📝 Paper Summary
Efficient Multi-Modal LLMs
Video Understanding
Inference Acceleration
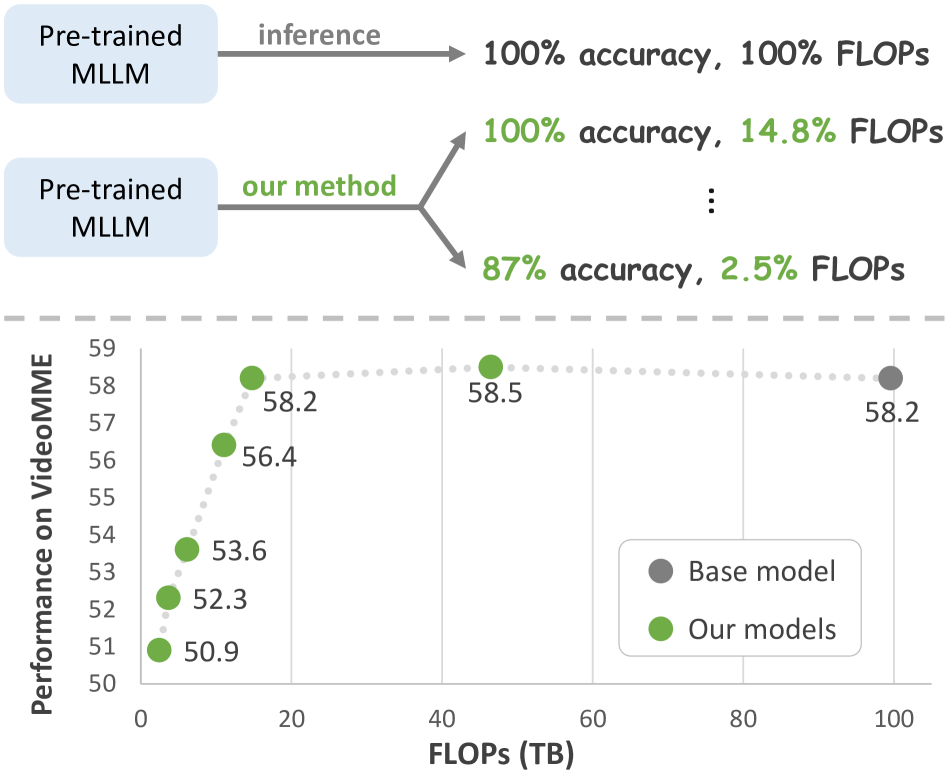
AIM reduces computational costs in multi-modal LLMs by merging similar visual tokens before the model and progressively pruning unimportant ones within the layers, without requiring training.
Core Problem
Multi-modal LLMs, especially for video, process thousands of redundant visual tokens, leading to excessive computational costs and latency that limit deployment and context length.
Why it matters:
- High computational demand restricts the use of powerful MLLMs on resource-constrained edge devices.
- To fit memory constraints, models often sample few frames (e.g., 32) from long videos, causing significant loss of temporal information and reasoning capability.
- Existing pruning methods are often static (pruning at a fixed layer) or require expensive fine-tuning/retraining.
Concrete Example:
A standard video LLM (LLaVA-OV) processing a long video is limited to sampling 32 frames to stay within compute budgets, missing key details. AIM reduces tokens per frame, allowing the model to sample 192 frames within the same FLOPs budget, capturing far more temporal context.
Key Novelty
Adaptive Inference via Token Merging and Pruning (AIM)
- Merges highly similar visual tokens *before* they enter the LLM to immediately reduce sequence length based on cosine similarity.
- Progressively prunes the remaining visual tokens *within* LLM layers using PageRank on attention weights to identify and discard unimportant tokens.
- Decouples text and visual pruning: text tokens are always preserved to maintain reasoning capability, while visual tokens are aggressively reduced.
Architecture
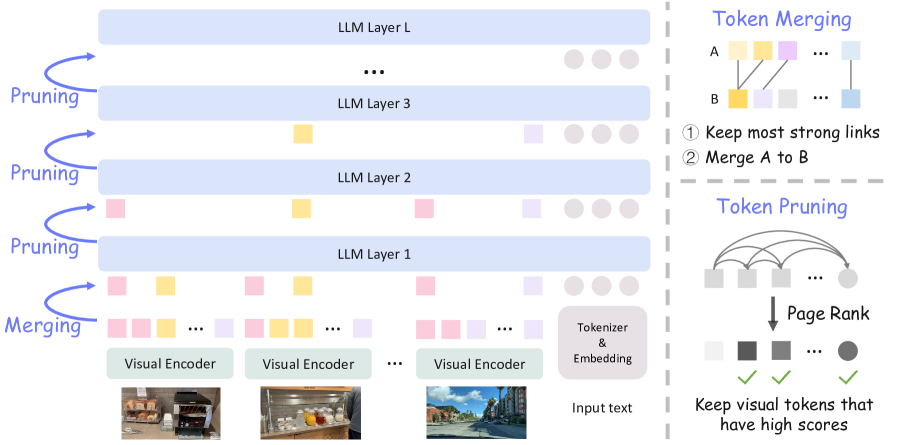
The AIM pipeline illustrating the two-stage token reduction process.
Evaluation Highlights
- Reduces FLOPs by 6.8x and prefill time by 8.0x compared to the LLaVA-OV-7B base model with minimal performance degradation.
- Surpasses the state-of-the-art LLaVA-OV-7B on the MLVU long video benchmark by +4.6 points when utilizing the efficiency gains to process 192 frames instead of 32.
- Outperforms baseline methods like FastV and PDrop while using significantly fewer FLOPs (e.g., requiring only ~69.5% of their compute for comparable accuracy).
Breakthrough Assessment
8/10
Provides a highly effective, training-free solution to a critical bottleneck (visual token redundancy). The ability to improve performance on long videos by trading token density for frame count is a significant practical insight.