📝 Paper Summary
OS Agents
Benchmarking
Multi-modal Agents
WindowsAgentArena provides a scalable, reproducible benchmark for multi-modal agents on Windows OS, solving evaluation latency via Azure parallelization and introducing a baseline agent, Navi.
Core Problem
Existing agent benchmarks focus on Web or Linux, ignoring the dominant Windows OS (73% market share), and suffer from extremely slow serial evaluation times (days) for multi-step tasks.
Why it matters:
- Most human productivity occurs on Windows, yet agents are primarily tested on Linux/Web, creating a domain gap.
- Sequential evaluation of complex OS tasks is prohibitively slow, hindering rapid iterative development of agents.
- Existing benchmarks often lack the realism of a full OS environment where agents must switch between applications and contexts.
Concrete Example:
A task might require an agent to 'Make the line spacing of first two paragraphs into double line spacing' in LibreOffice Writer. While humans achieve 74.5% success, current agents struggle (19.5%), often failing to locate the correct menu items or handle window focus.
Key Novelty
Scalable Windows OS Benchmark
- Introduces the first extensive environment for Windows tasks (154 tasks across diverse apps) deployable in Docker containers.
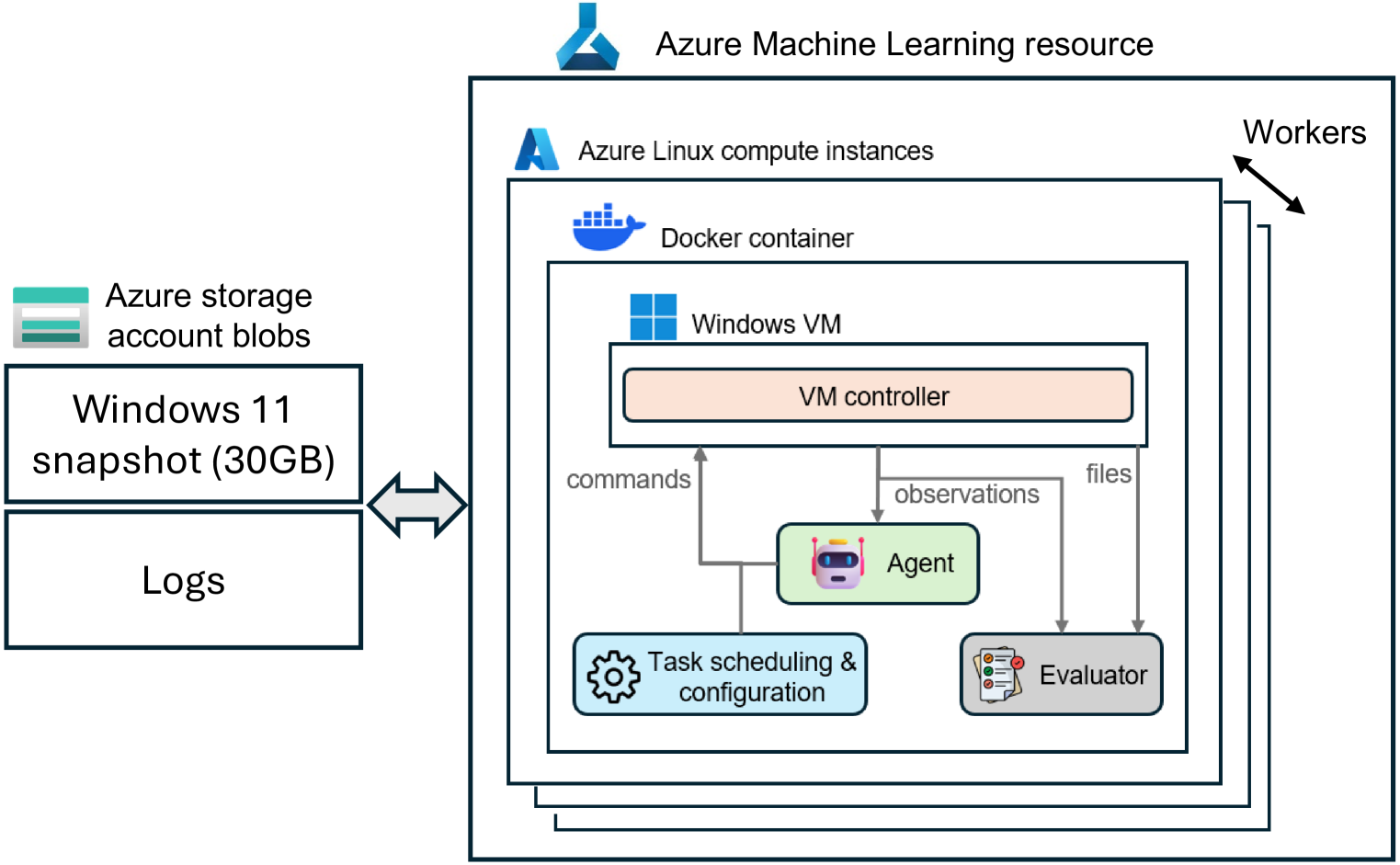
- Implements a cloud-native parallelization architecture using Azure to reduce full benchmark evaluation time from days to ~20 minutes.
- Provides a baseline agent (Navi) utilizing Set-of-Marks prompting to interact with hybrid pixel/accessibility-tree observations.
Architecture
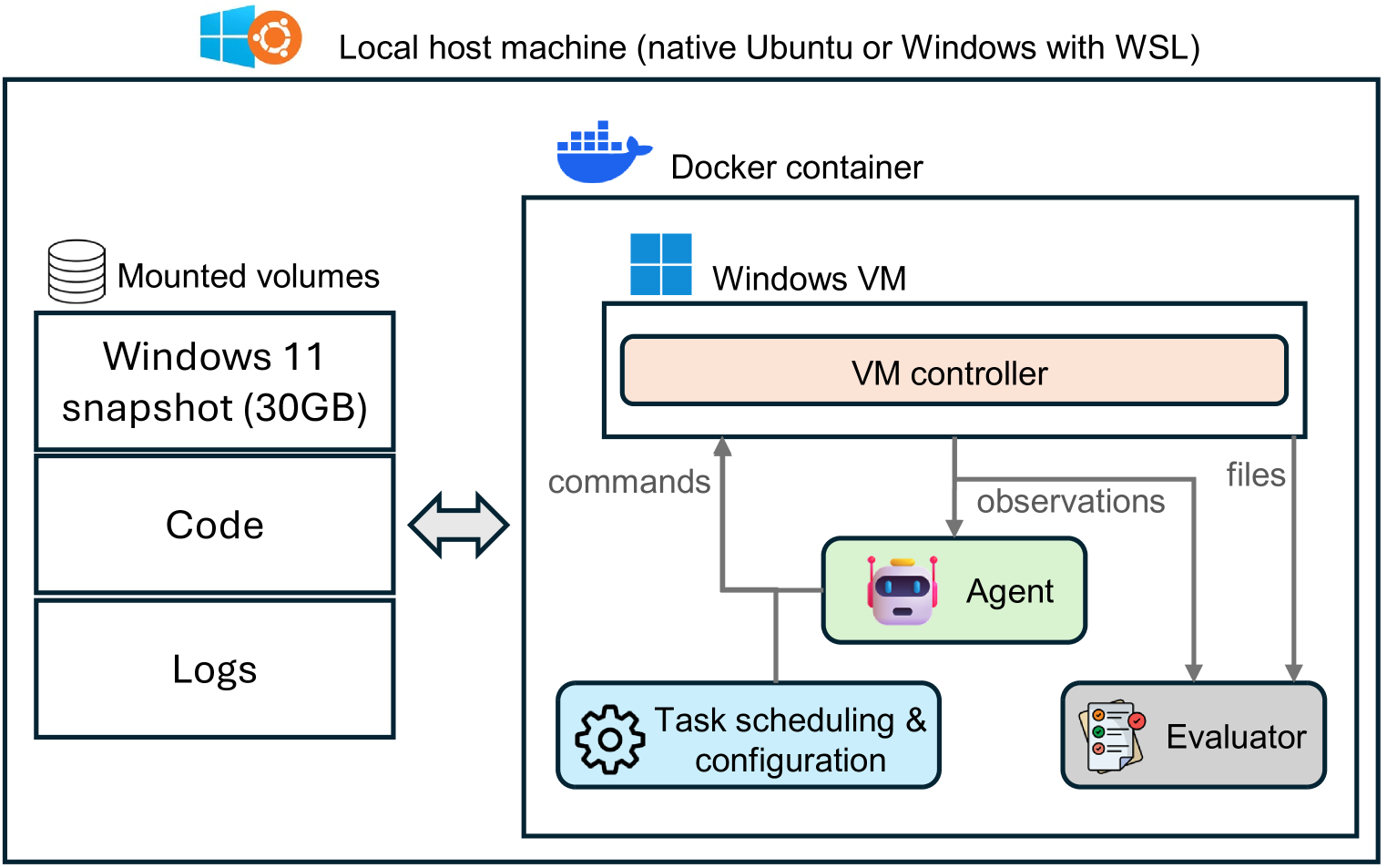
The Navi agent architecture and inference flow.
Evaluation Highlights
- Navi (best agent variant) achieves 19.5% success rate on WindowsAgentArena, highlighting the difficulty of the domain compared to the 74.5% human baseline.
- Cloud parallelization reduces full benchmark evaluation time to 20 minutes, a massive acceleration compared to serial execution.
- Human performance is highest on Windows Utilities (91.7%) and lowest on VLC Player tasks (42.8%), establishing a roofline for agent improvement.
Breakthrough Assessment
8/10
Addresses a massive gap (Windows OS) and a critical bottleneck (eval time). While agent performance is low, the infrastructure enabling scalable Windows research is a significant contribution.