📝 Paper Summary
Large Multimodal Models (LMMs)
Vision-Language Pre-training
High-Resolution Image Processing
Monkey enhances Large Multimodal Models by processing high-resolution images via sliding window patches with individual adapters and training on automatically generated multi-level descriptions.
Core Problem
Existing LMMs struggle with high-resolution inputs due to the high cost of training large vision encoders from scratch, and suffer from poor image-text alignment because standard training datasets have overly simple captions.
Why it matters:
- Low resolution limits the detection of small objects and dense text, crucial for tasks like document understanding and detailed scene analysis.
- Simple captions (e.g., 'a dog') fail to teach models complex spatial relationships and attributes, leading to hallucinations or missed details.
- Retraining vision encoders for higher resolutions is computationally prohibitive for many researchers.
Concrete Example:
In an image of a storefront, a standard LMM might see 'a store', but fail to read the small 'Emporio Armani' text or notice a specific person in the background because the input was downscaled to 448x448.
Key Novelty
Resolution Enhancement via Sliding Window Patches & Multi-Level Description Generation
- Instead of retraining a vision encoder for large images, the image is split into patches. Each patch is processed by the same frozen encoder (originally trained on smaller images) but with a unique Low-Rank Adapter (LoRA) to handle spatial variations.
- To improve training data quality, a multi-stage pipeline combines multiple specialized models (BLIP2, PPOCR, GRIT, SAM, ChatGPT) to generate layered captions covering global context, specific regions, objects, and text.
Architecture
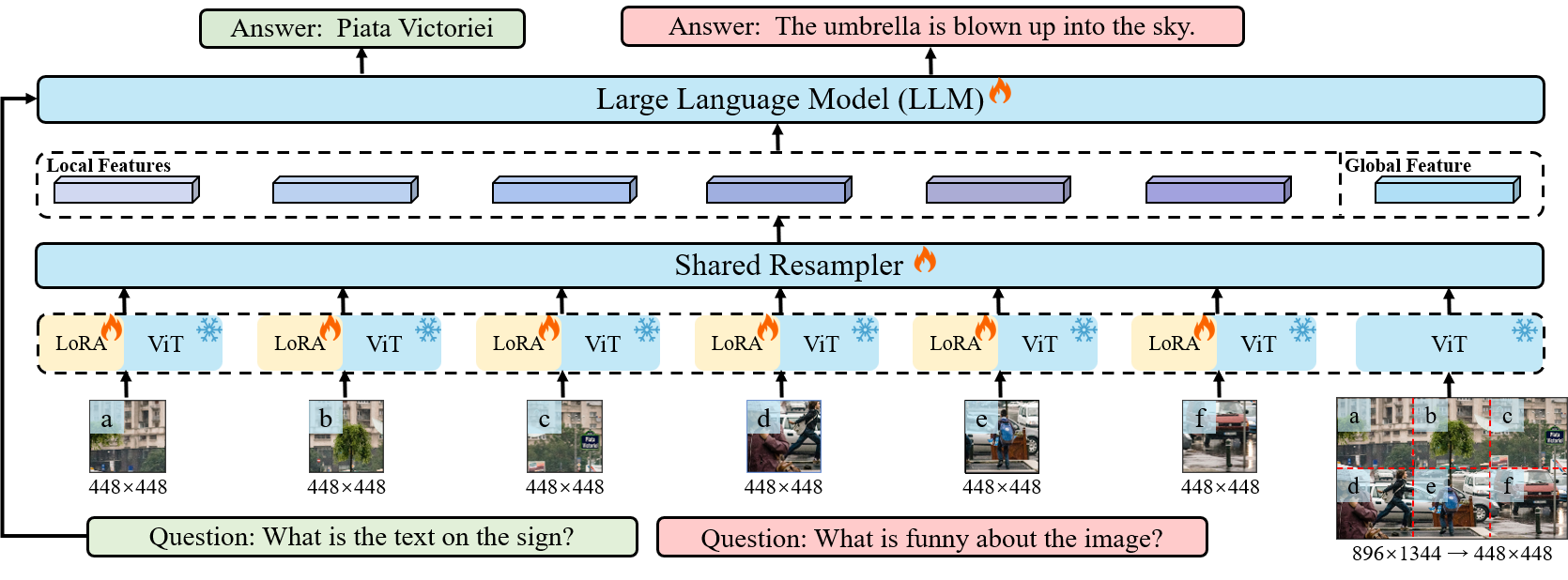
The Monkey architecture showing image patching, shared ViT with LoRA adapters, resampler, and LLM.
Evaluation Highlights
- +9.77% average improvement over Qwen-VL on Document-oriented VQA tasks (e.g., DocVQA, ChartQA) due to higher resolution handling.
- Achieved a perception score of 1505.3 on the MME benchmark, ranking second among tested models.
- Outperforms GPT-4V in qualitative tests for dense text question answering, successfully identifying small text elements like store names that GPT-4V missed.
Breakthrough Assessment
8/10
Significantly improves resolution handling without expensive pre-training and demonstrates the critical importance of data quality via multi-level descriptions. Strong results on document/text tasks.