📊 Experiments & Results
Evaluation Setup
Simulation in Habitat with HM3D scenes. Agents run sequences of 5-10 subtasks.
Benchmarks:
- GOAT-Bench (Multi-Modal Lifelong Navigation) [New]
Metrics:
- Success Rate (SR)
- Success weighted by Path Length (SPL)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison of Modular GOAT vs. RL-based SenseAct-NN Skill Chain on Val Unseen (generalization) and Val Seen datasets. | ||||
| GOAT-Bench (Val Unseen) | Success Rate (SR) | 15.2 | 18.5 | +3.3 |
| GOAT-Bench (Val Unseen) | SPL | 9.4 | 10.1 | +0.7 |
| GOAT-Bench (Val Seen) | SPL | 8.71 | 14.8 | +6.09 |
| Ablation study demonstrating the impact of memory on efficiency (SPL). | ||||
| GOAT-Bench (Val Seen) | SPL | 9.4 | 17.6 | +8.2 |
| GOAT-Bench (Val Seen) | SPL | 9.0 | 9.4 | +0.4 |
Experiment Figures
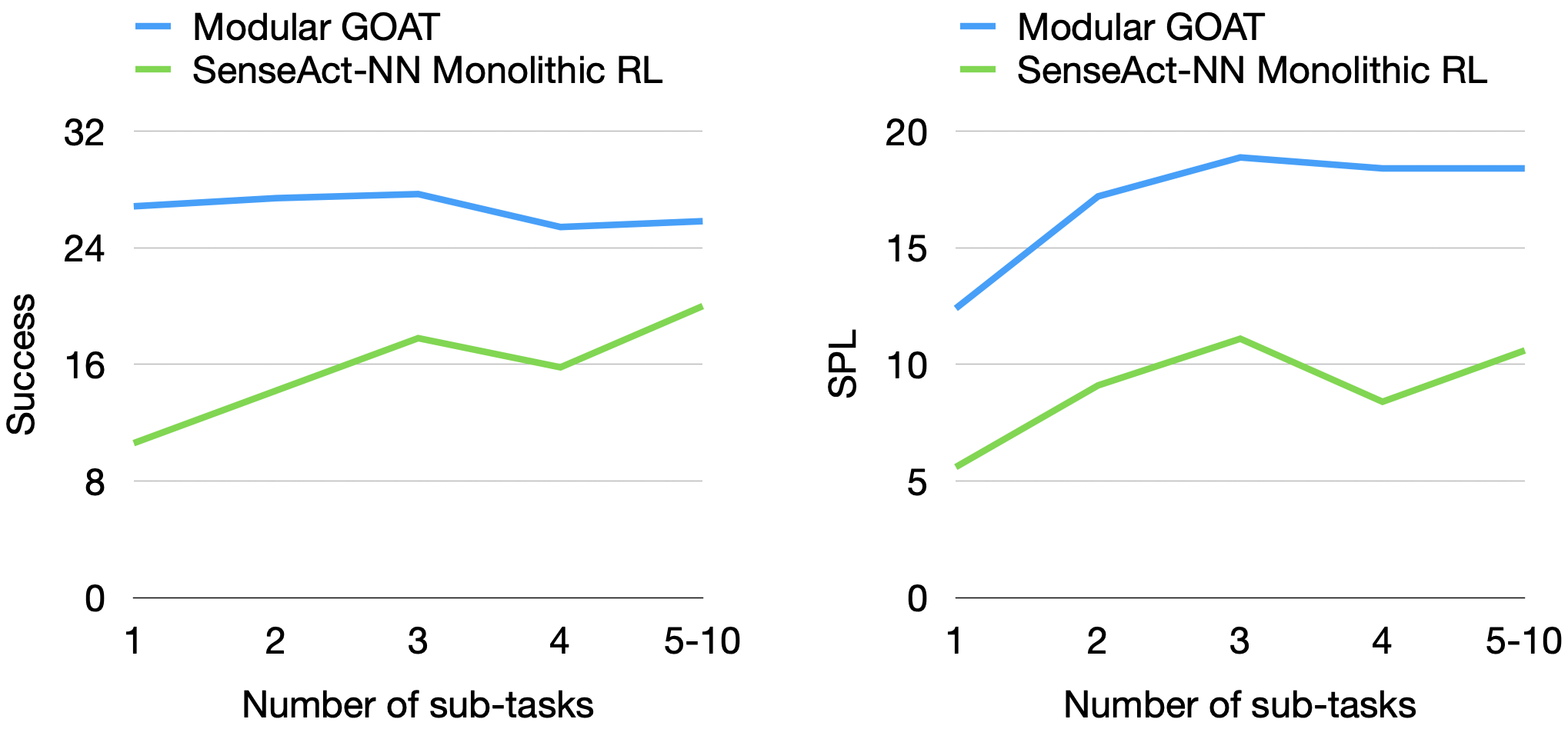
Performance (Success and SPL) as a function of the number of subtasks completed in an episode.
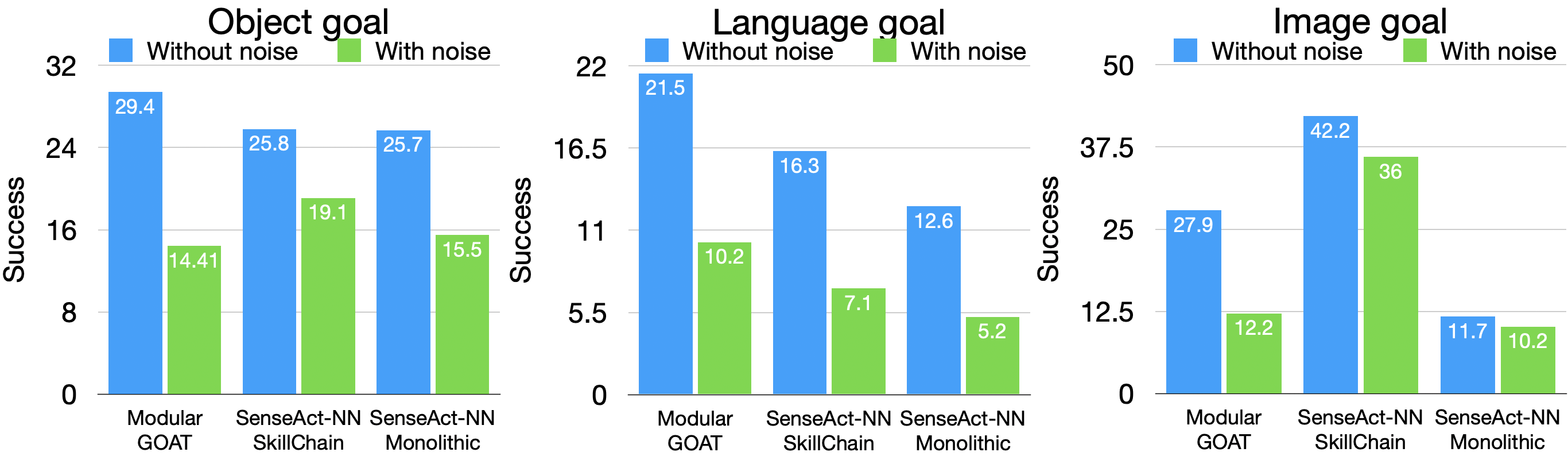
Robustness of methods to noise (Gaussian noise on images, synonyms for categories, paraphrased language).
Main Takeaways
- Modular methods excel at efficiency (SPL) when given explicit memory, improving significantly over the course of an episode as the map is built
- End-to-end RL (SenseAct-NN) generalizes better to unseen object categories (higher Success Rate) and is more robust to input noise, but is highly inefficient
- Current CLIP representations are insufficient for fine-grained instance identification (Language/Image goals), causing low performance on non-category goals
- Instance-specific memory is crucial: Modular GOAT outperforms CLIP-on-Wheels (CoW) by maintaining instance clusters rather than raw feature matching