📝 Paper Summary
Multi-modal Large Language Models (MLLMs)
Cognitive Evaluation
Developmental Psychology in AI
MLLMs suffer from a fundamental deficit in core knowledge, performing worse on rudimentary tasks innate to infants than on complex reasoning, often relying on shortcut learning.
Core Problem
State-of-the-art MLLMs excel at high-level reasoning but consistently fail at rudimentary tasks intuitive to humans (like counting, spatial reasoning, and object permanence), creating a paradox.
Why it matters:
- Current high-level excellence fails to generalize to real-world scenarios where small condition changes cause significant drops
- The lack of foundational 'developmental start-up software' suggests models lack the grounding required for robust, genuine understanding
- Dependence on spurious correlations (shortcuts) rather than causal understanding makes models brittle and vulnerable to perturbations
Concrete Example:
In an object permanence test (Sensorimotor stage), a ball is hidden under a cup and shuffled. While a human infant tracks it easily, a massive MLLM fails to localize the object despite being able to solve complex math problems, showing a lack of basic physical understanding.
Key Novelty
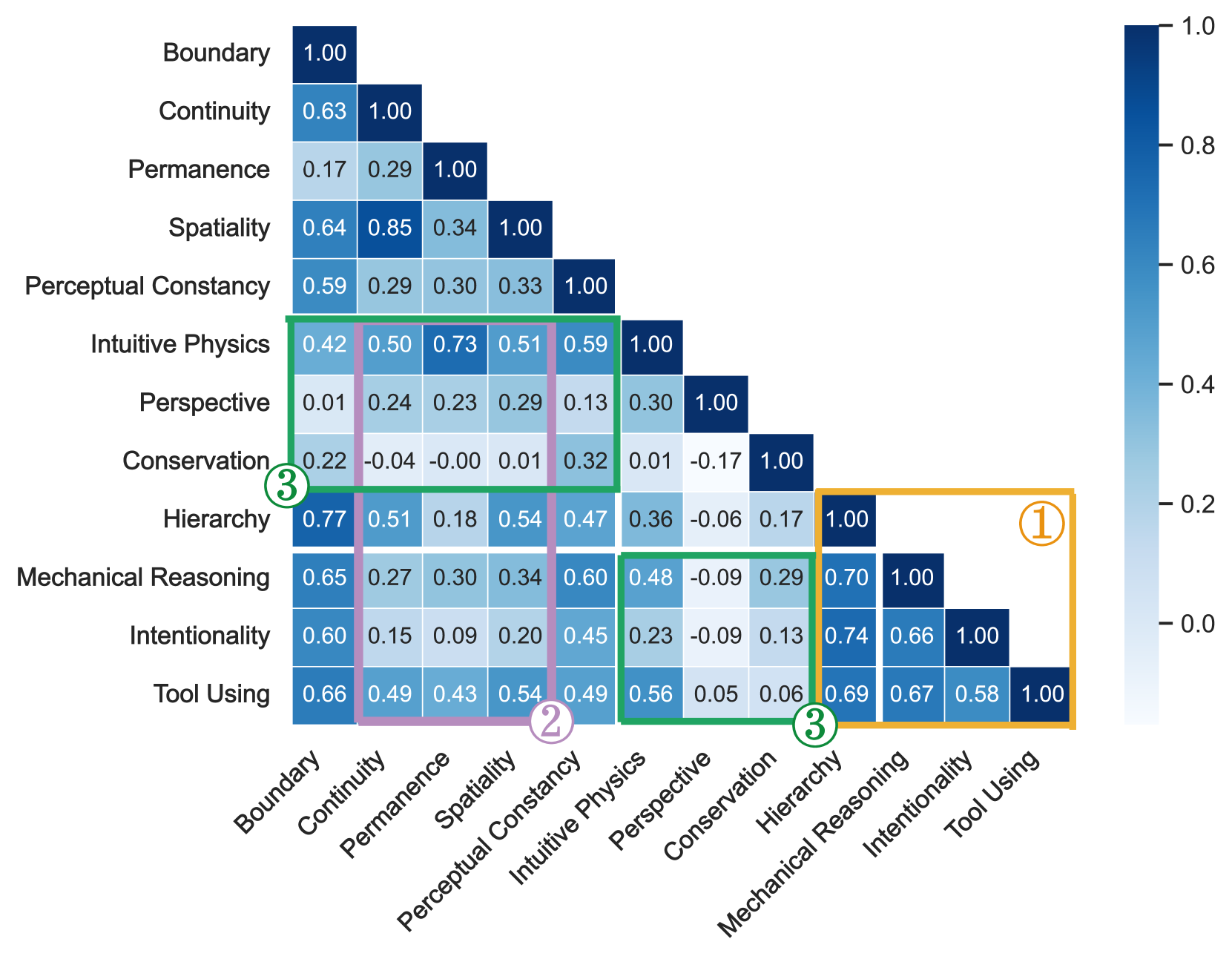
CoreCognition Benchmark & Concept Hacking
- CoreCognition: A large-scale benchmark of 1,503 questions covering 12 core abilities grounded in Piaget's developmental stages (Sensorimotor, Preoperational, Concrete/Formal Operational) to probe fundamental cognitive building blocks.
- Concept Hacking: A controlled evaluation method that manipulates causal features in images to perturb ground-truth labels, distinguishing whether models possess genuine knowledge or rely on visual shortcuts.
Architecture
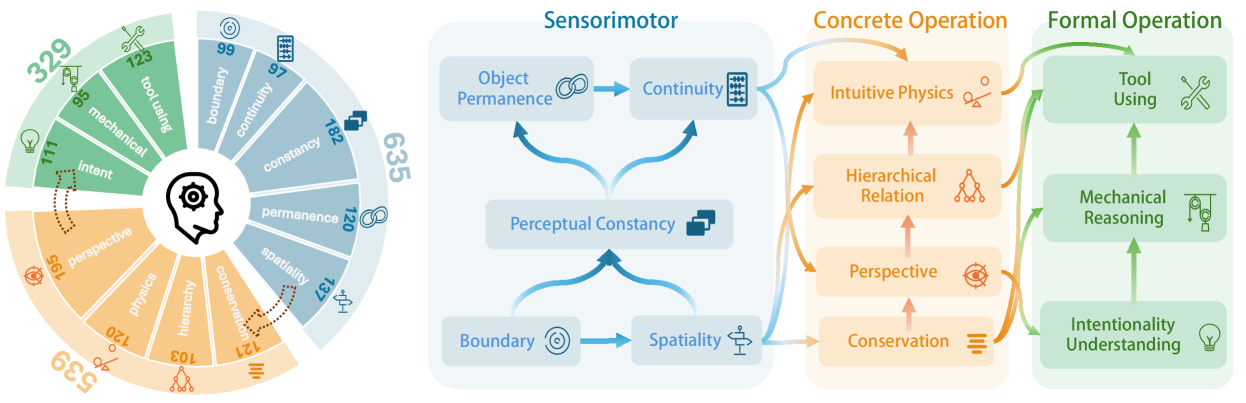
Overview of the CoreCognition benchmark distribution across the four Piagetian developmental stages.
Evaluation Highlights
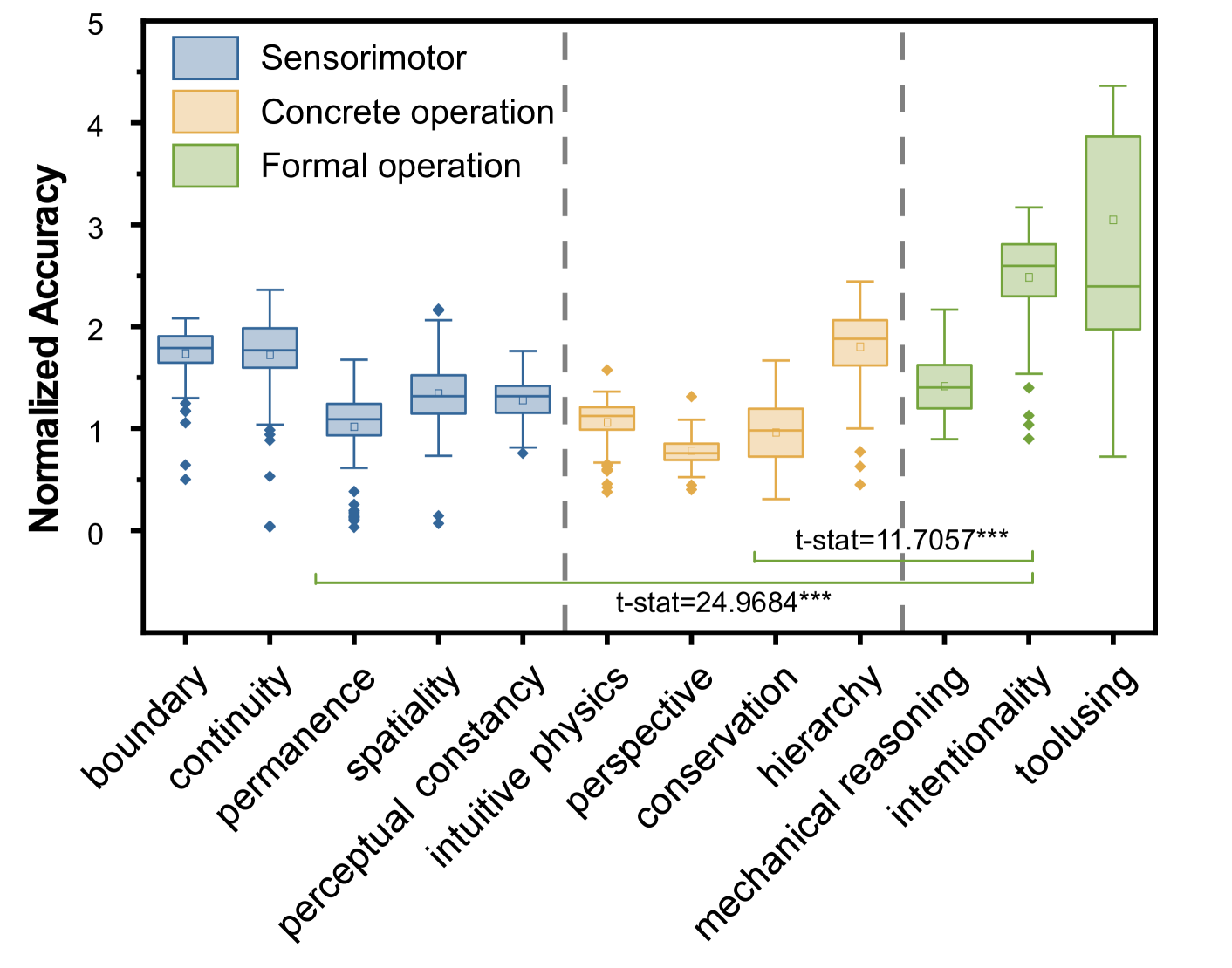
- GPT-o1 achieves 74.91% average accuracy on CoreCognition, significantly trailing human performance by 15.91 percentage points.
- Models demonstrate a 'reversed' capability curve: consistently underperforming on low-level Sensorimotor abilities compared to high-level Formal Operational abilities, whereas humans perform consistently high on both.
- Low-level core abilities exhibit little to no scalability with increased model parameters, unlike high-level abilities which improve with scale.
Breakthrough Assessment
8/10
Provides compelling evidence of a fundamental 'core deficit' in MLLMs using a rigorous cognitive science framework, challenging the assumption that scaling solves basic reasoning.