📝 Paper Summary
Visual Hallucination in Multi-modal LLMs
Benchmark Creation
Adversarial Testing
VHTest generates challenging visual hallucination instances by identifying confusing image pairs in existing datasets, creating text descriptions of failure modes, and generating new adversarial images via DALL-E 3.
Core Problem
Existing benchmarks for multi-modal LLM hallucinations rely on static datasets like COCO, which limits diversity and risks data contamination (since models may have trained on them).
Why it matters:
- Limited diversity in existing datasets leads to a biased understanding, often overestimating MLLM performance
- Data contamination prevents accurate assessment of how models handle truly unseen or challenging visual scenarios
- Visual hallucinations in critical applications (like autonomous systems) pose safety risks, necessitating rigorous adversarial testing
Concrete Example:
An image contains three lamps. An MLLM (like GPT-4V) incorrectly states there are two lamps. This simple counting failure highlights the model's inability to ground text generation in visual facts, even for basic objects.
Key Novelty
Adversarial Generation via CLIP/DINO Discrepancy & Text-to-Image Synthesis (VHTest)
- Identifies 'confusing' image pairs that have high similarity in CLIP embedding space but low similarity in DINO v2 space, indicating potential for visual misunderstanding
- Uses an LLM to generate text descriptions of why these images cause hallucinations, then uses a text-to-image model (DALL-E 3) to synthesize diverse new images based on these descriptions
- Constructs a benchmark of 1,200 instances across 8 specific hallucination modes (e.g., counting, shape, OCR) to rigorously test MLLMs
Architecture
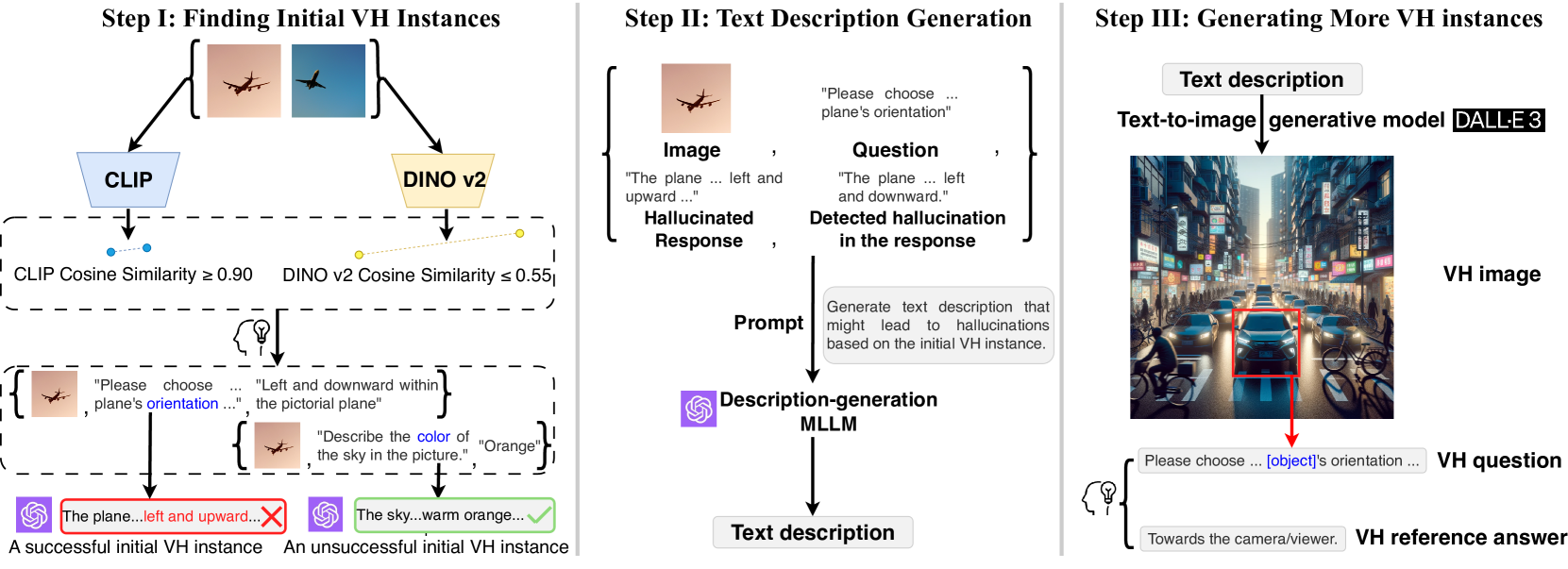
The VHTest pipeline: Discovery → Description → Generation
Evaluation Highlights
- State-of-the-art MLLMs fail frequently on this benchmark: GPT-4V achieves only 0.383 accuracy overall
- Open-source models struggle significantly: MiniGPT-v2 achieves only 0.075 overall accuracy
- Fine-tuning LLaVA-1.5 on the generated VHTest data improves accuracy on position hallucinations by +20.0% (from 0.333 to 0.533)
Breakthrough Assessment
8/10
Proposes a novel, scalable pipeline for generating adversarial visual benchmarks that exposes severe weaknesses in top-tier models (GPT-4V) previously thought to be robust.

