📝 Paper Summary
Multi-modal foundation models
Efficient pre-training
Sparse transformer architectures
Mixture-of-Transformers decouples non-embedding parameters by modality (text, image, speech) to reduce training costs while maintaining global self-attention across the full sequence.
Core Problem
Training unified multi-modal models requires massive datasets and compute because different modalities (text, image, speech) have conflicting training dynamics and occupy distinct feature spaces within dense transformers.
Why it matters:
- State-of-the-art multi-modal models like Chameleon require significantly more training tokens than text-only models to reach competitive performance
- Dense models process all modalities with the same weights despite inherent differences in data distribution, leading to inefficient optimization
- Standard Mixture-of-Experts (MoE) approaches introduce routing instability and load-balancing challenges that complicate training
Concrete Example:
In a dense Chameleon 7B model, text and image tokens are processed by identical Feed-Forward Networks (FFNs). This forces the weights to learn compromised representations for both, whereas Principal Component Analysis (PCA) shows these modalities naturally cluster in separate regions of the feature space.
Key Novelty
Mixture-of-Transformers (MoT)
- Statically assigns specific transformer parameters (FFNs, attention projections, LayerNorms) to specific modalities (text, image, speech) rather than using a learned router
- Processes input sequences by grouping tokens by modality, applying specific weights, and then recombining them for global self-attention, ensuring cross-modal context is preserved
- Reduces computational cost (FLOPs) by activating only a subset of parameters per token without the routing overhead or instability of standard Mixture-of-Experts
Architecture
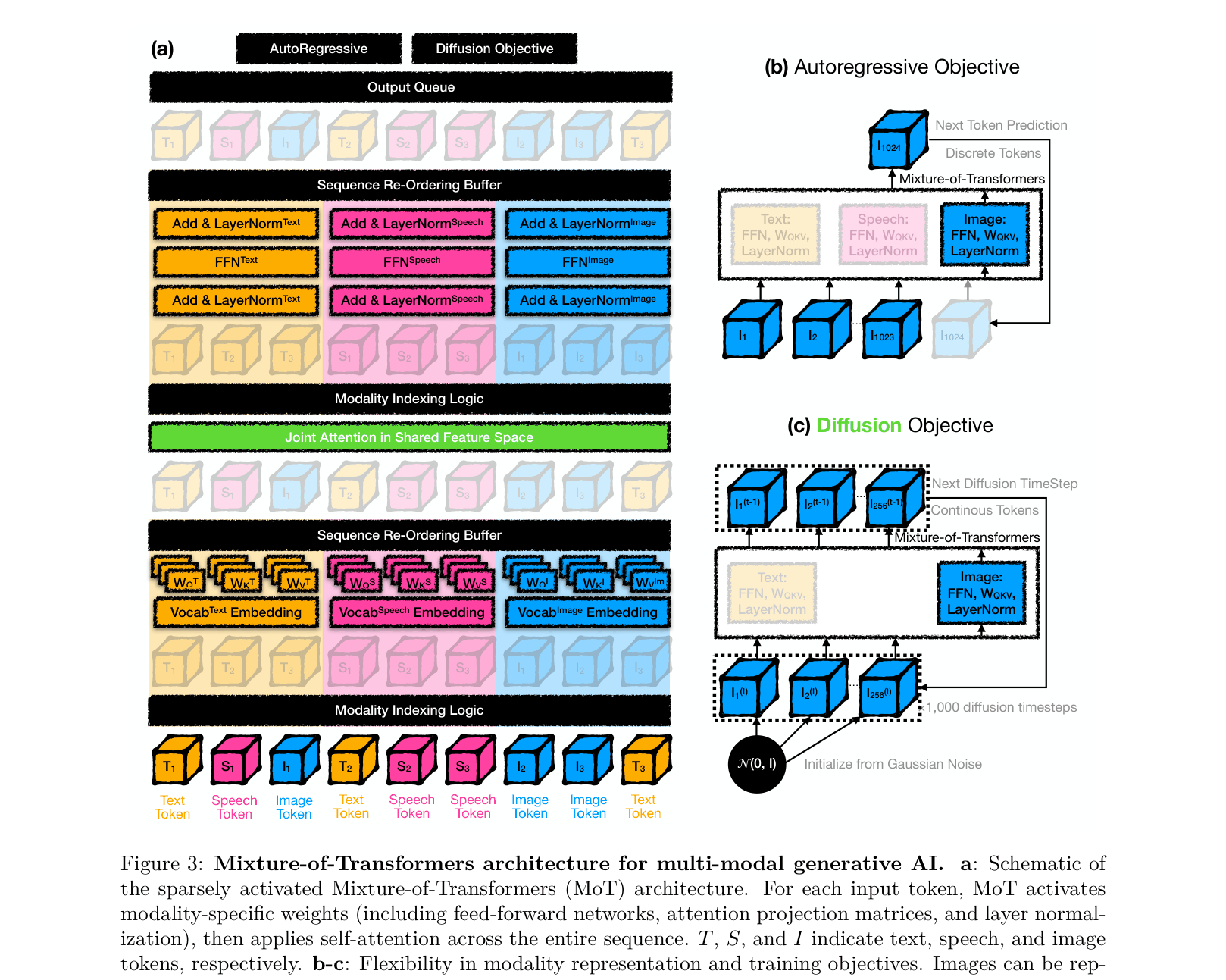
Schematic of the Mixture-of-Transformers (MoT) architecture compared to standard dense processing, highlighting the modality-specific paths.
Evaluation Highlights
- MoT 7B matches the dense Chameleon 7B baseline's performance using only 55.8% of the training FLOPs in the text-and-image setting
- In the text+image+speech setting, MoT reaches comparable speech performance to the dense baseline using only 37.2% of the FLOPs
- Achieves dense baseline image quality in 47.2% of wall-clock time on AWS p4de.24xlarge instances
Breakthrough Assessment
8/10
Significant efficiency gains (2x speedup) for multi-modal pre-training with a simple, stable architectural change. While it relies on predefined modalities rather than learned routing, the practical benefits for foundation model training are substantial.