📝 Paper Summary
Medical Multi-modal Large Language Models
Medical AI Agents
MMedAgent is the first general-purpose multi-modal medical agent that integrates diverse specialized tools via an instruction-tuned LLaVA-Med backbone to solve complex medical tasks across multiple imaging modalities.
Core Problem
Existing medical MLLMs are either generalists with limited depth or specialists restricted to narrow tasks, lacking the ability to seamlessly plan and execute multiple complex tasks across diverse imaging modalities.
Why it matters:
- Clinical practice requires handling varied data types (MRI, CT, X-ray) and tasks (diagnosis, segmentation, report generation) simultaneously, which single models struggle to do effectively
- Current generalist models lack the expert-level precision of specialized tools, while specialized tools cannot handle flexible natural language instructions
Concrete Example:
A user asks to 'detect the lesion in this CT scan and then segment it.' A standard VQA model might describe the lesion textually but cannot output a mask. A segmentation model (like MedSAM) needs a specific bounding box input, not a high-level text command. MMedAgent bridges this by calling a detection tool first, then passing coordinates to the segmentation tool.
Key Novelty
Multi-modal Medical Agent (MMedAgent) with Adapted Toolset
- Connects a central medical MLLM planner (LLaVA-Med) to six specialized tools using a unified 'Thought-Action-Value' dialogue format
- Adapts general vision tools to the medical domain (e.g., fine-tuning Grounding DINO on medical data) to fill gaps where off-the-shelf medical tools were missing
- Instruction-tunes the planner on a newly curated dataset that teaches it when to call tools and how to aggregate their results into a final response
Architecture
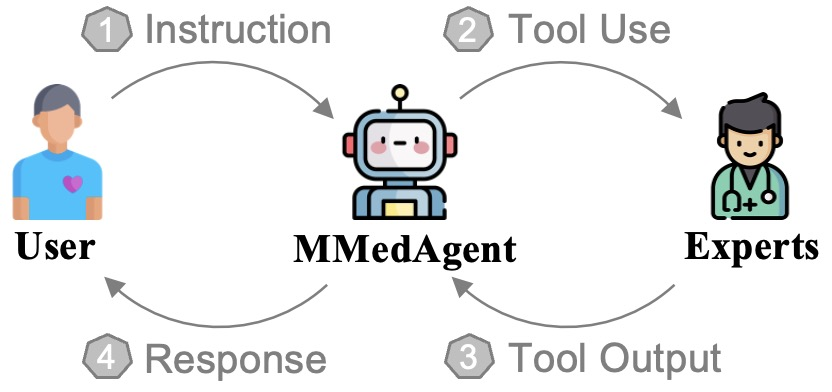
The inference workflow of MMedAgent. It illustrates how the Planner receives instruction/image, generates 'Thought' and 'Action', executes the 'Tool', and aggregates results into a final 'Answer'.
Evaluation Highlights
- Outperforms GPT-4o on average across representative medical tasks, specifically achieving higher scores in Segmentation and Detection metrics
- Achieves state-of-the-art performance compared to open-source medical MLLMs (e.g., LLaVA-Med, RadFM) on VQA, report generation, and classification tasks
- Demonstrates efficient extensibility: successfully learns to use a new tool (CT-Seg) with only 20 instruction-tuning samples
Breakthrough Assessment
8/10
First comprehensive multi-modal agent specifically for medicine. It successfully bridges the gap between high-level reasoning and low-level specialized medical tools, showing superior performance to both specialized and generalist baselines.