📝 Paper Summary
Remote Sensing Foundation Models
Multi-modal Representation Learning
Earth Observation
SkySense is a billion-scale remote sensing foundation model that integrates multi-modal data, temporal sequences, and geo-contextual prototypes to achieve state-of-the-art performance across diverse Earth Observation tasks.
Core Problem
Existing Remote Sensing Foundation Models (RSFMs) typically focus on single modalities or static images, neglecting the crucial temporal dynamics and region-specific geo-contexts inherent in Earth Observation data.
Why it matters:
- Earth Observation relies on diverse data types (optical, SAR) that complement each other (e.g., SAR sees through clouds), but most models only use one.
- Remote sensing data is strongly dependent on space-time coordinates (seasonality, regional landscapes), yet current models often ignore this rich contextual metadata.
- Building task-specific models for every EO application (crop monitoring, disaster management) is resource-intensive, necessitating a generic model that generalizes well.
Concrete Example:
A standard foundation model might fail to distinguish a specific crop type because it lacks temporal growth data or treats the crop identically across different climate zones. SkySense uses time-series input and region-aware prototypes to capture these phenological and geographical differences.
Key Novelty
Factorized Spatiotemporal Encoding with Geo-Contextual Prototypes
- Uses a modular factorized encoder that processes spatial features of aligned multi-modal images (Optical, SAR) independently before fusing them, enabling flexible handling of single or multi-modal inputs.
- Introduces Geo-Context Prototype Learning, which clusters image features by geographic region to learn 'standard' representations (prototypes) of local semantics (e.g., 'tropical forest' vs 'boreal forest') without explicit labels.
- Employs Multi-Granularity Contrastive Learning to align features at pixel, object, and image levels simultaneously, ensuring representations are useful for diverse downstream tasks from segmentation to classification.
Architecture
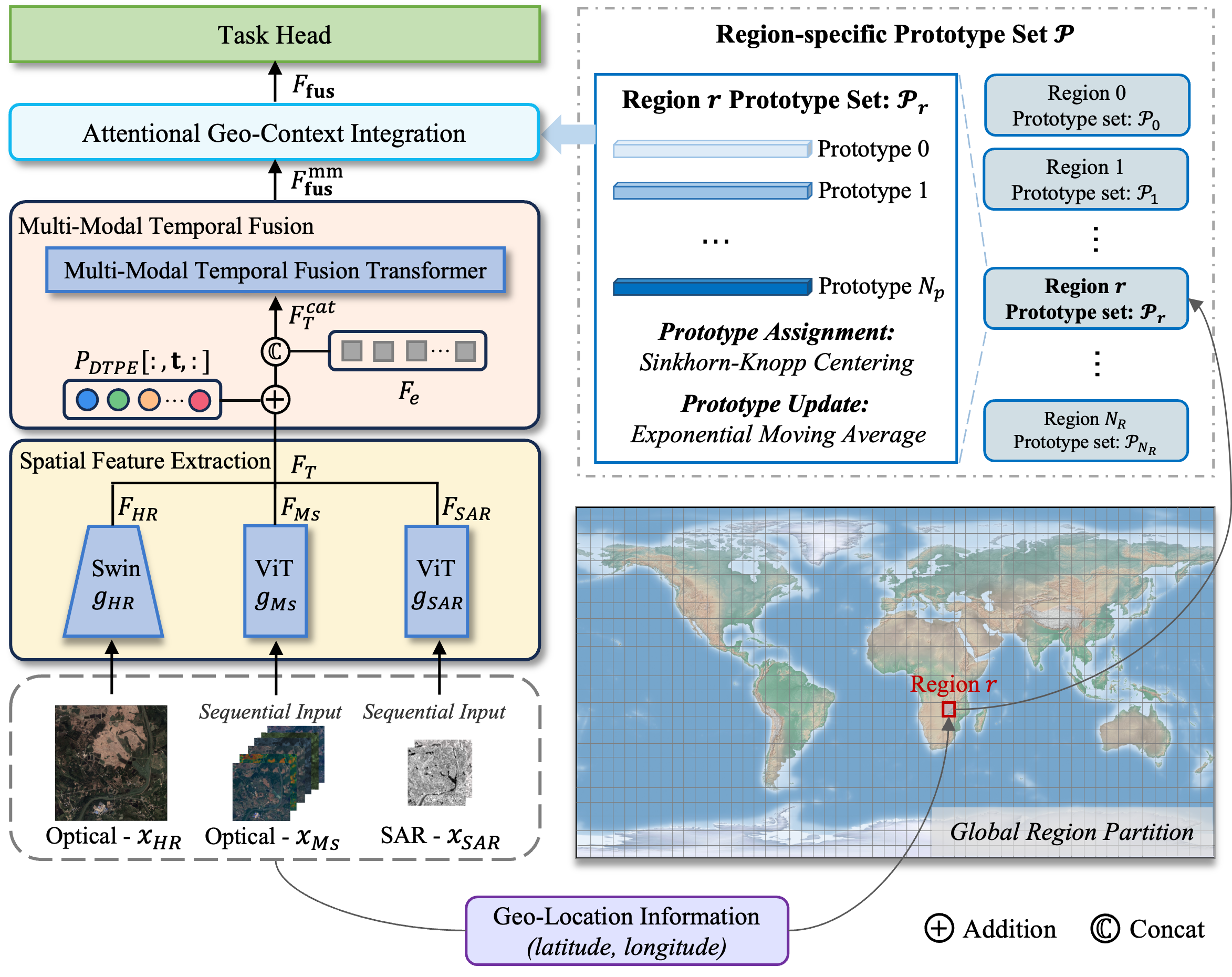
The overall architecture of SkySense, detailing the factorized encoder and geo-context learning modules.
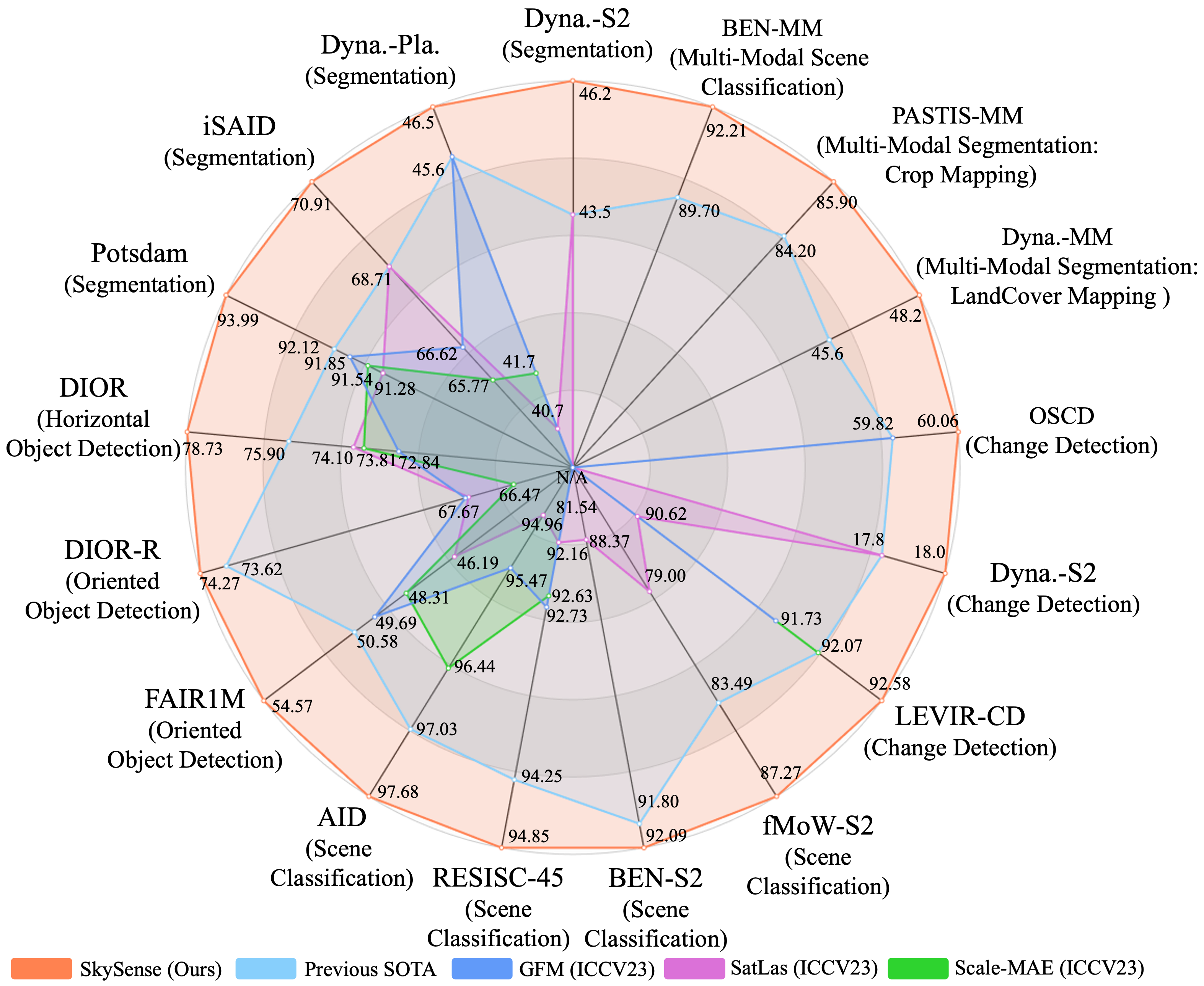
Evaluation Highlights
- Outperforms the Scale-MAE foundation model by +3.61% on average across 16 datasets.
- Surpasses the multi-modal SatLas model by +3.67% average accuracy across 7 tasks.
- Achieves State-of-the-Art performance on all 16 tested datasets, covering modalities from single-modal static to multi-modal temporal.
Breakthrough Assessment
9/10
SkySense sets a new standard for RSFMs by successfully integrating multi-modality, temporal sequences, and geo-context at a billion-parameter scale, consistently beating 18 recent baselines across all tested scenarios.