📝 Paper Summary
Autonomous Driving
Multimodal Large Language Models (MLLMs)
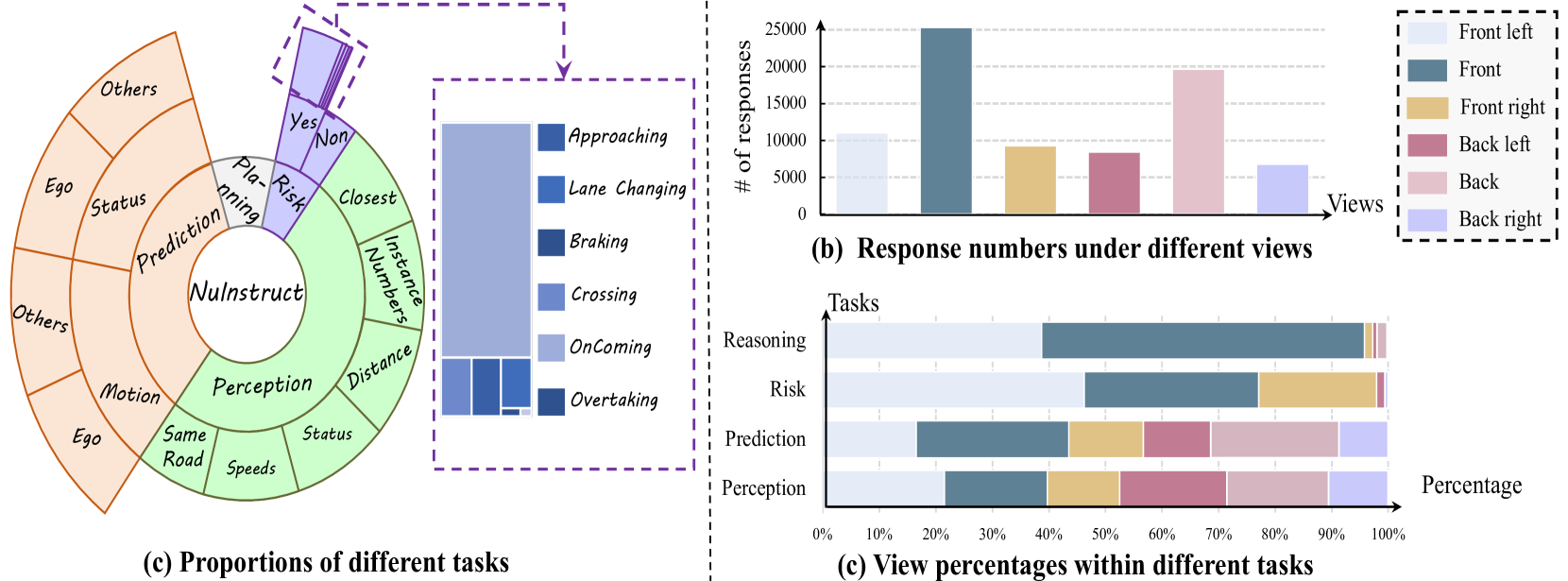
NuInstruct is a large-scale multi-view driving dataset created via SQL-based generation, paired with BEV-InMLLM, a model that injects Bird's-Eye-View features into MLLMs for holistic spatial-temporal understanding.
Core Problem
Existing language-based driving research relies on limited single-view data and lacks the holistic information (multi-view, temporal, spatial) required for safe autonomous driving decisions.
Why it matters:
- Current benchmarks only cover subsets of driving tasks (e.g., perception only), failing to model the interdependent chain of perception, prediction, and planning
- Single-view models suffer from occlusions and lack spatial awareness (e.g., ignoring overtaking vehicles on the side), which is critical for safety
- Standard MLLMs struggle with spatial tasks like distance estimation because their visual encoders (ViTs) are not designed for precise geometric understanding
Concrete Example:
A model focusing only on the front view might fail to predict a collision because it neglects an overtaking vehicle in the left blind spot, a scenario common in driving but missing from single-view datasets.
Key Novelty
SQL-based Instruction Generation & BEV Feature Injection
- Generates 91K instruction-response pairs by querying a structured database of driving scenes with SQL, ensuring logical consistency across Perception, Prediction, Risk, and Planning tasks
- Proposes BEV-InMLLM, which fuses standard video features with Bird's-Eye-View (BEV) features using a specialized injection module, providing the LLM with explicit spatial and geometric cues
Architecture
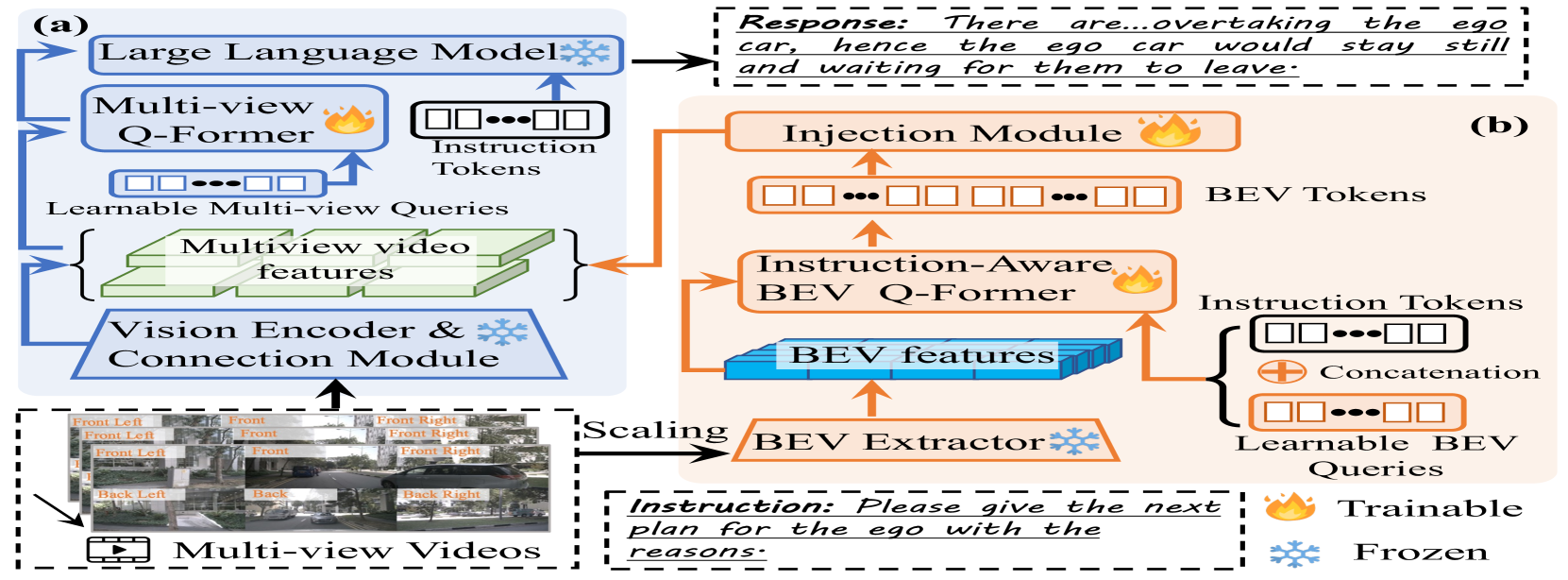
Comparison between the baseline Multi-view MLLM (MV-MLLM) and the proposed BEV-InMLLM architecture.
Evaluation Highlights
- BEV-InMLLM achieves ~9% improvement over state-of-the-art baselines on various NuInstruct tasks
- Outperforms the MV-MLLM baseline on distance estimation (MAE reduced from 5.3 to 3.6) and speed estimation (MAE reduced from 3.9 to 3.2)
- Significantly improves planning with reasoning capabilities, raising BLEU scores from 22.7 (MV-MLLM) to 25.1 (BEV-InMLLM)
Breakthrough Assessment
8/10
Introduces a highly scalable, logically grounded method for generating driving instruction data and successfully integrates BEV representations into MLLMs, addressing a key limitation in spatial reasoning for autonomous driving.