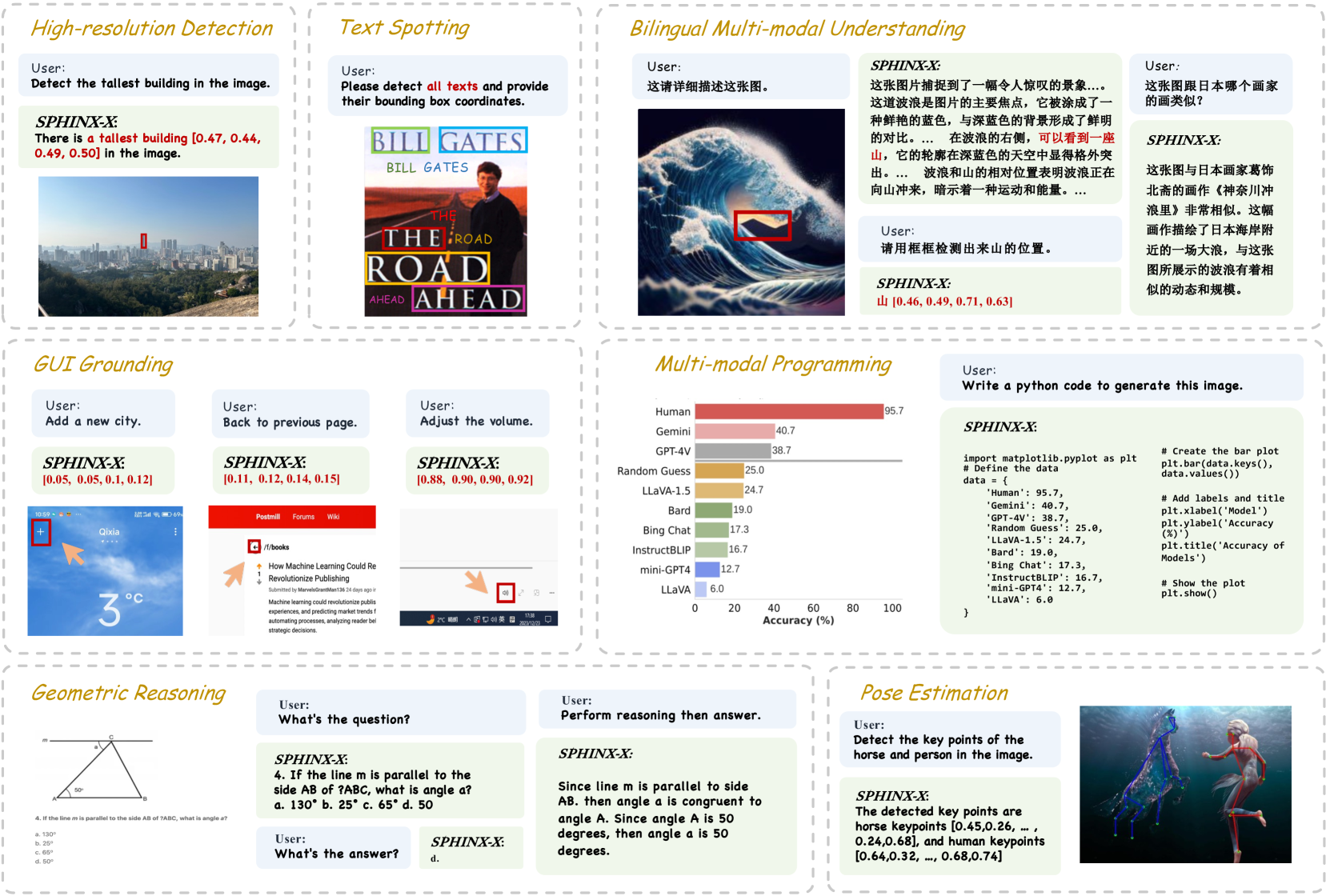
📝 Paper Summary
Multi-modal Large Language Models (MLLMs)
Visual Instruction Tuning
SPHINX-X scales multi-modal LLMs from 1B to 8x7B parameters using a streamlined one-stage training pipeline, efficient visual encoding with skip tokens, and extensive multi-domain datasets.
Core Problem
Existing MLLMs are constrained by limited training data domains (mostly natural images) and a narrow range of model sizes (typically 7B/13B), hindering both edge deployment and complex reasoning.
Why it matters:
- Narrow data coverage leads to poor performance on out-of-domain tasks like OCR, charts, and mathematical reasoning
- Fixed model sizes (7B-13B) are too large for mobile devices yet insufficient for high-end reasoning capabilities
- Redundant visual encoders and multi-stage training pipelines in prior work (like SPHINX) increase computational cost and complexity
Concrete Example:
When processing high-resolution images with large aspect ratios (e.g., 2:1), standard tiling approaches generate fully-padded sub-images containing only zeros. These waste computation in the vision encoder and LLM, as the model processes useless tokens.
Key Novelty
SPHINX-X Family (Scaling & Simplification)
- Eliminates redundant visual encoders from SPHINX, keeping only a complementary 'Mixture of Visual experts' (DINOv2 + CLIP-ConvNeXt)
- Introduces learnable 'skip tokens' to replace fully-padded sub-images during tiling, reducing sequence length and computation
- Consolidates training into a single-stage 'all-in-one' paradigm using a massive multi-domain dataset, including custom OCR and Set-of-Mark data
Architecture
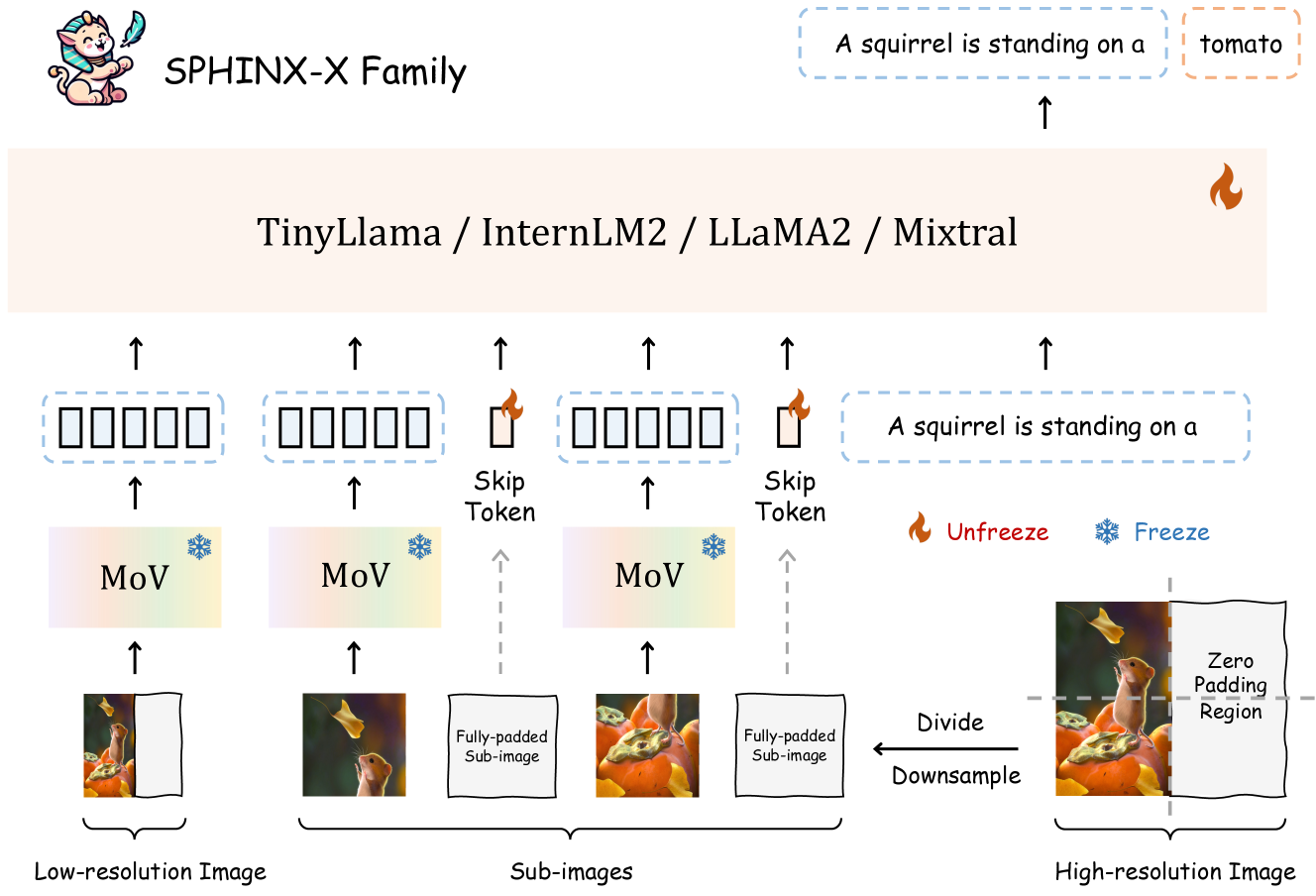
The training pipeline and architecture of SPHINX-X, detailing the Mixture of Visual experts (MoV), skip token mechanism, and one-stage training.
Evaluation Highlights
- SPHINX-Plus (13B) achieves 71.0 on MMBench, surpassing the original SPHINX (67.1) and LLaVA1.5-13B (67.7)
- SPHINX-MoE (Mixtral 8x7B) demonstrates strong reasoning, reaching 36.8% on MathVista and 71.3% on SEED-Bench
- SPHINX-Tiny (1.1B) achieves 56.6 on MMBench, outperforming larger baselines like InstructBLIP-7B (53.4) despite having far fewer parameters
Breakthrough Assessment
8/10
Offers a comprehensive open-source family of MLLMs covering diverse scales (1B to MoE) with solid performance gains and practical architectural improvements (skip tokens, simplified training).