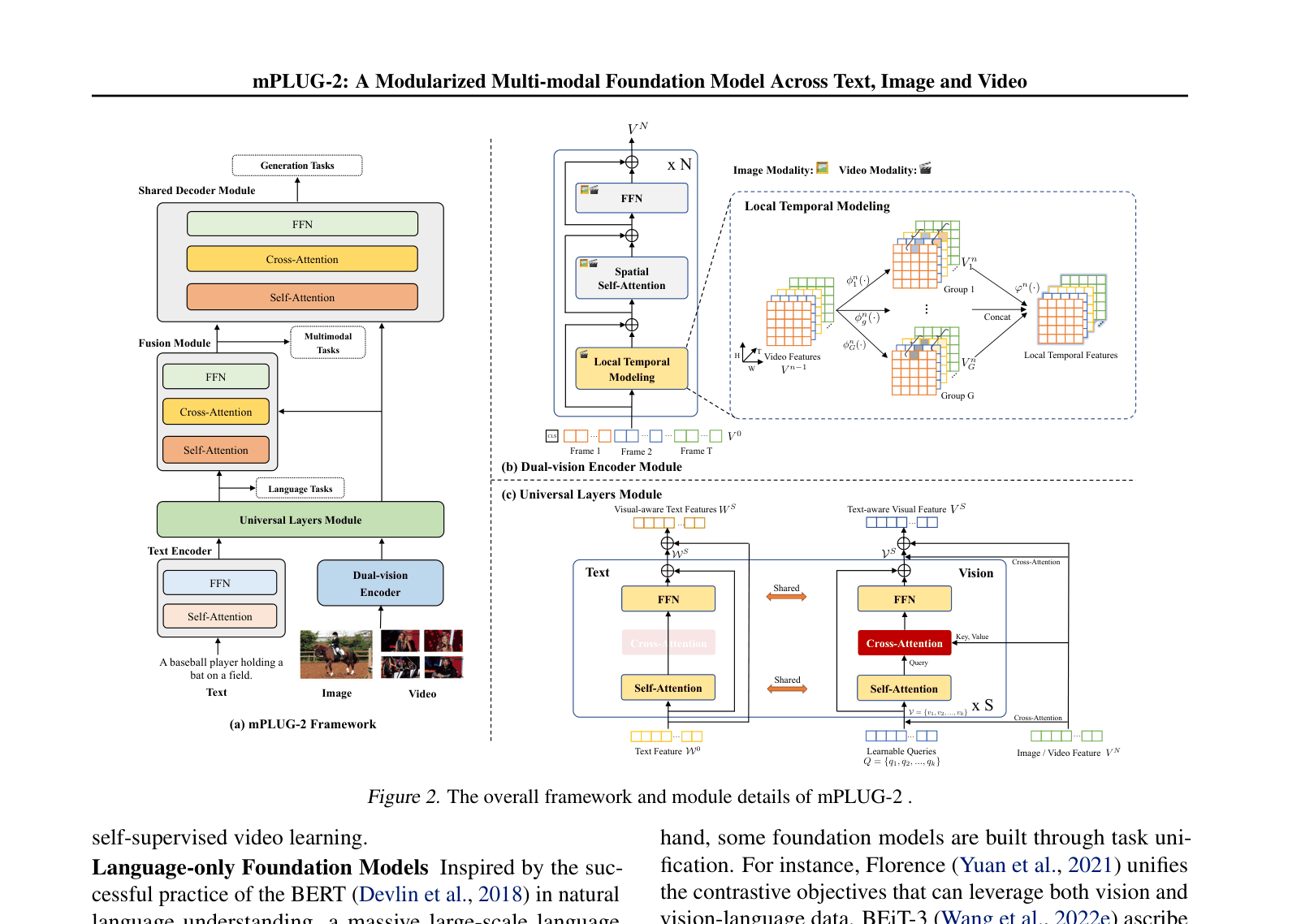
The overall mPLUG-2 framework and detailed schematics of the Dual-vision Encoder and Universal Layers modules.
Evaluation Highlights
- Achieves 48.0% Top-1 Accuracy on MSRVTT Video QA, surpassing the previous state-of-the-art by 0.6% despite smaller data scale
- Sets new SOTA on MSRVTT Video Captioning with 80.3 CIDEr score, outperforming GIT2 (75.9) and VideoCoCa (73.2)
- Matches or exceeds SOTA on ImageNet-1K classification (88.5% Top-1) among general-purpose foundation models without using ImageNet-21K or JFT pre-training data
Breakthrough Assessment
8/10
Significantly advances multi-modal unification by effectively solving the modality entanglement vs. collaboration trade-off. The modular design delivers SOTA performance across video, image, and text tasks simultaneously.