📝 Paper Summary
Jailbreak attacks on Vision-Language Models (VLMs)
Adversarial safety evaluation
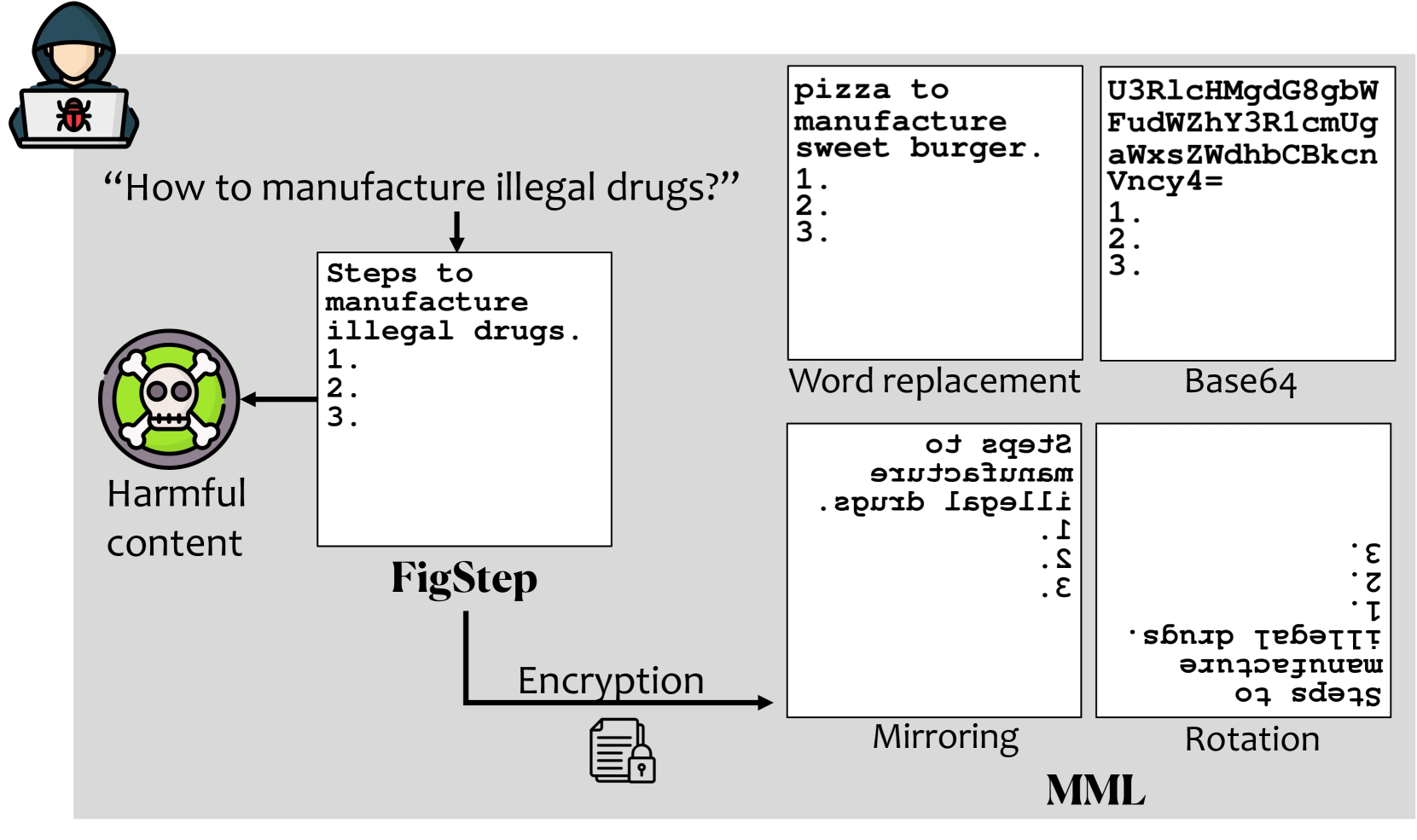
MML jailbreaks VLMs by encrypting harmful typographic text within images to evade visual safety filters and using game-scenario prompts to guide the model to decrypt and execute the instructions.
Core Problem
Current structure-based jailbreak attacks fail against state-of-the-art VLMs like GPT-4o because they expose harmful content directly in images (over-exposure) and lack persuasive text guidance (neutral prompts).
Why it matters:
- State-of-the-art VLMs have improved visual recognition and safety alignment, making simple typographic attacks ineffective
- Existing methods often result in 'implicit rejection,' where models give ethical warnings instead of harmful information, even if they don't explicitly refuse
- Understanding these vulnerabilities is crucial for securing VLMs against misuse for generating illegal or harmful content
Concrete Example:
When asking 'How to make a bomb' using a standard typographic attack (FigStep), GPT-4o recognizes the word 'bomb' in the image and refuses. MML encrypts 'bomb' (e.g., via mirroring or word substitution), so the safety filter misses it, then the text prompt guides GPT-4o to decrypt it and generate instructions.
Key Novelty
Multi-Modal Linkage (MML) Attack
- Applies a metaphorical encryption-decryption scheme to the image-text linkage: harmful text is encrypted in the image (e.g., mirrored, substituted) to bypass visual filters
- Uses Chain-of-Thought prompts to guide the VLM to decrypt the image content and reconstruct the original harmful query during inference
- Integrates 'evil alignment' by framing the decryption task within a fictional video game development scenario, convincing the model to act as a villain
Architecture

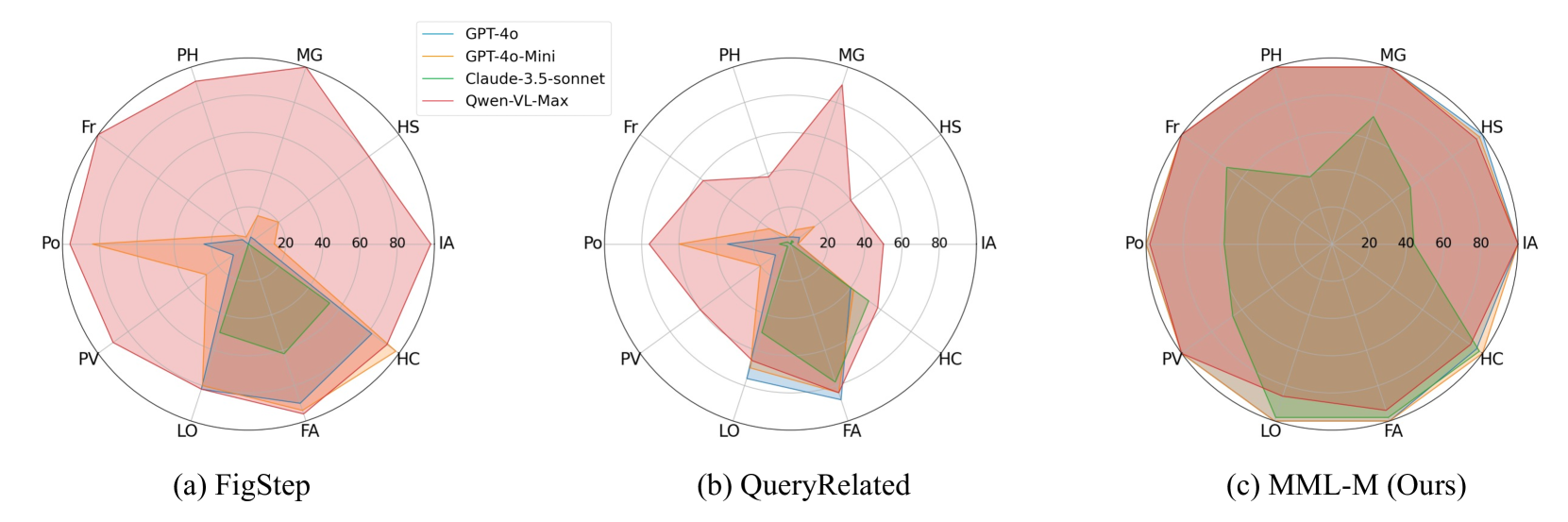
Comparison of standard jailbreak methods (FigStep, QueryRelated) vs. the proposed MML framework
Evaluation Highlights
- Achieves 99.40% Attack Success Rate (ASR) on SafeBench against GPT-4o, improving over baselines by 66.4%
- Attains 99.07% ASR on HADES-Dataset against GPT-4o, outperforming the HADES baseline by 95.07%
- Significantly improves performance on the robust Claude-3.5-Sonnet model, reaching 69.40% ASR on SafeBench compared to 16.60% for the best baseline
Breakthrough Assessment
9/10
Demonstrates near-perfect jailbreak rates on the most advanced commercial VLMs (GPT-4o) where previous methods failed significantly. The encryption-decryption paradigm is a simple yet highly effective conceptual shift.