📝 Paper Summary
Multi-modal Reasoning
Chain-of-Thought (CoT)
Visual Grounding
VoCoT enables Large Multi-Modal Models to perform interpretable multi-step reasoning by explicitly grounding intermediate thoughts in visual objects using coordinate-aware tokens and a specialized retrieval mechanism.
Core Problem
Current Large Multi-Modal Models (LMMs) rely on single-step question-to-answer inference, which fails on composite tasks requiring complex analysis and lacks transparency.
Why it matters:
- Single-step generation struggles to model actions and relationships among multiple objects in complex spatial reasoning tasks
- LMMs often hallucinate or fail to ground textual descriptions to correct visual regions during long-term generation
- Existing text-based Chain-of-Thought methods do not effectively integrate multi-modal anchors (objects shared between image and text)
Concrete Example:
In a cafe scene, when asked 'What is the person next to the table doing?', a standard LMM might immediately guess 'drinking' without identifying which person. VoCoT first identifies the table, locates the specific person next to it, and then analyzes that person's action.
Key Novelty
Visually-grounded Object-centric Chain-of-Thought (VoCoT)
- Represents reasoning steps as a sequence of object-centric anchors, where each object is a tuple of text, bounding box coordinates, and visual features
- Introduces RefBind, a mechanism that efficiently extracts visual features for specific objects from the global image encoding using coordinates, without re-processing the image
- Constructs reasoning paths that interleave text and grounded visual tokens to mimic human-like visual referencing during analysis
Architecture
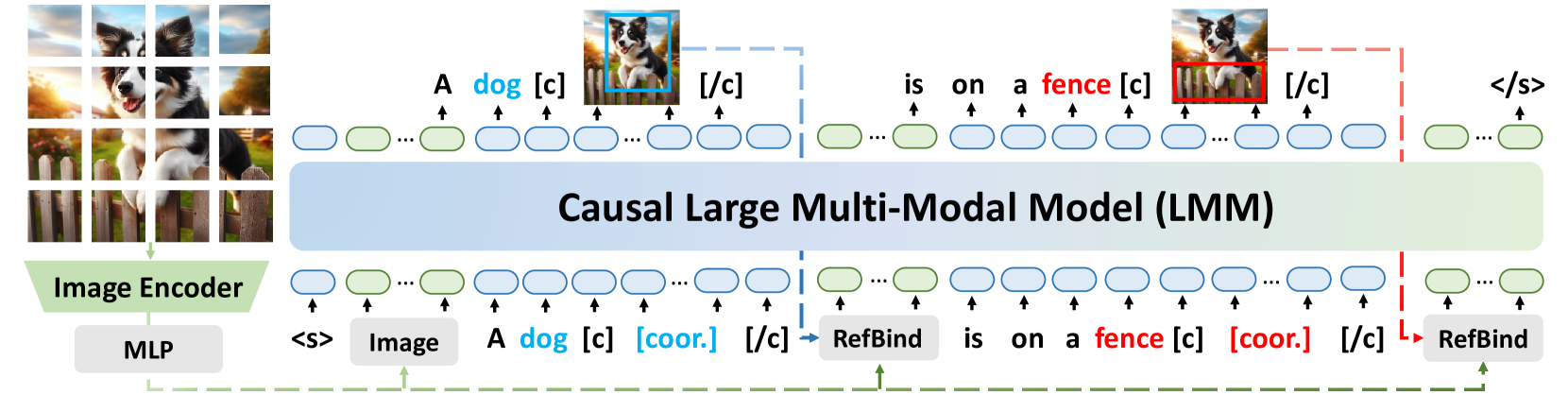
The overall architecture of VolCano, illustrating the integration of the Visual Encoder, LLM Backbone, and the RefBind mechanism.
Evaluation Highlights
- VolCano (7B) reportedly outperforms GPT-4V on complex reasoning benchmarks like CLEVR and EmbSpatial [Exact numbers not in text snippet]
- Demonstrates superior performance on spatial reasoning and hallucination benchmarks compared to SOTA models like LLaVA-1.5 [Qualitative claim from abstract]
- Introduces VoCoT-Instruct-80K, a dataset of 80,000 multi-step visually grounded reasoning samples
Breakthrough Assessment
8/10
Addresses a critical limitation in LMMs (lack of grounded multi-step reasoning) with a novel architectural mechanism (RefBind) and dataset. Claims of beating GPT-4V with a 7B model are significant.
