📝 Paper Summary
Medical Multi-modal Learning
Contrastive Learning
Data Augmentation with Expert Knowledge
eCLIP enhances medical CLIP models by incorporating radiologist eye-gaze heatmaps via a mixup strategy and curriculum learning to improve embedding alignment without altering the core architecture.
Core Problem
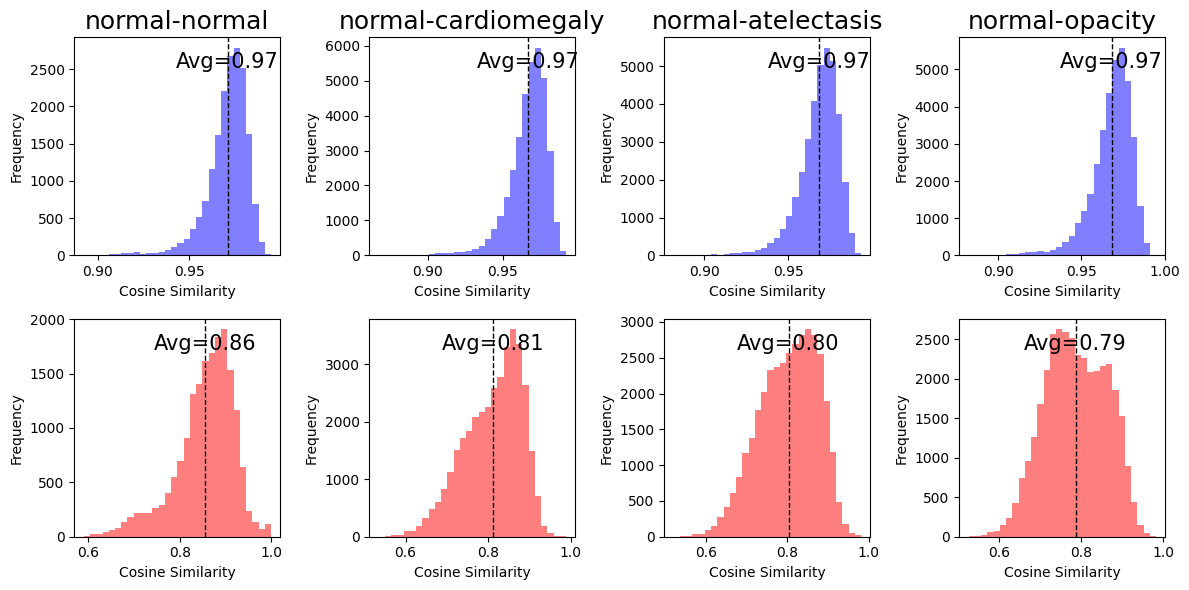
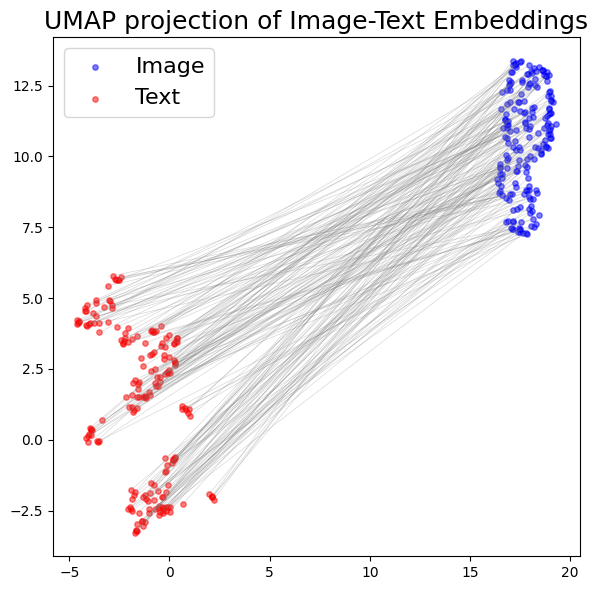
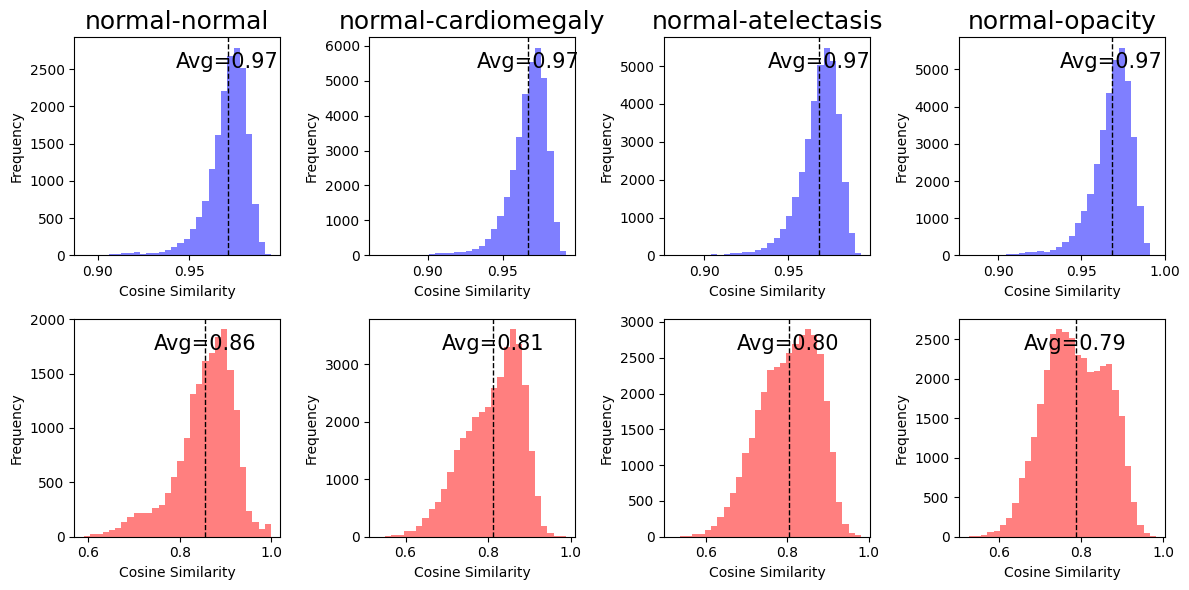
Medical image-text contrastive learning suffers from data scarcity and a 'modality gap,' where embeddings from different modalities (X-rays vs. reports) reside in distinct, non-overlapping regions.
Why it matters:
- Standard CLIP models trained on internet data fail to capture nuanced medical abnormalities, grouping different pathologies too closely in embedding space
- Acquiring large-scale, high-quality medical datasets is difficult due to privacy concerns and the need for expert annotation
- The 'cone effect' restricts embeddings to narrow regions, hampering zero-shot classification and cross-modal retrieval performance
Concrete Example:
In standard CLIP, embeddings for different chest X-ray abnormalities (e.g., cardiomegaly vs. atelectasis) often have cosine similarities near 1, making them indistinguishable. An X-ray of a collapsed lung might be retrieved as similar to a heart enlargement case due to poor spatial segregation.
Key Novelty
Expert-annotated CLIP (eCLIP)
- Integrates scarce radiologist eye-gaze heatmaps as 'expert attention' signals to create high-quality, semantically rich positive pairs for contrastive learning
- Uses a mixup strategy to blend original images with heatmap-augmented versions, effectively multiplying the small expert dataset to improve training density
- Employs a curriculum learning schedule (cold start → warm up → cool down) to gradually introduce expert knowledge without destabilizing the base model's training
Architecture
The complete eCLIP training pipeline, illustrating how expert eye-gaze heatmaps are integrated via a Heatmap Processor and Mixup Augmentation.
Evaluation Highlights
- Consistent improvement in Zero-shot Classification across 5 medical datasets (e.g., +4.6% accuracy on RSNA Pneumonia compared to base CLIP)
- Enhanced retrieval performance: +4.6% improvement in R@1 (Recall at Rank 1) for image-to-text retrieval on the CheXpert dataset compared to base CLIP
- Superior embedding quality: Reduces 'modality gap' distance by ~48% compared to base CLIP, creating more uniform and aligned representations
Breakthrough Assessment
7/10
A solid methodological contribution that creatively solves data scarcity using eye-tracking data and mixup. While specific to medical imaging, the approach to integrating expert attention is generalizable.