📝 Paper Summary
Document Visual Question Answering (DocVQA)
Multi-modal Retrieval-Augmented Generation (RAG)
M3DocRAG is a framework that retrieves document pages as images using visual embeddings (ColPali) and answers questions via multi-modal language models, enabling reasoning over visual elements like charts without OCR.
Core Problem
Existing DocVQA methods either rely on OCR (which loses visual information like charts and layouts) or are limited to single-page processing, failing to handle questions requiring information across multiple long documents.
Why it matters:
- Real-world documents in finance and law contain critical information in tables and mixed layouts that OCR-based text extraction frequently corrupts or ignores
- Users need answers from large corpora (open-domain), but current visual models cannot process thousands of pages at once due to context limits
- Standard RAG pipelines sever the link between text and its visual layout, leading to incomplete or inaccurate interpretations
Concrete Example:
When asking 'What is the trend in the sales chart?', an OCR-based RAG system fails because it extracts only text and ignores the chart pixels. M3DocRAG retrieves the actual image of the page containing the chart, allowing the multi-modal model to 'see' and interpret the trend.
Key Novelty
Visual-Centric Retrieval-Augmented Generation
- Treats every document page as an image rather than text, encoding them into visual embeddings using ColPali to preserve layout and graphical information
- Performs retrieval in the visual space (matching query text to page images) and feeds the top retrieved page images directly to a Multi-Modal Language Model (MLM) for answering
Architecture
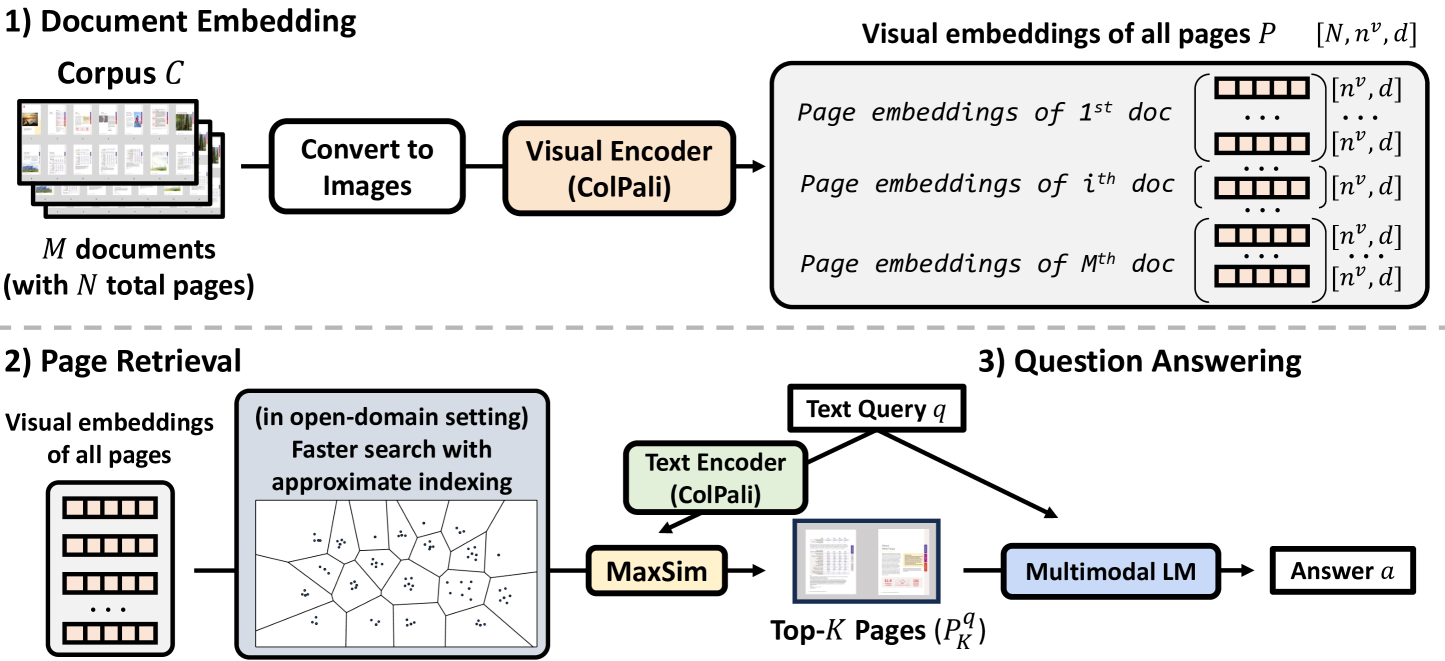
The M3DocRAG framework pipeline across three stages: Document Embedding, Page Retrieval, and Question Answering.
Evaluation Highlights
- Reduces page retrieval latency from 20s/query to less than 2s/query using Inverted File Index (IVF) for open-domain search over 40K pages
- Achieves state-of-the-art performance on the MP-DocVQA benchmark using ColPali and Qwen2-VL 7B (specific scores not in snippet)
- Demonstrates superior performance over strong baselines on the newly introduced M3DocVQA open-domain benchmark (specific scores not in snippet)
Breakthrough Assessment
8/10
Significantly shifts the paradigm from text-based RAG to visual RAG for documents, addressing the long-standing bottleneck of OCR quality in document understanding.