📝 Paper Summary
Multi-modal Large Language Models (MLLMs)
Long-context video/image understanding
Efficient hybrid architectures
LongLLaVA integrates a hybrid Transformer-Mamba architecture with 2D pooling and a progressive training strategy to process up to 1000 images on a single GPU while maintaining high performance.
Core Problem
Extending MLLMs to process long visual sequences (like long videos or many images) causes linear increases in token counts that overwhelm standard Transformers' quadratic complexity, leading to high computational costs and memory bottlenecks.
Why it matters:
- Standard visual encoders generate massive token counts (e.g., >100k tokens for a 3-minute video), making processing prohibitively expensive.
- Existing compression methods are lossy, sacrificing fine-grained details necessary for nuanced understanding.
- Pure Mamba architectures are efficient but struggle with In-Context Learning (ICL) and complex retrieval compared to Transformers.
Concrete Example:
Representing a three-minute video at 1 FPS generates over 100,000 tokens. A standard Transformer faces quadratic complexity, crashing memory buffers, while aggressive compression loses the details needed to answer specific questions about short events within the video.
Key Novelty
LongLLaVA: Hybrid Mamba-Transformer MLLM
- Combines Mamba layers (linear complexity for efficiency) with Transformer layers (for retrieval/reasoning) in a 7:1 ratio to handle massive visual context.
- Uses 2D pooling to compress visual tokens by 4x (576 to 144) while preserving spatial structure, reducing the sequence length before it hits the LLM.
- Implements a three-stage progressive training strategy that moves from single-image alignment to multi-image instruction tuning to learn temporal and spatial dependencies.
Architecture
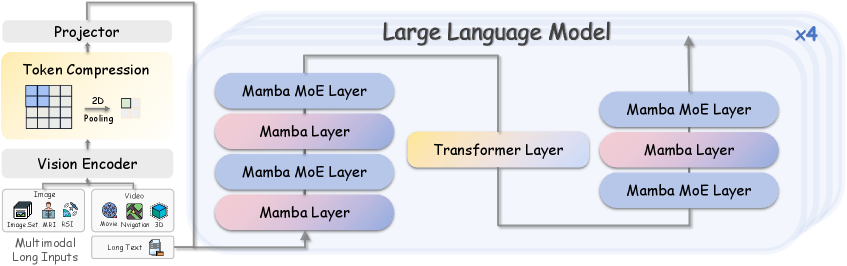
Overview of the LongLLaVA architecture including the vision encoder, projector, and hybrid LLM backbone.
Evaluation Highlights
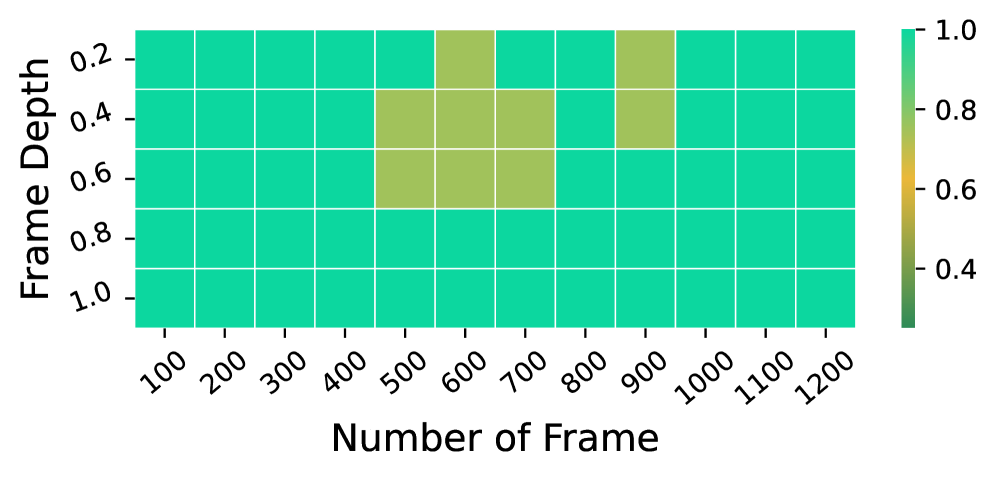
- Processes nearly 1000 images on a single A100 80GB GPU, achieving nearly 100% accuracy on the Needle-In-A-Haystack retrieval task.
- Achieves competitive performance on Video-MME and MVBench benchmarks with an order of magnitude fewer FLOPs than comparable Transformer-only models.
- Outperforms GPT-4V on specific atomic capabilities like counting and ordering in the VNBench synthetic video framework.
Breakthrough Assessment
8/10
Significant efficiency breakthrough allowing 1000-image context on a single GPU without major performance loss. The hybrid architecture approach for MLLMs is a timely and impactful direction for scaling video understanding.