📝 Paper Summary
Multi-modal Large Language Models (MLLMs)
Visual Instruction Tuning
SPHINX enhances multi-modal LLMs by unfreezing the LLM during pre-training, mixing model weights from different data domains, aggregating diverse visual encoders, and processing high-resolution sub-images.
Core Problem
Existing MLLMs struggle with limited visual resolution (typically 224x224), domain conflict between synthetic and real-world training data, and lack of fine-grained visual perception due to frozen LLM weights or single-purpose tuning.
Why it matters:
- Low resolution hinders fine-grained tasks like reading text in documents or detecting small objects
- Frozen LLMs limit the potential for deep cross-modal alignment during pre-training
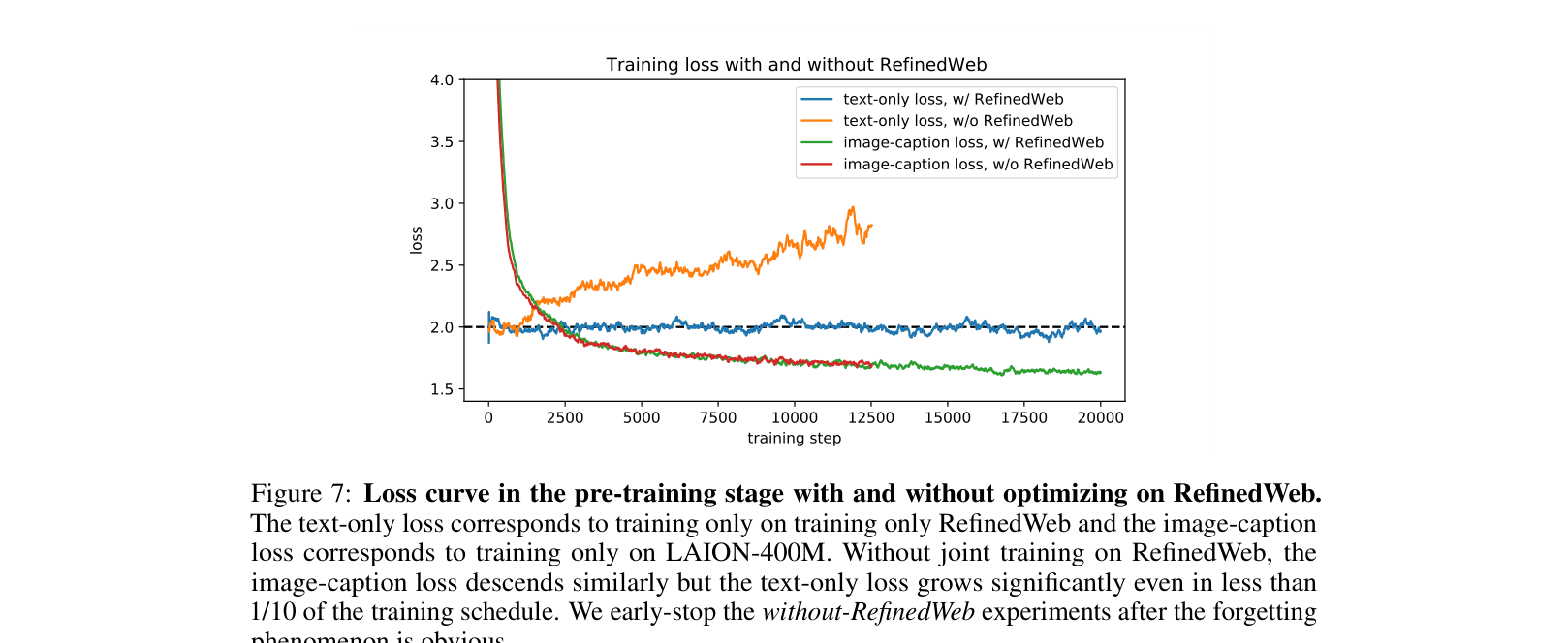
- Training on purely synthetic data can degrade real-world performance, but mixing datasets naively confuses the model
Concrete Example:
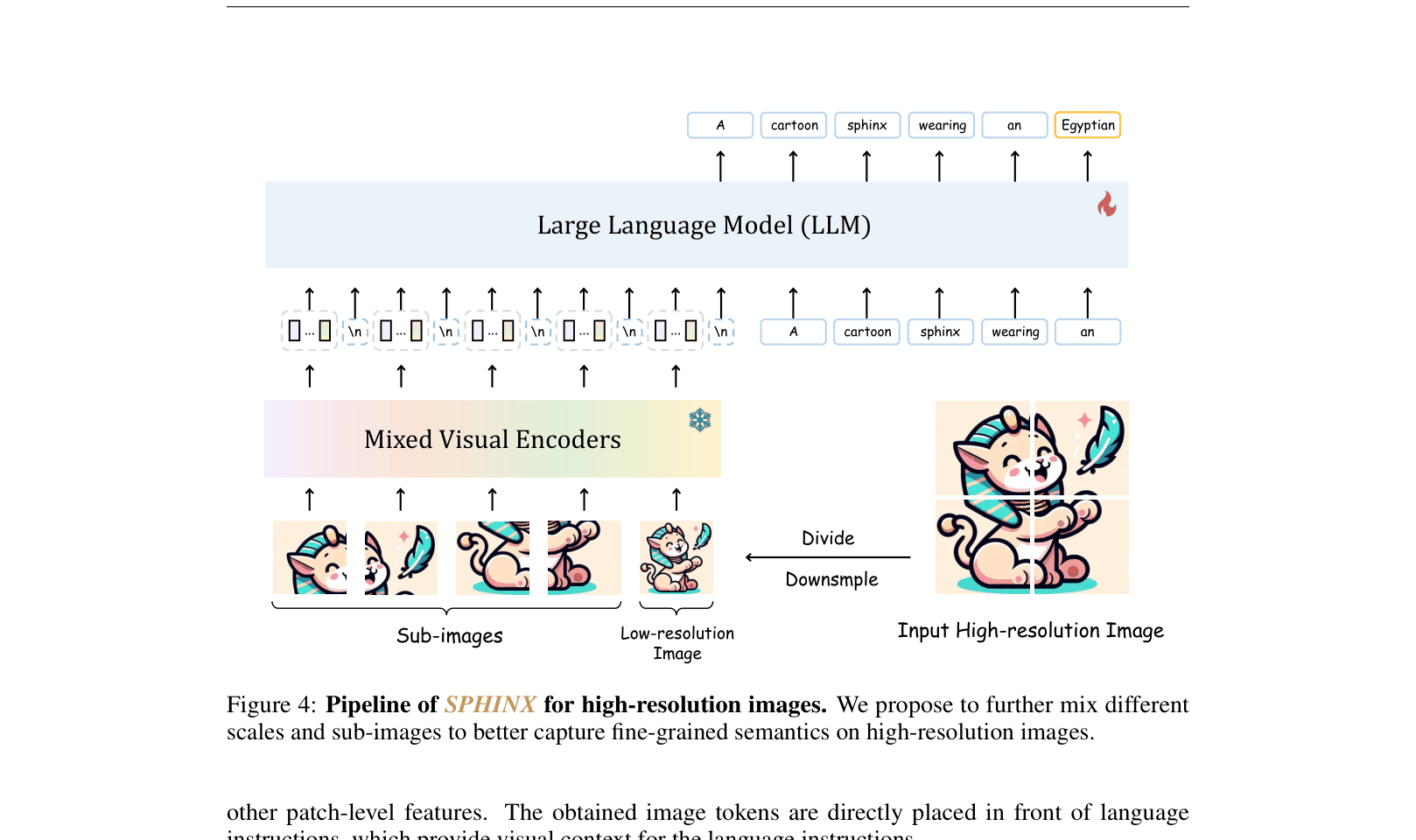
When asked to detect small objects or read dense text in a 448x448 image, standard MLLMs downsample it to 224x224, losing detail. SPHINX splits the image into four 224x224 corners plus a downsampled global view, allowing the LLM to 'see' the fine details.
Key Novelty
Three-fold Mixing Strategy (Weights, Tasks, Embeddings) + High-Res Sub-Image Processing
- Mixes model weights by linearly combining an LLM tuned on real-world data with one tuned on synthetic data to capture diverse semantics without data conflict
- Mixes visual embeddings from multiple encoders (CNN, ViT, Q-Former) to combine local, global, and patch-level features
- Processes high-resolution images by cropping them into sub-images (e.g., 4 corners) and feeding them as a sequence of independent visual tokens to the LLM
Architecture
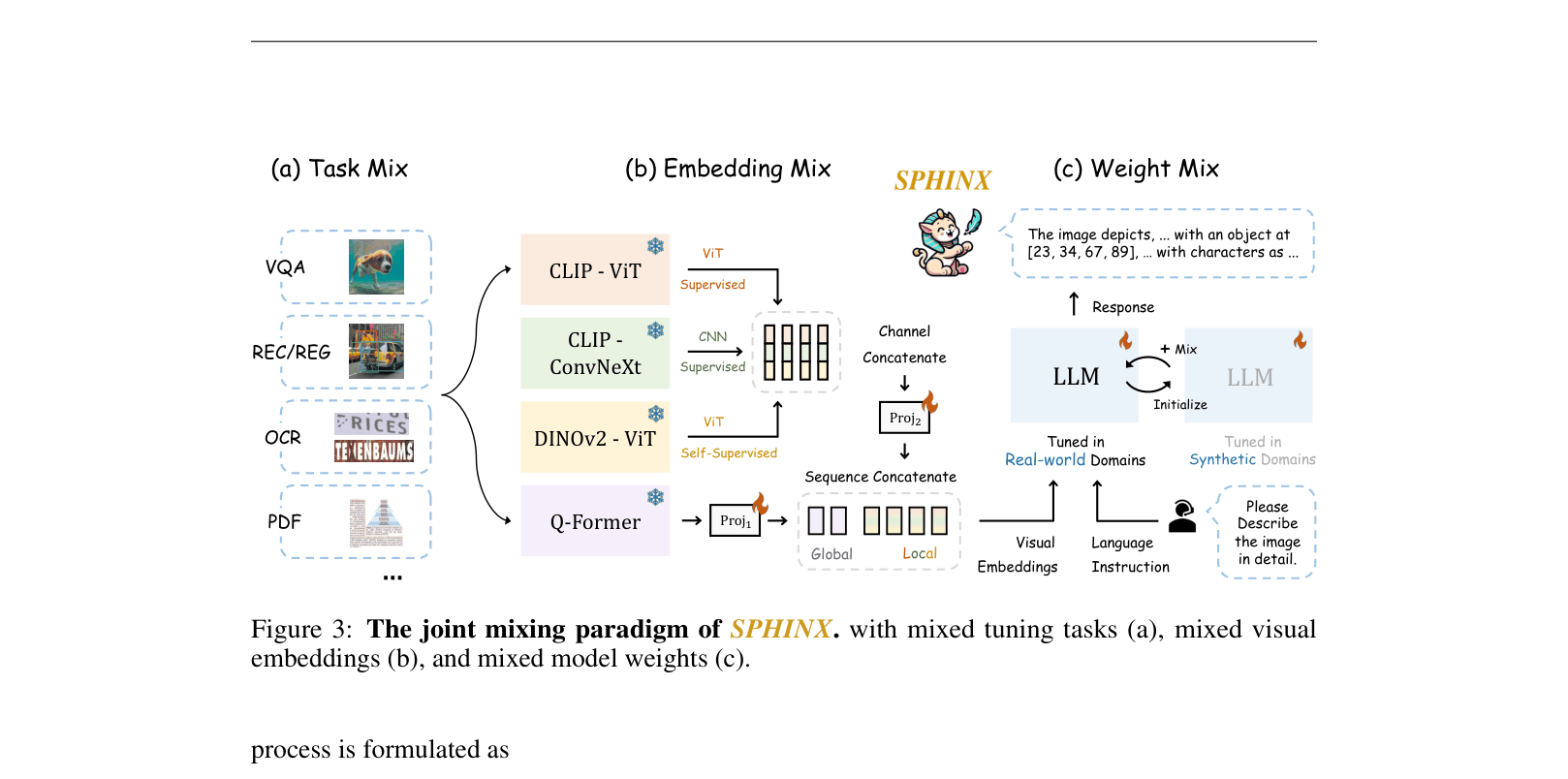
The joint mixing paradigm including task mixing, embedding mixing (from CLIP-ViT, ConvNeXt, DINOv2, Q-Former), and weight mixing.
Evaluation Highlights
- Achieves 90.8 POPE score (SPHINX-1k), surpassing LLaVA-1.5-13B (85.9) and InstructBLIP-13B (78.9)
- Reaches 80.2% accuracy on VQA v2 (SPHINX-1k), outperforming Qwen-VL-7B (79.5%) and LLaVA-1.5-13B (80.0%)
- Attains 91.08% accuracy on RefCOCO test-A (SPHINX-1k), outperforming specialist model G-DINO-L (88.95%) and generalist Qwen-VL-7B (88.25%)
Breakthrough Assessment
8/10
Significant engineering breakthrough in handling high-resolution inputs via sub-image sequences without expensive architectural changes. Strong performance across diverse benchmarks confirms the effectiveness of the 'mixing' paradigm.