📝 Paper Summary
3D Scene Understanding
Semi-Supervised Learning
LaserMix++ improves semi-supervised LiDAR segmentation by intertwining laser beams from different scans with corresponding camera features and leveraging language-driven guidance to align spatial and textural priors.
Core Problem
Training effective LiDAR segmentation models requires massive, expensive 3D annotations, and existing semi-supervised methods fail to exploit complementary texture and context from camera images.
Why it matters:
- Manual annotation of dense 3D point clouds is prohibitively expensive and hard to scale for autonomous driving fleets
- Single-modal (LiDAR-only) semi-supervised methods miss robust textural cues available in cameras, limiting performance in complex or low-data scenarios
- Current multi-modal approaches often require full supervision, neglecting the potential of abundant unlabeled data collected by autonomous vehicles
Concrete Example:
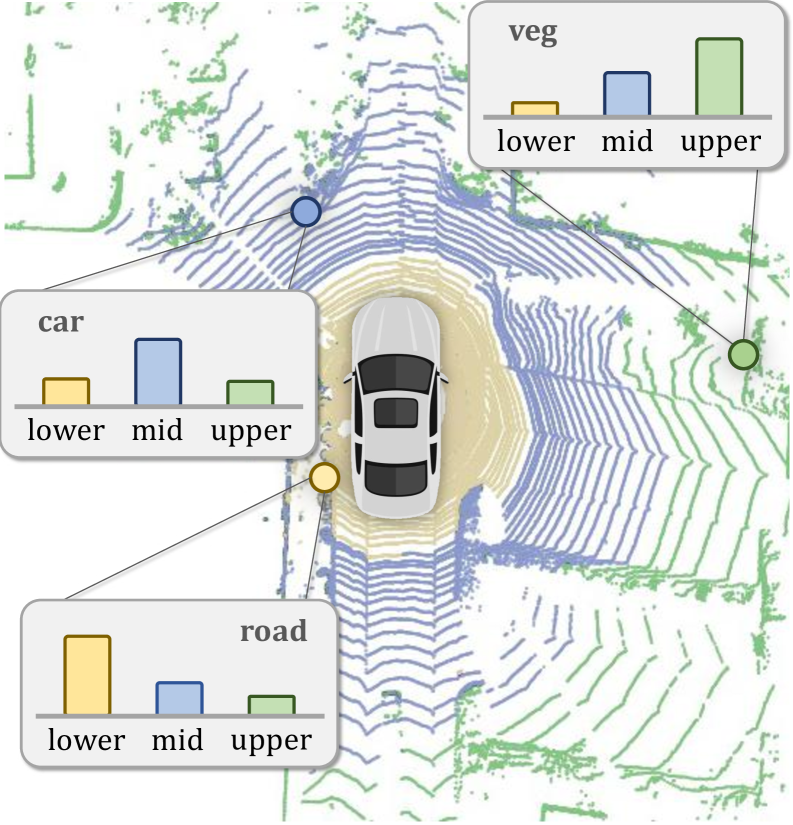
In a driving scene, a LiDAR scan provides precise geometry but sparse texture, making it hard to distinguish a flat sidewalk from a road. A camera image clearly shows the texture difference. LaserMix++ fuses these modalities in a semi-supervised setting to correctly segment the sidewalk without needing full labels.
Key Novelty
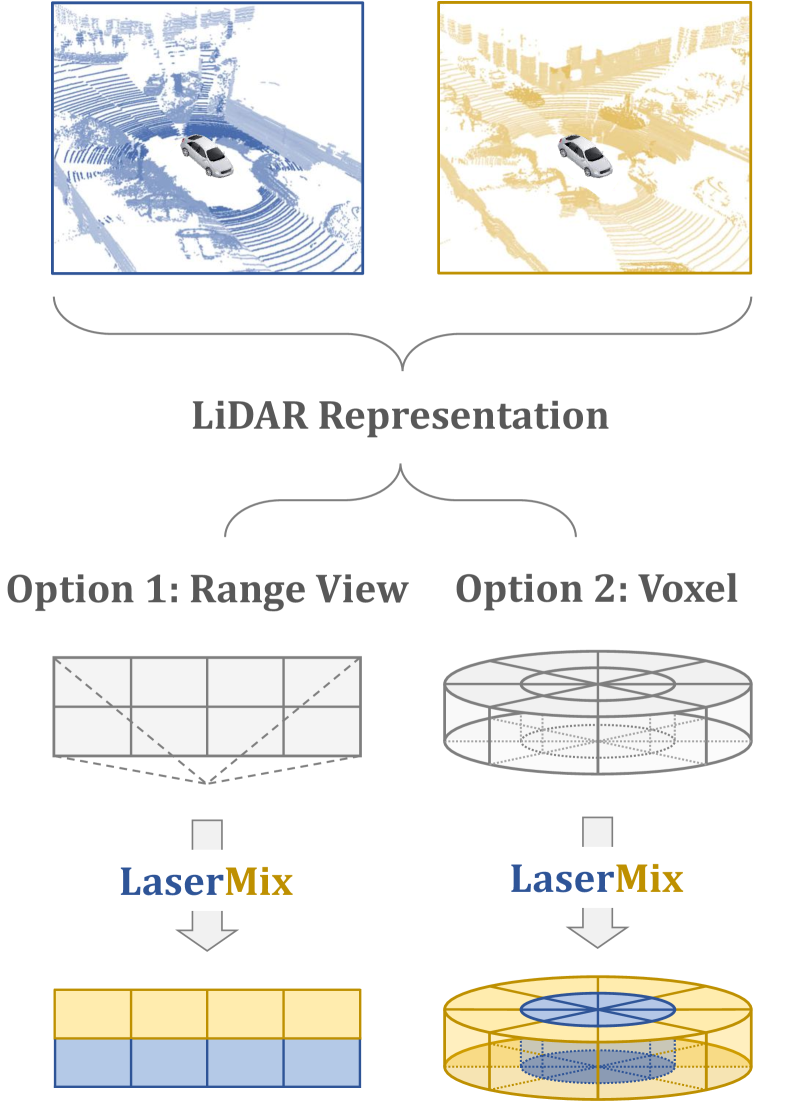
LaserMix++ (Multi-Modal Laser Mixing)
- Extends the LaserMix strategy to mix not just LiDAR beams but also corresponding camera image crops, aligning spatial geometry with 2D texture
- Introduces camera-to-LiDAR feature distillation to transfer rich semantic features from images to the point cloud processing stream
- Utilizes language-driven knowledge guidance (via open-vocabulary models) to generate auxiliary supervision signals for unlabeled data
Architecture
The Data-Efficient 3D Scene Understanding Framework showing the dual-branch Student-Teacher architecture.
Evaluation Highlights
- Achieves comparable accuracy to fully supervised methods while using five times fewer annotations
- Markedly outperforms fully supervised alternatives in low-data regimes
- Significantly improves upon supervised-only baselines by leveraging multi-modal consistency
Breakthrough Assessment
8/10
Significantly advances 3D semi-supervised learning by successfully integrating multi-modal data and language priors, addressing the critical bottleneck of annotation costs in autonomous driving.