📊 Experiments & Results
Evaluation Setup
Zero-shot, Few-shot, and Full-data supervised evaluation across 14 datasets
Benchmarks:
- IDRiD, APTOS2019, MESSIDOR2 (Diabetic Retinopathy Classification)
- Retina Image Bank (Rare Disease Classification / Multi-modal Retrieval)
- UK Biobank (Systemic Disease Prediction (Stroke, MI, etc.))
- OphthalVQA (Visual Question Answering)
Metrics:
- AUROC (Area Under ROC)
- AUPR (Area Under Precision-Recall)
- Recall@K (Retrieval)
- F1 Score / BLEU (VQA)
- Statistical methodology: Two-sided t-tests comparing EyeCLIP with baselines; 95% Confidence Intervals reported
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Zero-shot performance demonstrates EyeCLIP's superior generalization ability without task-specific training. | ||||
| MESSIDOR2 (DR) | AUROC | 0.654 | 0.757 | +0.103 |
| OCTID (OCT) | AUROC | 0.589 | 0.800 | +0.211 |
| Full-data supervised finetuning shows EyeCLIP achieves SOTA on systemic disease prediction and rare diseases. | ||||
| UK Biobank (Stroke) | AUROC | 0.620 | 0.641 | +0.021 |
| Retina Image Bank (Rare Diseases) | AUROC | 0.523 | 0.561 | +0.038 |
| Cross-modal retrieval tasks validate the quality of the learned joint embedding space. | ||||
| Retina Image Bank | Mean Recall | 45.3 | 50.9 | +5.6 |
Experiment Figures
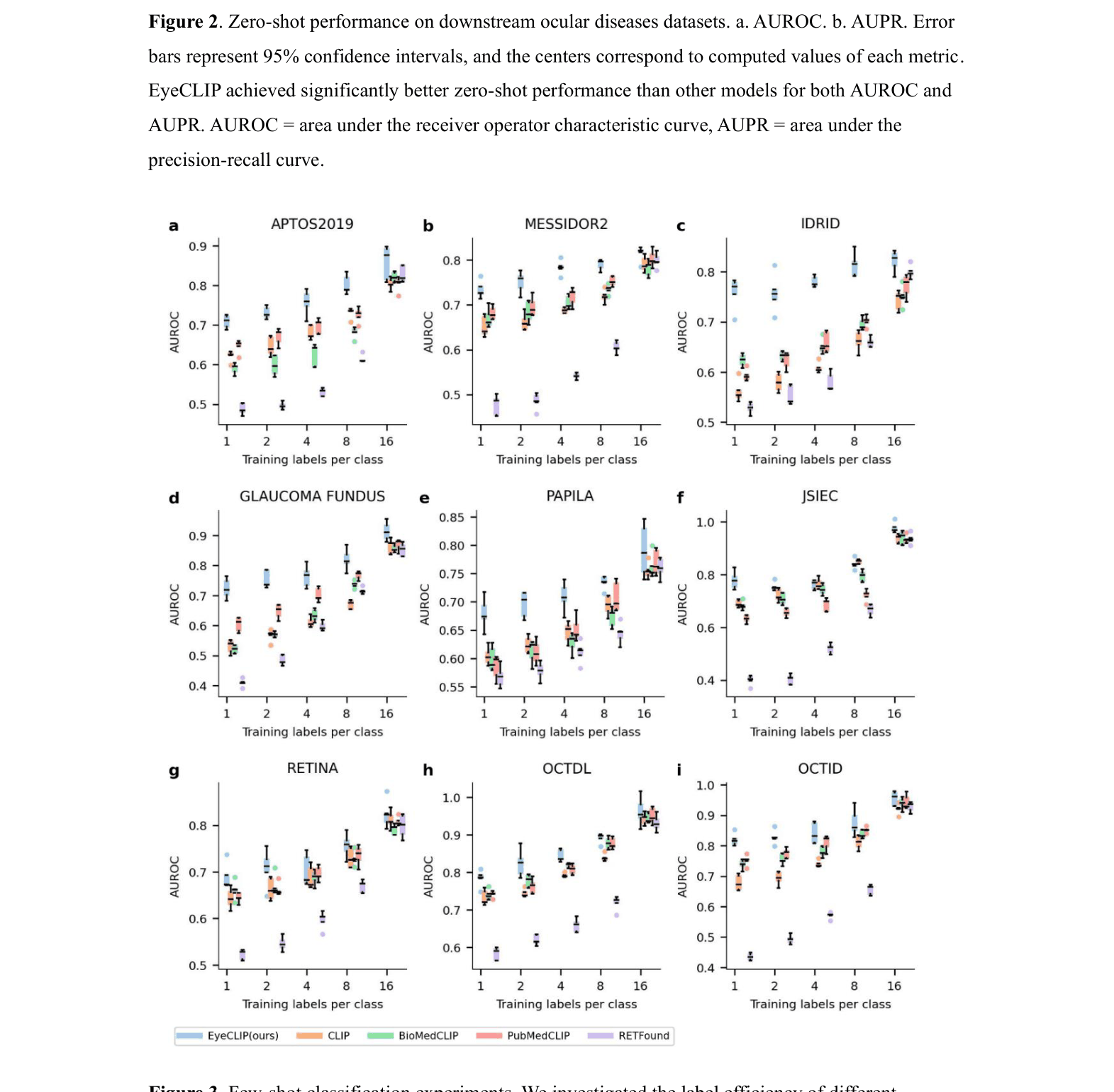
Radar plots and bar charts comparing Zero-shot performance.
Main Takeaways
- Consistent superiority in Zero-shot settings: EyeCLIP beats BioMedCLIP and RETFound across most datasets without seeing training labels, proving effective semantic alignment.
- Data Efficiency: Outperforms baselines significantly in 1-shot to 16-shot scenarios, making it highly valuable for rare diseases where data is scarce.
- Multi-modal robustness: A single shared encoder handles 11 modalities effectively, matching or beating RETFound (which uses modality-specific weights) even on RETFound's native modalities (CFP/OCT).