📝 Paper Summary
Multi-modal learning
Semantic segmentation
State Space Models (SSMs)
Sigma applies the Mamba state space model to multi-modal semantic segmentation, using a Siamese architecture to fuse RGB and supplementary modalities with linear complexity instead of the quadratic cost of Transformers.
Core Problem
Existing multi-modal segmentation models either suffer from limited local receptive fields (CNNs) or computationally expensive quadratic complexity (ViTs), making them inefficient for handling high-resolution multi-modal data.
Why it matters:
- Autonomous agents need robust perception in adverse conditions (low light, glare) where RGB fails but Thermal/Depth succeed.
- Current ViT-based solutions scale poorly with image resolution due to self-attention, limiting real-time applicability.
- CNN-based solutions lack global context, leading to misclassifications in complex scenes.
Concrete Example:
In a scene with a round chair next to a sofa, shadows cause baseline models to fragment the chair into multiple incorrect segments. Sigma effectively utilizes depth information to recognize the chair as a singular entity.
Key Novelty
Siamese Mamba Network (Sigma)
- Replaces the standard Transformer or CNN backbone with a Siamese Mamba encoder that processes RGB and X-modality (Thermal/Depth) streams in parallel with linear complexity.
- Introduces a Mamba-based fusion mechanism that acts like cross-attention but uses Selective Scan operations to exchange and concatenate features efficiently.
- Employs a Channel-Aware Decoder that enhances the standard Mamba block with channel attention (pooling) to better select vital feature channels during upsampling.
Architecture
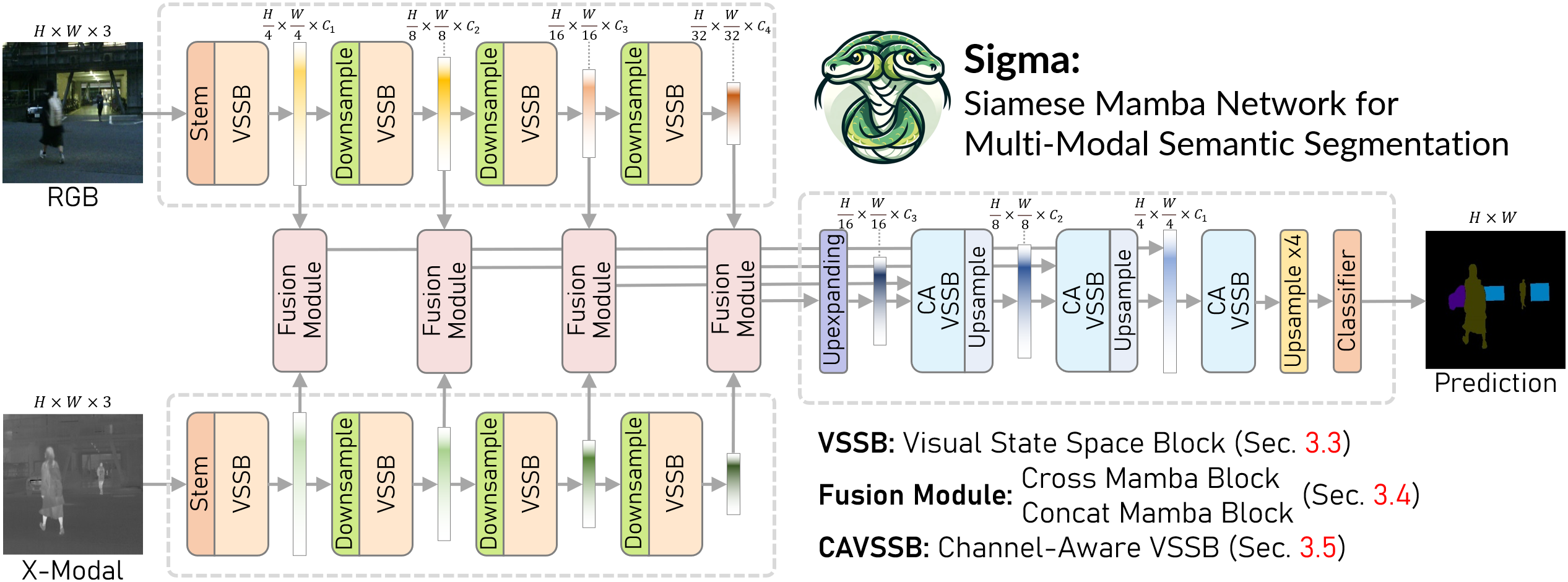
The overall architecture of Sigma, including the Siamese Mamba Encoder, Fusion Module, and Channel-Aware Decoder.
Evaluation Highlights
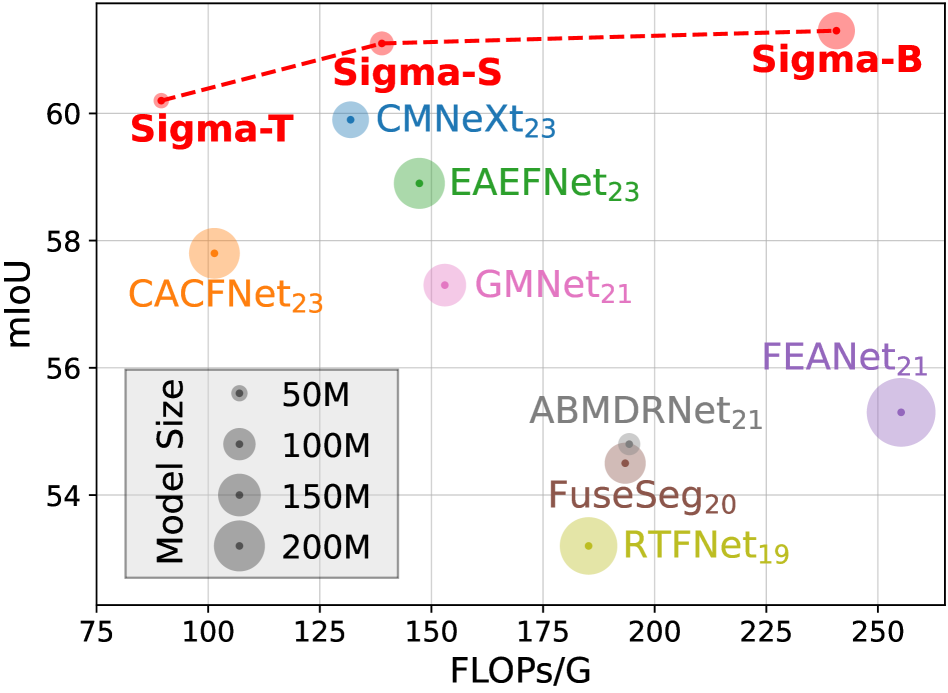
- Outperforms state-of-the-art CMNeXt by >2% mIoU on the PST900 RGB-Thermal dataset.
- Achieves higher accuracy than CMNeXt on NYU Depth V2 while using 49.8M fewer parameters (Sigma-Small vs CMNeXt-B2).
- Surpasses current methods on the MFNet dataset with fewer FLOPs and parameters in the tiny model variant.
Breakthrough Assessment
8/10
First successful application of Mamba (SSM) to multi-modal semantic segmentation. It successfully addresses the quadratic complexity bottleneck of Transformers while maintaining global receptive fields, showing strong empirical results.