📝 Paper Summary
Multi-modal learning
Parameter-efficient fine-tuning
Semantic segmentation
GoPT introduces semantic grouping into visual prompt tuning, enabling efficient adaptation of frozen RGB pre-trained models to multi-modal segmentation tasks by training less than 1% of parameters.
Core Problem
Existing multi-modal segmentation methods rely on full fine-tuning of RGB pre-trained models, which is parameter-inefficient and struggles to balance retaining pre-trained knowledge with learning modality-specific patterns.
Why it matters:
- Full fine-tuning creates a large storage burden by requiring separate full model copies for every downstream task.
- Limited labeled data in downstream multi-modal tasks (e.g., RGB-Thermal) leads to overfitting when updating all parameters.
- Current fusion methods often fail to bridge cross-modal gaps (heterogeneity) or handle information imbalances between modalities.
Concrete Example:
In RGB-Thermal segmentation, a standard alignment fusion might fail to align a pedestrian visible in thermal but obscured in RGB because it enforces global distribution matching rather than grouping specific semantic objects.
Key Novelty
Grouping Prompt Tuning (GoPT)
- Inserts learnable prompt vectors into a frozen RGB backbone that are dynamically updated via a semantic grouping mechanism rather than static vectors.
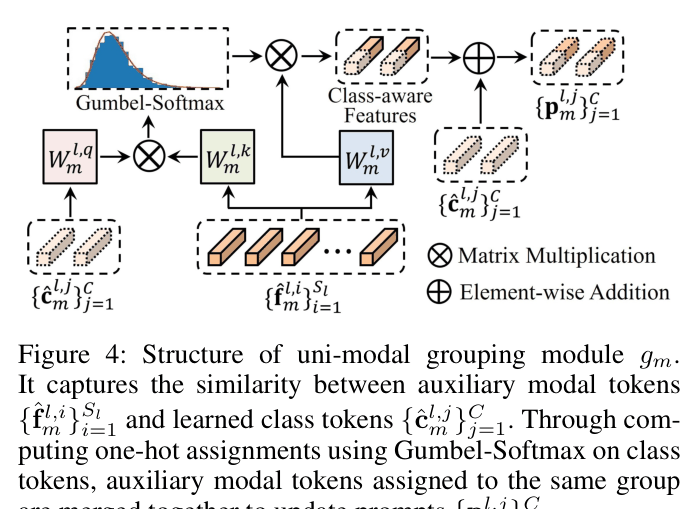
- Uses a Class-Aware Uni-Modal Prompter (CUP) to group auxiliary modality pixels into semantic clusters, enhancing intra-modal feature learning.
- Uses an Alignment-Induced Cross-Modal Prompter (ACP) to inject these grouped auxiliary features into the RGB stream, guiding the frozen backbone to process multi-modal data.
Architecture
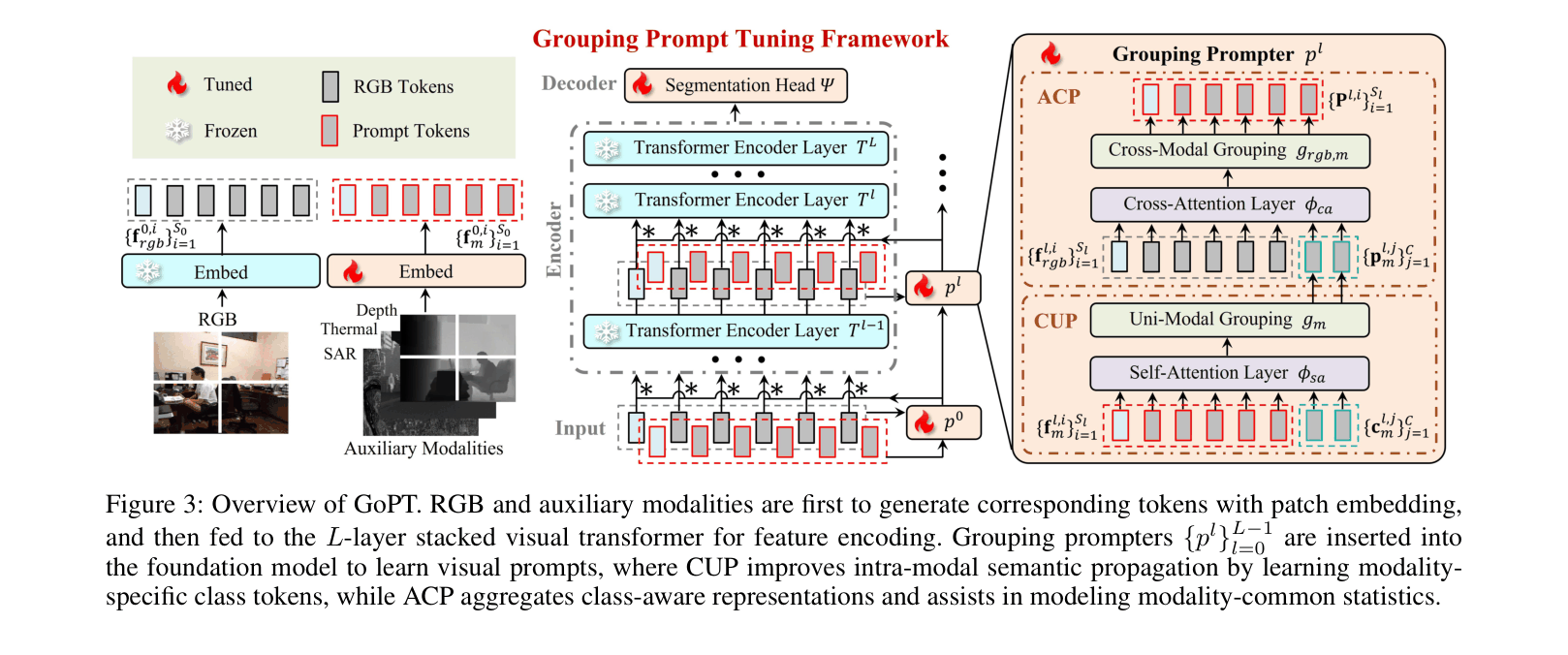
Overview of the GoPT framework showing the frozen foundation model and the inserted trainable prompters.
Evaluation Highlights
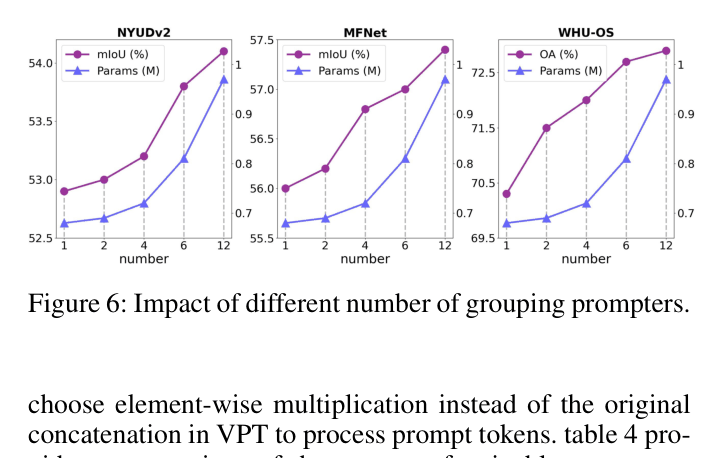
- Achieves state-of-the-art 54.1% mIoU on NYUDv2 (RGB-D) using only 0.97M trainable parameters, outperforming full fine-tuning methods with >100M parameters.
- Outperforms the specialized RSFNet on MFNet (RGB-T) with 57.4% mIoU vs 56.2%, despite freezing the backbone.
- Surpasses previous SOTA on WHU-OS (RGB-SAR) by 2.8% Average Accuracy while training <1% of the model parameters.
Breakthrough Assessment
8/10
Significantly reduces parameter costs (trains <1%) while matching or beating SOTA full fine-tuning methods across three distinct multi-modal tasks (Depth, Thermal, SAR). A strong proof-of-concept for prompt tuning in dense prediction.