📝 Paper Summary
Visual Grounding (VG)
Referring Expression Comprehension (REC)
Vision-Language Pre-training (VLP)
SimVG decouples multi-modal fusion from downstream tasks by leveraging a pre-trained multi-modal encoder and a lightweight student branch trained via dynamic distillation, achieving state-of-the-art performance with high efficiency.
Core Problem
Existing methods couple multi-modal fusion with specific downstream tasks using limited data, which underutilizes the potential for deep multi-modal understanding and struggles with complex textual expressions.
Why it matters:
- Models relying on limited downstream data for fusion perform poorly on complex or long sentences
- Complex encoder-decoder architectures increase computational overhead and inference latency
- Independent encoding followed by late fusion underestimates the difficulty of achieving deep mutual understanding between modalities
Concrete Example:
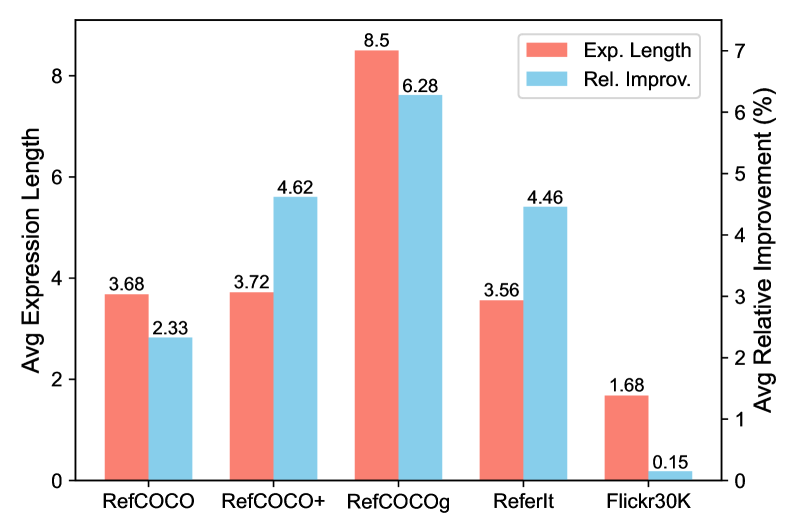
On datasets with long sentence characteristics like RefCOCOg, traditional methods that fuse modalities only during the downstream task struggle to align complex text with image regions, whereas decoupling fusion (using pre-trained multi-modal encoders) significantly boosts performance.
Key Novelty
Decoupled Multi-modal Fusion with Dynamic Distillation
- Use a unified pre-trained encoder (BEiT-3) to handle heavy multi-modal interaction, allowing the downstream model to be lightweight
- Introduce a 'Token Branch' (simple MLP) that learns from a 'Decoder Branch' (Transformer) via a novel dynamic distillation process, enabling fast inference without the heavy decoder
- Dynamic Weight-Balance Distillation (DWBD) shifts guidance from ground truth to teacher predictions as training progresses
Architecture
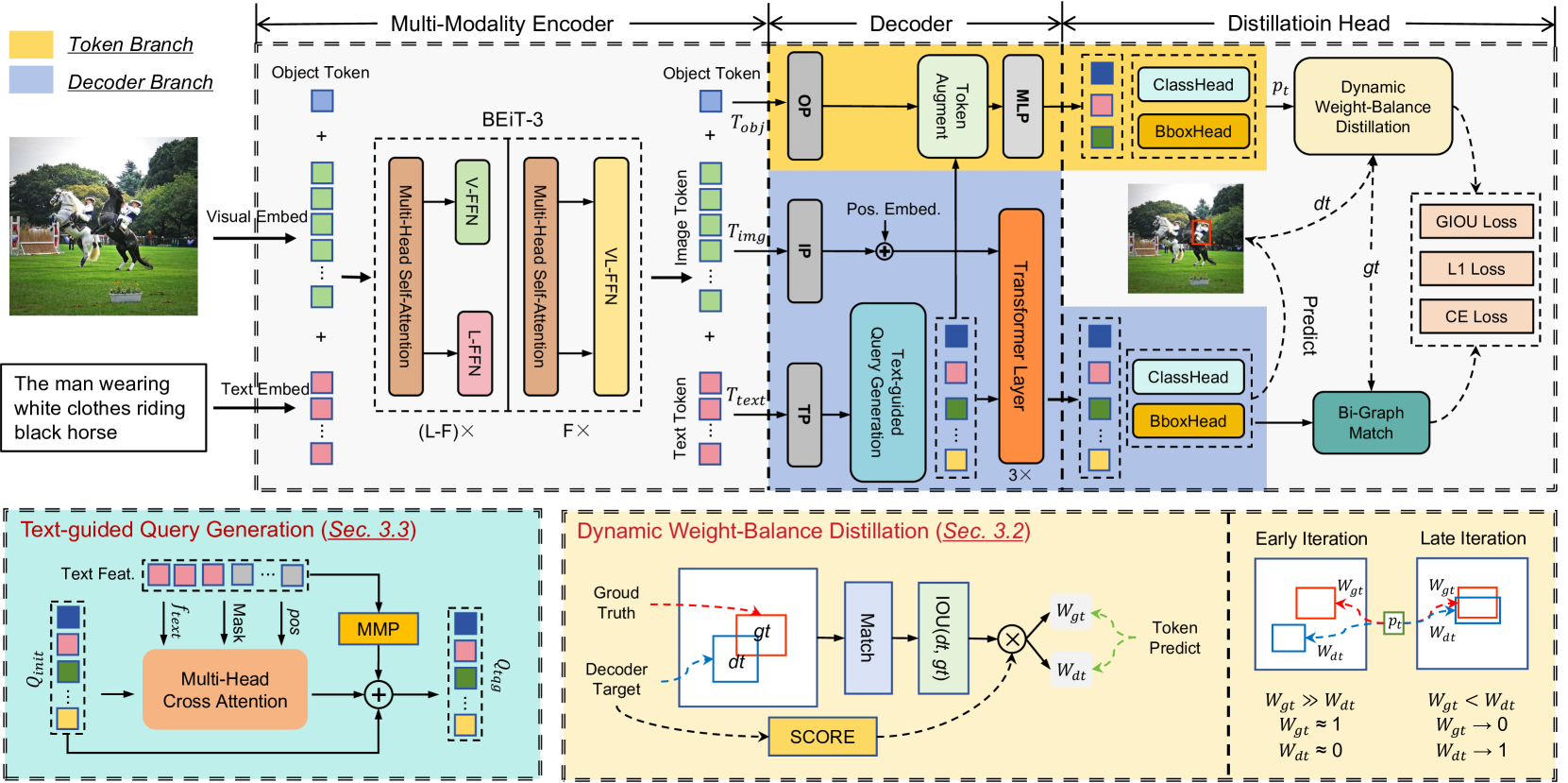
The overall architecture of SimVG, including the Multi-Modality Encoder, the dual-branch design (Decoder Branch vs. Token Branch), and the Text-Guided Query Generation (TQG) and Dynamic Weight-Balance Distillation (DWBD) modules.
Evaluation Highlights
- Achieves state-of-the-art 94.46% accuracy on RefCOCO (testA) using ViT-L/14, surpassing existing methods like VG-Diff and SeqTR
- Trains in just 12 hours on a single RTX 3090 GPU (ViT-B/32) for RefCOCO/+/g, showing high efficiency
- Significant improvements on long-text datasets: +2.16% on RefCOCOg-val compared to Dynamic MDETR
Breakthrough Assessment
8/10
Strongly simplifies the visual grounding pipeline while achieving SOTA results. The shift to decoupled fusion and the specific dynamic distillation strategy offers a practical, efficient alternative to complex DETR-like architectures.