📝 Paper Summary
Visual Object Tracking
Multi-Modal Learning
Prompt Learning
ViPT adapts a frozen, pre-trained RGB tracking foundation model to multi-modal tasks by learning lightweight modality-complementary prompts instead of full fine-tuning.
Core Problem
Multi-modal tracking (RGB + Depth/Thermal/Event) lacks large-scale training data compared to RGB tracking, making full fine-tuning of foundation models prone to overfitting and parameter inefficiency.
Why it matters:
- Full fine-tuning is storage-heavy, requiring a separate copy of the large foundation model for each downstream task
- Scarcity of multi-modal data (e.g., DepthTrack has ~0.2M frames vs. TrackingNet's 14M) limits the generalization of fully tuned models
- Existing methods often design complex extra branches for auxiliary modalities, increasing architectural complexity
Concrete Example:
In RGB-Thermal tracking, a standard approach builds a two-stream network and retrains all parameters. Due to limited thermal data, the model might overfit the small dataset and lose the robust feature extraction capabilities learned from massive RGB datasets.
Key Novelty
Visual Prompt Multi-modal Tracking (ViPT)
- Freeze the entire pre-trained RGB foundation model to preserve general visual knowledge
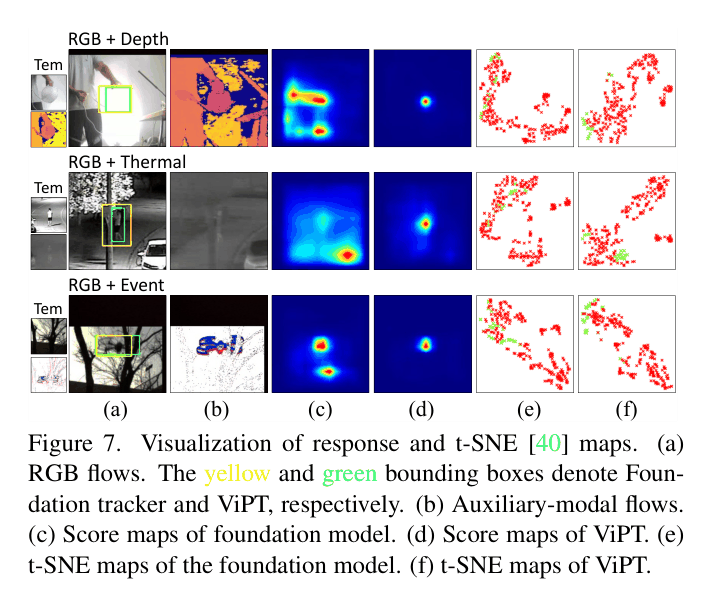
- Introduce sparse 'Modality-Complementary Prompter' (MCP) blocks that inject auxiliary modality information (Depth/Thermal/Event) into the frozen backbone
- Learn only the prompt parameters (<1% of total), allowing the model to adapt to new modalities while maintaining the robustness of the foundation model
Architecture
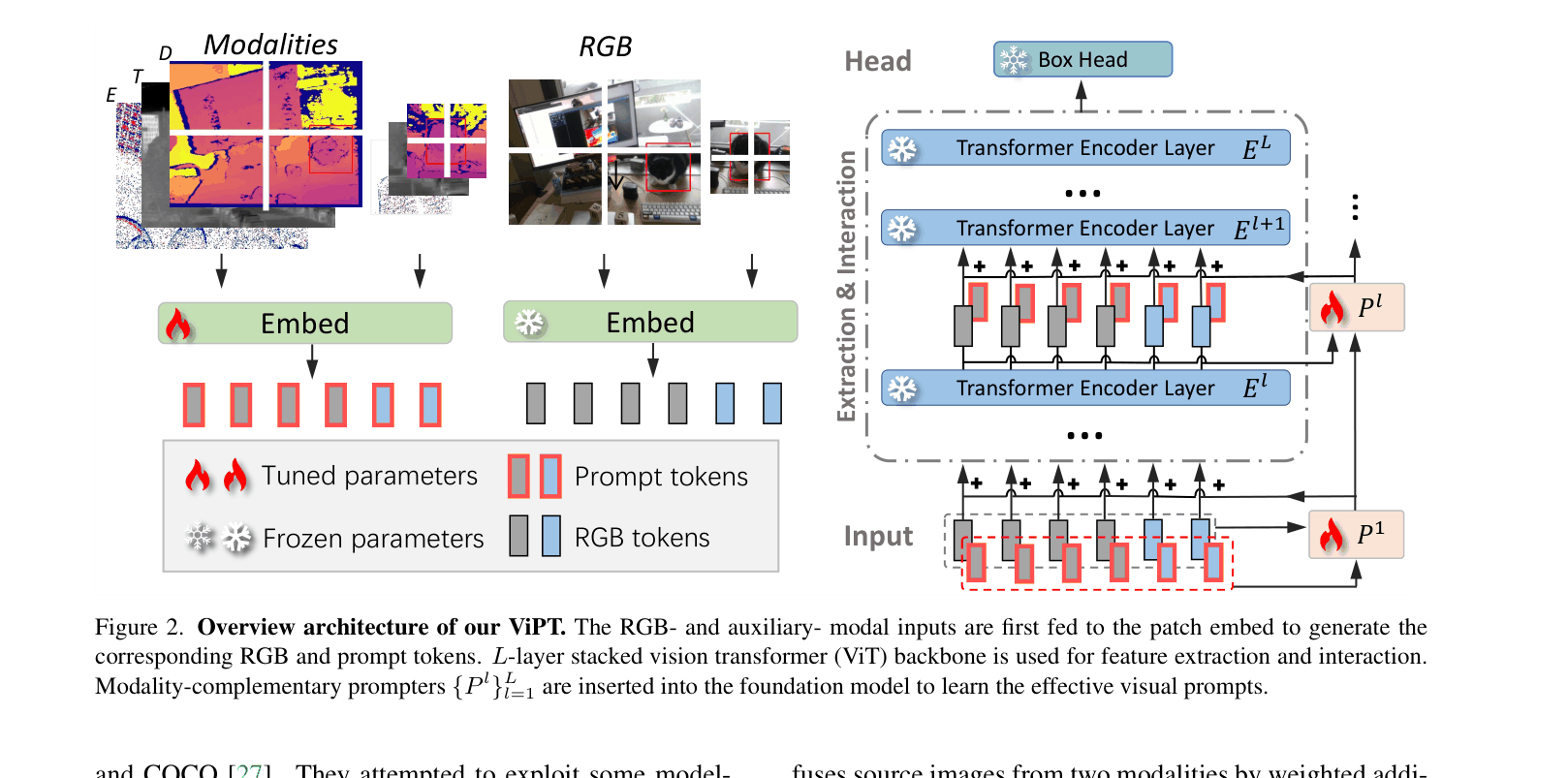
Overview of ViPT architecture and detailed Modality-Complementary Prompter (MCP) design.
Evaluation Highlights
- Achieves state-of-the-art 59.4% F-score on DepthTrack (RGB-D), surpassing the foundation model by +6.5%
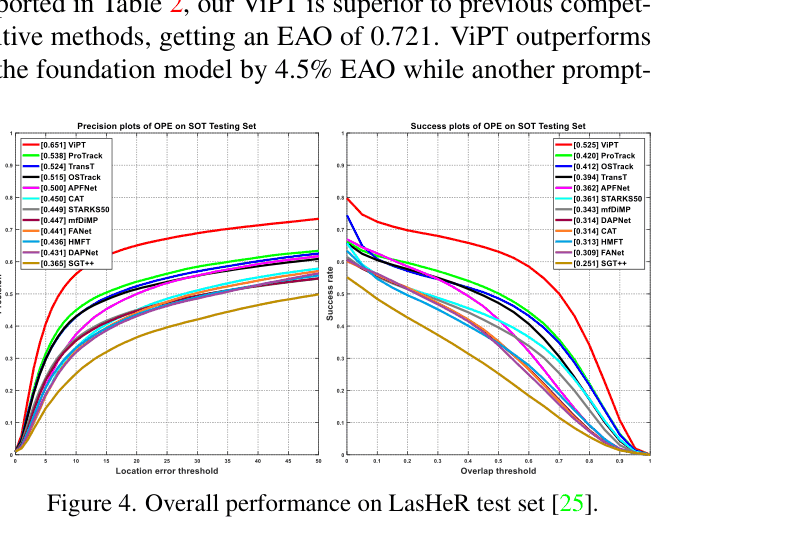
- Outperforms the runner-up by +10.5% in Success Rate on the LasHeR benchmark (RGB-T) while using <1% trainable parameters
- Beats full fine-tuning (FFT) paradigms across all tasks despite having two orders of magnitude fewer trainable parameters (0.84M vs 178.6M)
Breakthrough Assessment
8/10
Successfully introduces prompt learning to multi-modal tracking, demonstrating that fine-tuning <1% of parameters can outperform full fine-tuning. A highly efficient and effective adaptation strategy.