📝 Paper Summary
Multi-modal semantic segmentation
Parameter-Efficient Fine-Tuning (PEFT)
Foundation Model Adaptation
The paper adapts the Segment Anything Model (SAM) for multi-modal semantic segmentation by using modality-specific LoRA experts and a dynamic routing mechanism to fuse features from diverse sensors like depth and LiDAR.
Core Problem
SAM is trained primarily on RGB images and performs sub-optimally when applied to diverse modalities (depth, thermal, event data) or when modalities are missing/noisy.
Why it matters:
- Robotics and autonomous driving rely on multi-modal sensors (LiDAR, thermal) for robustness, but current foundation models like SAM are RGB-centric.
- Existing methods struggle with cross-modal inconsistencies (different noise levels, resolutions) and lack mechanisms to handle missing modalities gracefully.
- Full fine-tuning of large models like SAM for every new modality is computationally prohibitive.
Concrete Example:
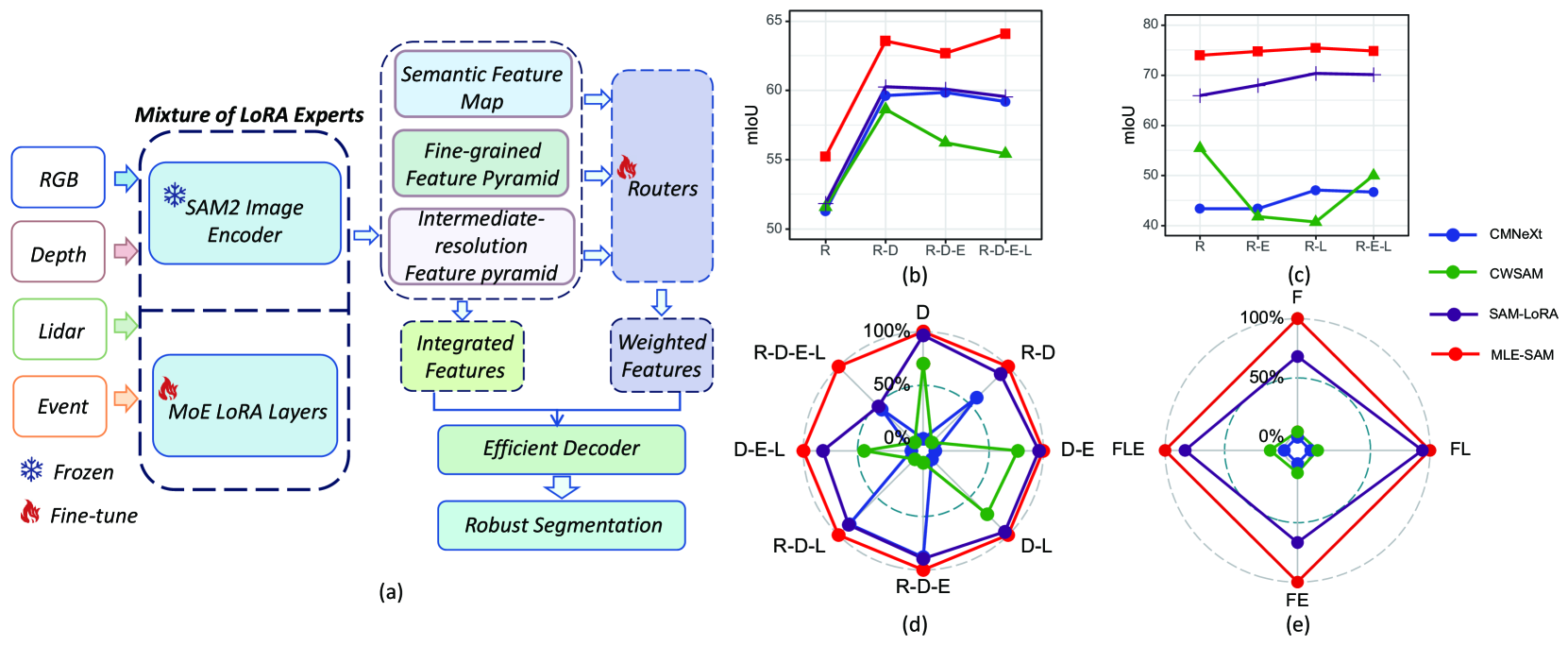
In a scenario with missing modalities (e.g., camera failure leaving only depth data), standard multi-modal models often fail catastrophically because they expect complete inputs. The proposed method improves performance by +32.15% in such missing-modality settings on the MUSES dataset.
Key Novelty
Mixture of LoRA Experts (MoE-LoRA) with Dynamic Routing
- Instead of fine-tuning the whole model, it freezes SAM's backbone and trains lightweight LoRA modules specifically for each modality (RGB, Depth, etc.).
- A 'Mixture of LoRA Experts' (MLE) router dynamically assigns weights to features from different modalities based on their relevance, allowing the model to ignore noisy or missing inputs.
- A dual-pathway decoder combines SAM's original mask decoder with a new auxiliary head to fuse multi-scale features for better semantic accuracy.
Architecture
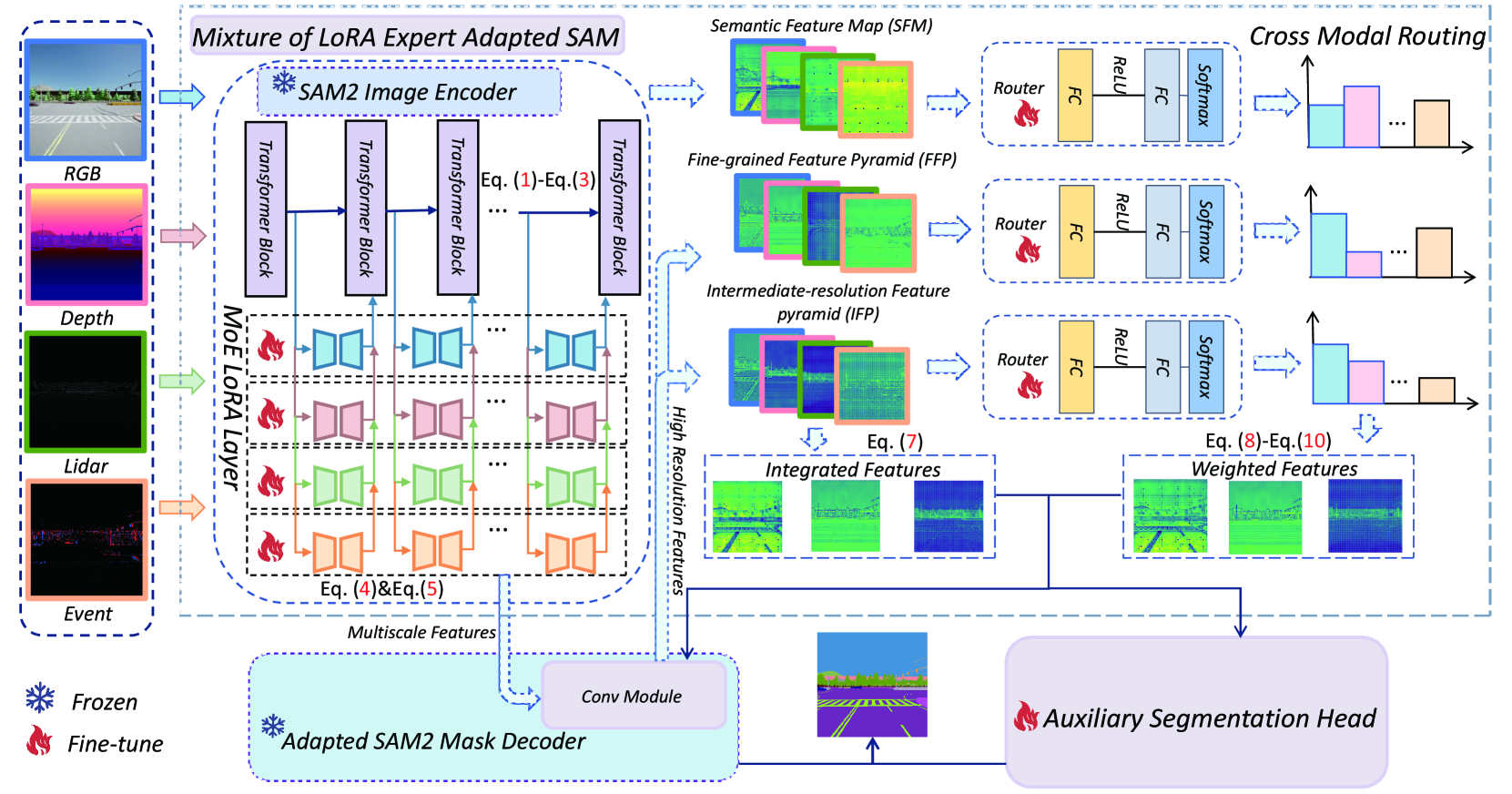
The overall architecture of MLE-SAM, detailing the modality-specific LoRA encoders, the feature pyramid network, the MoE routing mechanism, and the dual-pathway decoder.
Evaluation Highlights
- +28.14% mIoU improvement on the MUSES dataset (3 modalities) compared to state-of-the-art methods.
- +32.15% performance gain on the MUSES dataset under missing modality conditions compared to existing approaches.
- +4.9% mIoU improvement on the DELIVER dataset (4 modalities) compared to state-of-the-art methods.
Breakthrough Assessment
8/10
Significant performance jumps (>20%) in multi-modal and missing-modality settings indicate a strong architectural fit for the problem. Successfully adapting a major foundation model (SAM) to multi-modal tasks with parameter efficiency is a valuable contribution.