📝 Paper Summary
Human Animation
Talking Head Generation
Video Diffusion Models
EchoMimicV3 unifies diverse human animation tasks into a single lightweight 1.3B parameter model by reformulating them as spatial-temporal masked reconstruction and using a phase-aware multi-modal fusion strategy.
Core Problem
Current human animation relies on large-scale video diffusion models that are computationally expensive, slow to infer, and require separate expert models for different tasks (lip-sync vs. motion generation), complicating deployment.
Why it matters:
- Prohibitive training costs and slow inference speeds of large models (LVDMs) hinder real-time or consumer-grade applications.
- The need for separate models for each task increases deployment complexity and resource consumption in multi-task scenarios.
- Existing compact models (CVDMs) usually compromise on quality, generalization, and multi-modal handling compared to larger counterparts.
Concrete Example:
Long video generation often fails with frame-wise sliding windows, causing unnatural transitions, color discrepancies, and identity inconsistencies across windows due to poor noise smoothing in overlapping frames.
Key Novelty
Soup-of-Tasks and Soup-of-Modals Paradigms
- Reformulates all animation tasks (lip-sync, text-to-video, image-to-video) as a unified spatial-temporal masked reconstruction problem, allowing a single model to handle all by changing input masks.
- Uses a 'hard-to-easy' training schedule, starting with complex full-video generation and gradually adding simpler tasks like lip-sync via Exponential Moving Average (EMA) to prevent forgetting.
- Dynamically allocates weights to text, audio, and image conditions based on the diffusion timestep phase (e.g., audio matters most early on), fusing them via a Coupled-Decoupled Cross Attention module.
Architecture
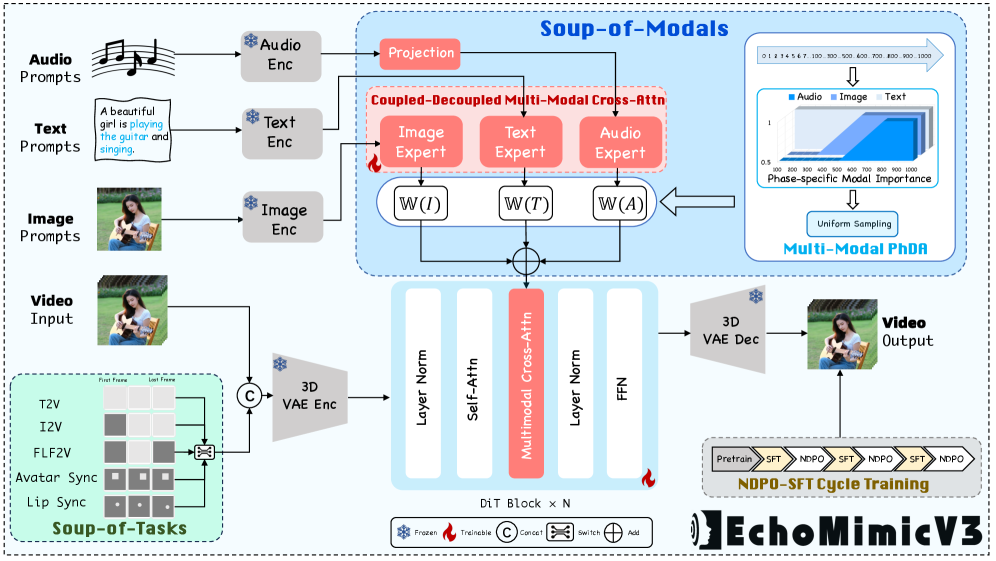
Overview of the EchoMimicV3 framework, including the Soup-of-Tasks masking, CDCA module, and PhDA mechanism.
Evaluation Highlights
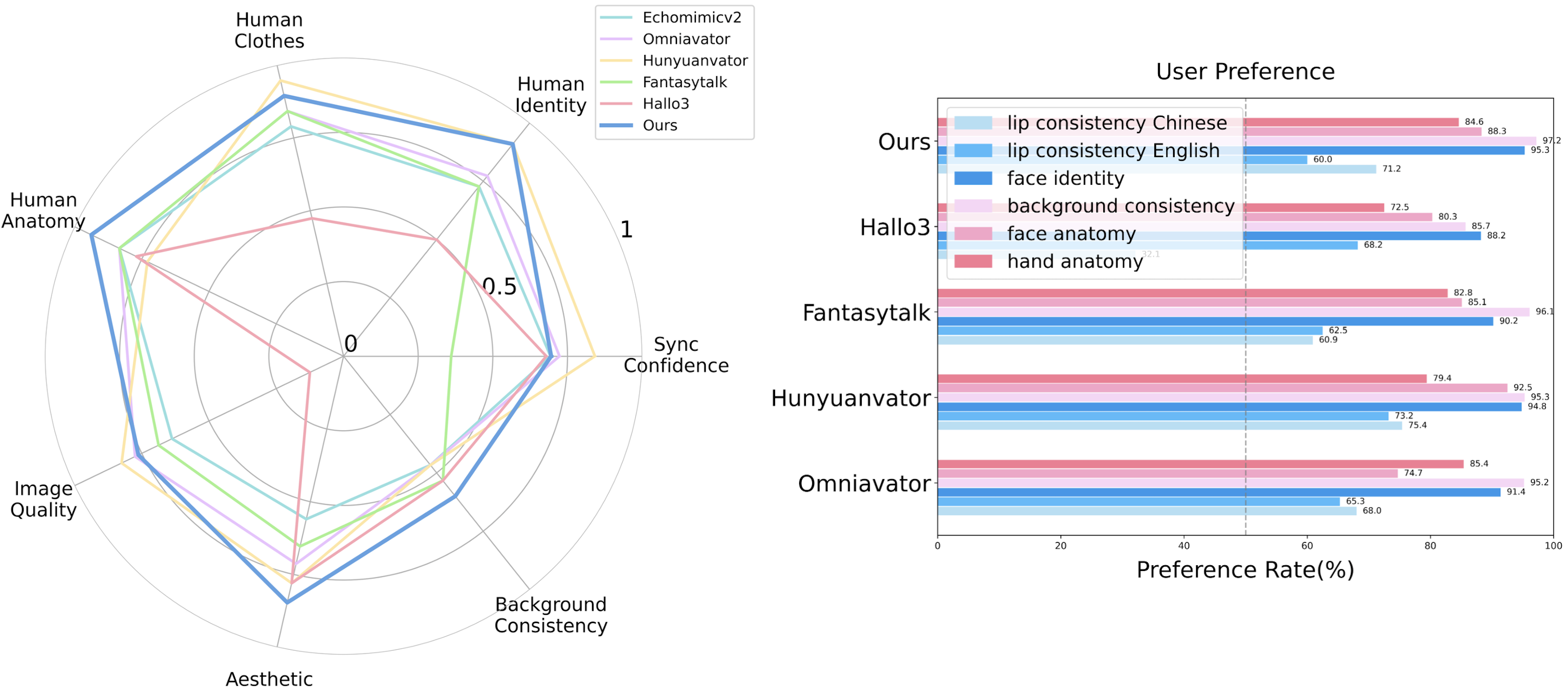
- Achieves competitive performance with only 1.3B parameters, matching or exceeding models with 10x parameters (e.g., FantasyTalk) in identity preservation and video aesthetics.
- Superior audio-lip synchronization and human motion accuracy compared to SOTA methods like EchoMimicV2, HunyuanAvatar, and Hallo3.
- Effective long-video generation with reduced artifacts via Phase-aware Negative classifier-free Guidance (PNG) and improved sliding window inference.
Breakthrough Assessment
8/10
Successfully unifies multiple animation tasks and modalities into a significantly smaller model (1.3B) without quality loss, offering a practical solution to the 'large model' bottleneck in human animation.