📝 Paper Summary
Computational Pathology
Foundation Models
Vision-Language Pre-training
PRISM adapts the CoCa framework to pathology by using a Perceiver to aggregate thousands of image tiles into a slide-level embedding aligned with clinical reports, enabling zero-shot diagnosis.
Core Problem
Existing pathology foundation models operate on small image tiles, but clinical diagnosis requires aggregating information across gigapixel Whole Slide Images (WSIs). Supervised aggregators trained from scratch on slide-level labels are prone to overfitting.
Why it matters:
- Most clinical labels (survival, diagnosis) are weak labels associated with the whole slide, not individual tiles
- Training aggregators from scratch requires large labeled datasets, which are scarce for specific tasks like biomarker prediction
- Current methods lack the ability to leverage the rich, unstructured information contained in text-based pathology reports
Concrete Example:
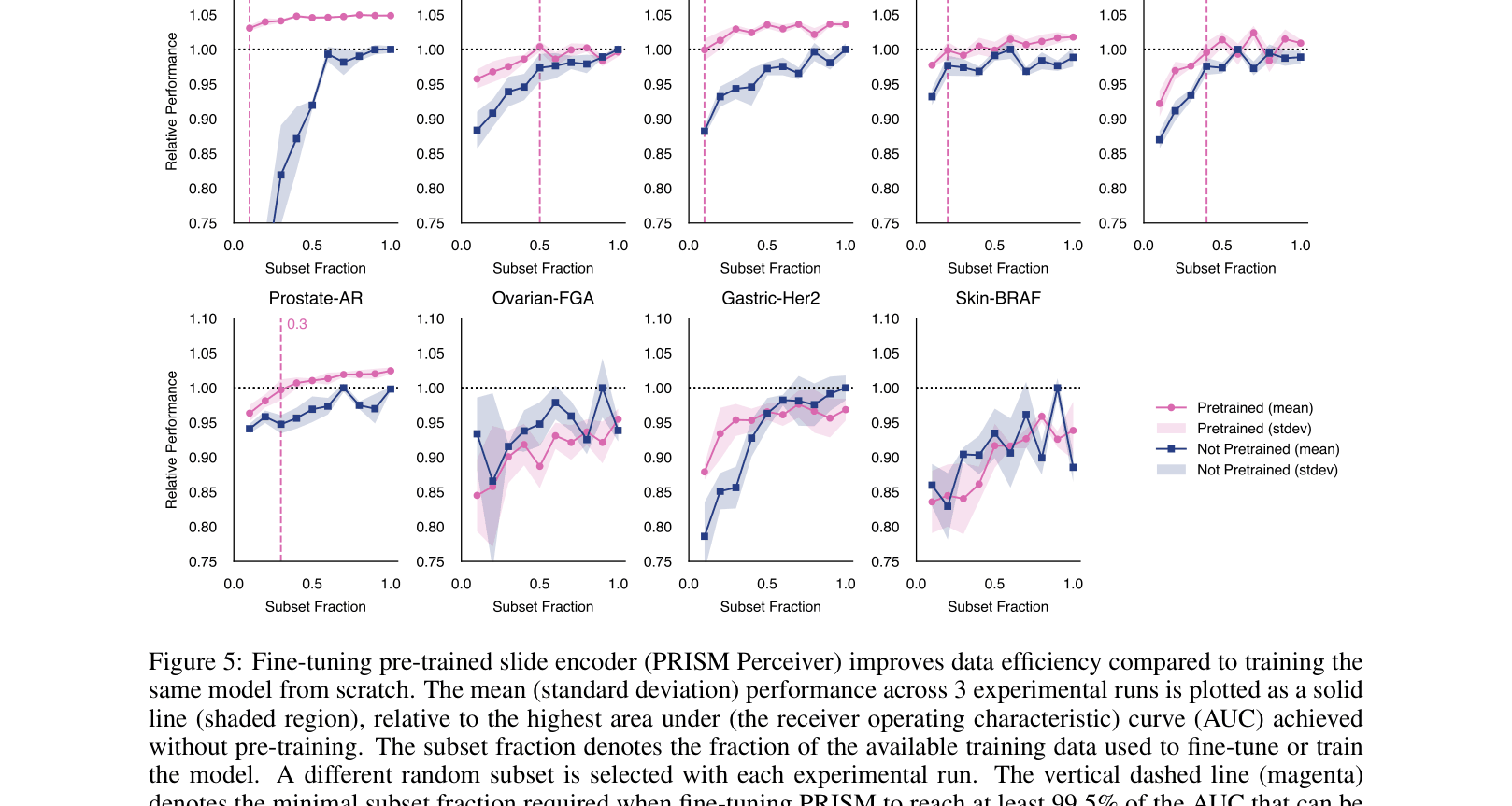
To detect a biomarker like 'Breast-CDH1', a standard approach requires training a MIL (Multiple Instance Learning) network from scratch on thousands of patient slides. With PRISM, the aggregator is pre-trained; fine-tuning it on just 10% of the data yields performance equivalent to training on 100% of the data from scratch.
Key Novelty
Slide-Level Vision-Language Pre-training with Report Summarization
- Adapts the CoCa (Contrastive Captioners) framework to handle gigapixel images by using a Perceiver network to compress thousands of frozen tile embeddings into a small set of latent vectors
- Uses GPT-4 to rewrite and summarize noisy clinical reports into dense, standardized text for effective supervision
- Aligns the entire slide representation with the report text, enabling the model to 'read' the slide and generate diagnostic reports or perform classification without task-specific training
Architecture
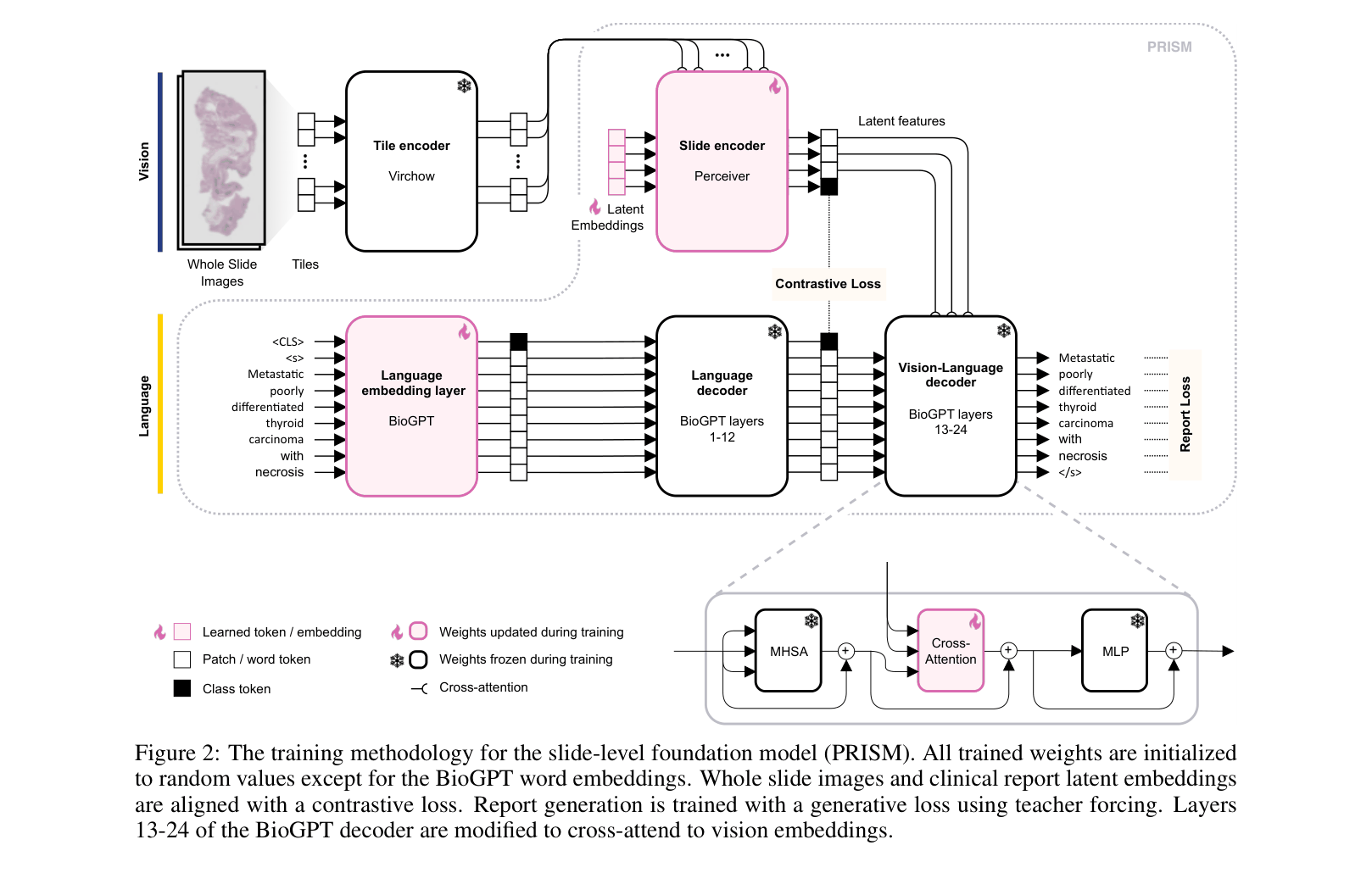
The CoCa-based training framework for PRISM, illustrating how tiles and text are processed and aligned
Evaluation Highlights
- Fine-tuning PRISM on only 10% of training data outperforms a supervised baseline using 100% of data for Breast-CDH1 biomarker prediction
- +3.2% AUC improvement in Zero-shot DCIS (Ductal Carcinoma In Situ) detection compared to a fully supervised baseline trained from scratch
- Achieves 0.983 AUC on NSCLC (Non-Small Cell Lung Cancer) sub-typing via linear probing, surpassing the supervised baseline (0.980 AUC)
Breakthrough Assessment
8/10
Significant advance in scaling foundation models to the slide level. The demonstration of zero-shot diagnostic capabilities and extreme label efficiency for biomarkers addresses major bottlenecks in computational pathology.