📝 Paper Summary
Vision-Language Models (VLMs)
Instruction Tuning
In-Context Learning
MIMIC-IT is a large-scale dataset of 2.8 million multi-modal instruction-response pairs designed to train vision-language models to perceive, reason, and plan using images and videos as context.
Core Problem
Existing vision-language instruction datasets are limited in visual diversity (mostly single images like COCO), lack video support, and rely solely on language for in-context information rather than multi-modal context.
Why it matters:
- Current assistants fail when users provide multiple images or videos as context (e.g., 'compare these two photos')
- Zero-shot generalization requires diverse, high-quality instructions that mirror real-world visual complexity beyond simple object recognition
- Models need to understand context (user intent, tone, style) through visual examples, not just text descriptions
Concrete Example:
In LLaVA-Instruct, a model only sees one image and text examples. In MIMIC-IT, a user can upload two images and ask 'What is the difference between these two images?' or provide a video clip and ask 'Is it safe to walk on the floor while the woman is cleaning?' requiring temporal and comparative reasoning.
Key Novelty
Multi-Modal In-Context Instruction Tuning (MIMIC-IT)
- Introduces multi-modal in-context examples: instead of just text Q&A examples, the model receives context consisting of images/videos + text pairs to learn the task pattern
- Syphus: An automated pipeline using ChatGPT to generate instruction-response pairs based on visual annotations (bounding boxes, captions) and system messages defining tone/style
- Supports arbitrary visual inputs (multiple images or video clips) within a single instruction cycle, enabling tasks like 'spot the difference' or egocentric video planning
Architecture
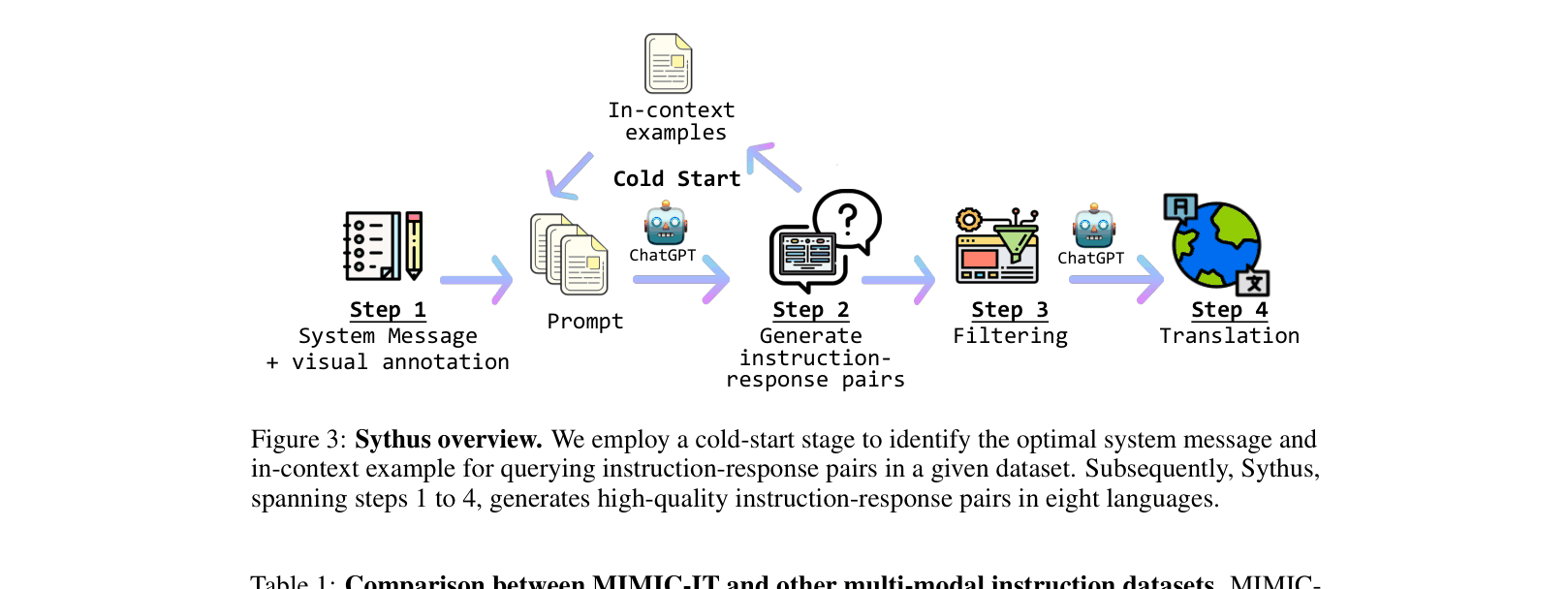
The Syphus automated instruction generation pipeline
Evaluation Highlights
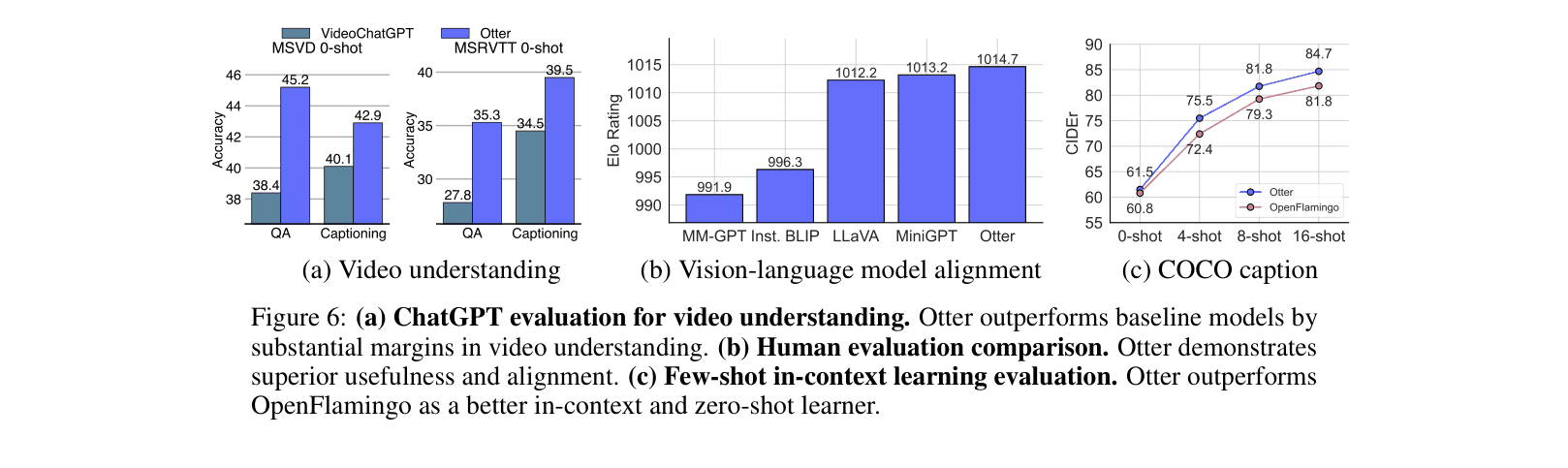
- Otter model achieves highest Elo rating (1014.7) on Multi-Modality Arena, outperforming LLaVA and OpenFlamingo in human evaluation
- +6.8% accuracy improvement over VideoChatGPT on MSVD zero-shot video question answering
- Superior few-shot learning: Otter outperforms OpenFlamingo by ~14 CIDEr points on COCO captions in the 4-shot setting
Breakthrough Assessment
9/10
Significant scale-up (2.8M pairs) and structural innovation (multi-modal in-context). Addresses key gaps in video/multi-image understanding. Performance gains are substantial across diverse benchmarks.