📊 Experiments & Results
Evaluation Setup
Visual Instruction Tuning of LLaVA-1.5 using MMInstruct, followed by evaluation on standard VLLM benchmarks.
Benchmarks:
- MME (Comprehensive multimodal evaluation)
- LLaVA-Bench (In-the-Wild) (Real-world image understanding)
- MMBench (Multimodal perception and reasoning)
- MM-Vet (Integrated multimodal capabilities)
Metrics:
- Score (Benchmark specific)
- Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Fine-tuning on MMInstruct consistently improves performance over the LLaVA-1.5 baseline across a wide variety of benchmarks. | ||||
| MME | Total Score | 1531.3 | 1626.2 | +94.9 |
| LLaVA-Bench (In-the-Wild) | Score | 70.7 | 74.5 | +3.8 |
| MMBench | Accuracy | 67.7 | 68.2 | +0.5 |
| MM-Vet | Score | 35.4 | 36.2 | +0.8 |
| POPE | Accuracy | 85.9 | 87.2 | +1.3 |
Experiment Figures
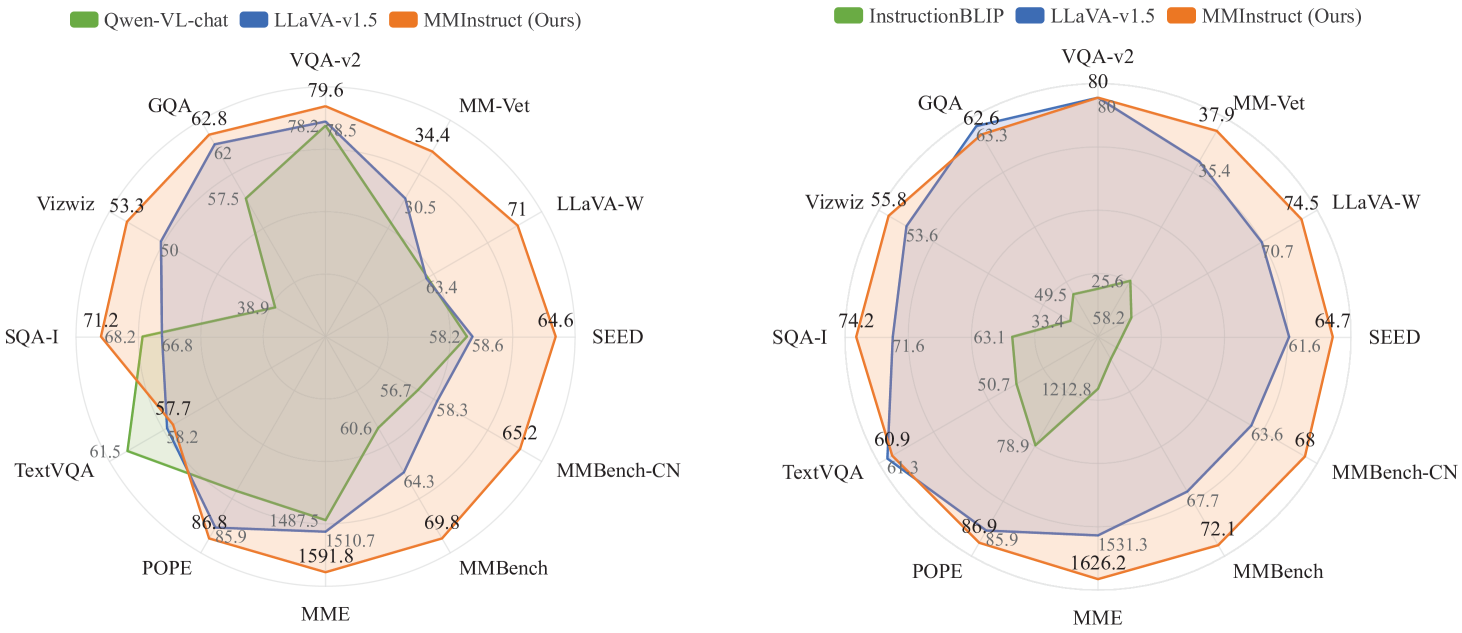
Radar chart comparing LLaVA-1.5 (Baseline) vs. LLaVA-1.5 (MMInstruct) across multiple benchmarks.
Main Takeaways
- Fine-tuning on MMInstruct achieves new state-of-the-art performance on 10 out of 12 benchmarks compared to the strong LLaVA-1.5 baseline.
- The dataset construction method (Data Engine) reduces costs to 1/6th of manual annotation while maintaining high quality.
- Using GPT-4V for detailed captioning significantly helps in generating diverse instructions and reducing hallucinations compared to using raw image annotations.
- The inclusion of 24 diverse domains, including OCR and reasoning, improves the model's ability to generalize to complex, real-world tasks.