📝 Paper Summary
Discrete Diffusion Language Models (dLLM)
Non-Autoregressive Generation
Efficient Large Language Models
LLaDA2.0 successfully converts large-scale pre-trained autoregressive models into efficient 16B and 100B parameter diffusion language models using a progressive block-size training strategy.
Core Problem
Training large-scale diffusion language models (dLLMs) from scratch is prohibitively expensive, but directly converting pre-trained autoregressive (AR) models fails due to the fundamental distribution gap between sequential and bidirectional generation.
Why it matters:
- Autoregressive models suffer from sequential inference bottlenecks, preventing parallel generation and increasing latency at scale.
- Existing diffusion models are limited to small scales (≤8B), failing to match the frontier capabilities of 100B+ AR models.
- Direct conversion without careful handling leads to catastrophic forgetting of the AR model's linguistic knowledge.
Concrete Example:
When directly switching a standard AR model to a diffusion objective, the model often collapses because it cannot handle bidirectional context immediately. Additionally, training on packed sequences causes 'cross-document interference,' where the model confuses contexts from unrelated documents concatenated together.
Key Novelty
Warmup-Stable-Decay (WSD) Continual Pre-training
- Transitions an AR model to a diffusion model by progressively increasing block size: starts with small blocks (Warmup), moves to full-sequence global diffusion (Stable), and reverts to compact blocks for efficient inference (Decay).
- Uses a document-level attention mask to prevent spurious dependencies between unrelated documents in packed training sequences.
- Integrates a confidence-aware loss during post-training to encourage the model to be 'sharper,' enabling more aggressive parallel decoding.
Architecture
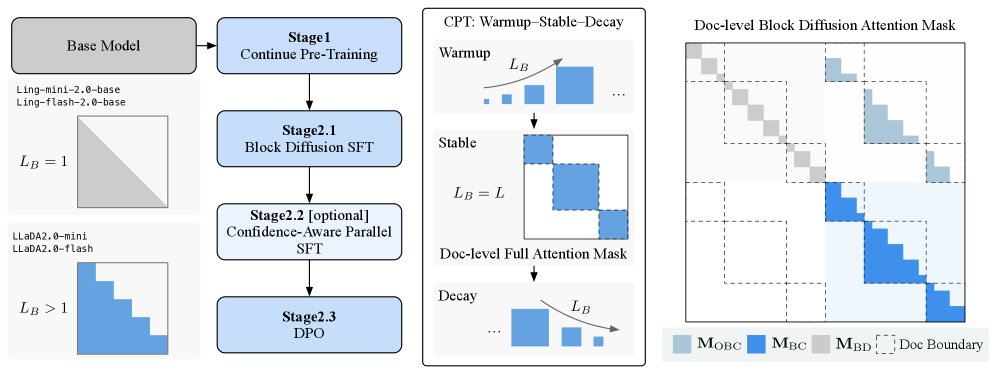
The holistic training pipeline of LLaDA2.0, illustrating the transition from AR to MDLM and then to BDLM.
Evaluation Highlights
- LLaDA2.0-flash (100B) achieves superior performance and efficiency compared to scratch-trained baselines, validating the AR-initialization strategy at scale.
- Inference speedup is achieved via parallel decoding, surpassing equivalently sized AR models in throughput for large batches.
- Post-training with SFT and DPO successfully aligns the diffusion model, yielding the LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B) instruction-tuned variants.
Breakthrough Assessment
9/10
First successful scaling of diffusion language models to the 100B parameter regime, bridging the gap with frontier AR models while enabling parallel decoding.