📝 Paper Summary
Multi-Modal Large Language Models (MLLMs)
Hallucination mitigation
OPERA mitigates hallucinations in Multi-Modal LLMs by penalizing attention patterns where the model 'over-trusts' specific summary tokens and re-allocating attention when such patterns are detected.
Core Problem
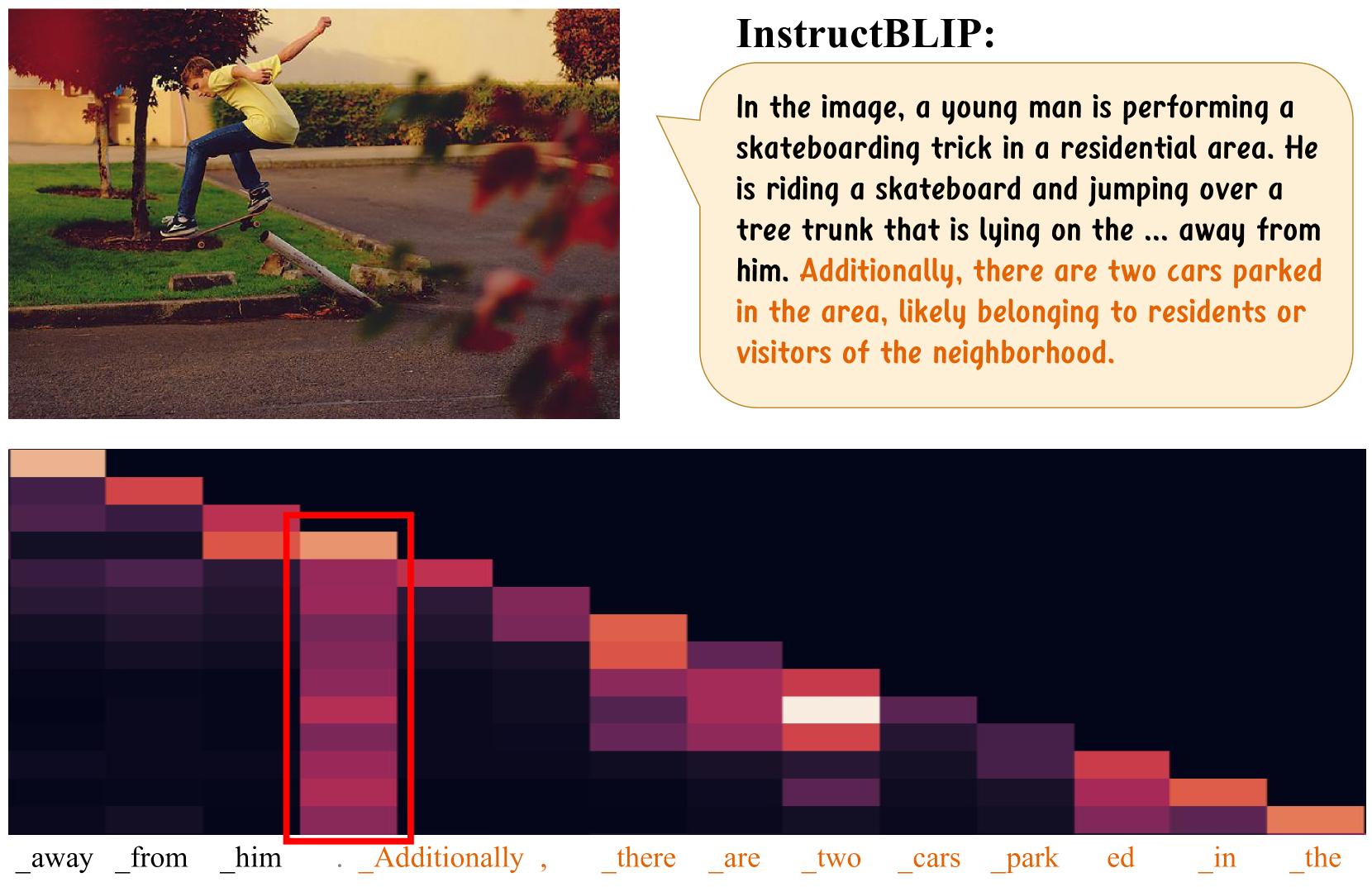
MLLMs often generate hallucinations (incorrect statements not present in the image) because they tend to aggregate information onto a few 'summary tokens' and then generate subsequent text based on these tokens rather than the original visual input.
Why it matters:
- Hallucinations severely impede real-world usage of MLLMs in safety-critical tasks like model-assisted autonomous driving.
- Existing solutions often require expensive retraining, extra data annotation, or external knowledge bases.
- The 'partial over-trust' phenomenon causes the model to ignore image tokens as the generated text length increases.
Concrete Example:
In an image description task, an MLLM might correctly identify a 'road', but then focus heavily on the token 'road' (the summary token) to hallucinate 'cars' that aren't actually in the picture, simply because 'cars' frequently co-occur with 'road' in the language prior.
Key Novelty
Over-trust Penalty and Retrospection-Allocation (OPERA)
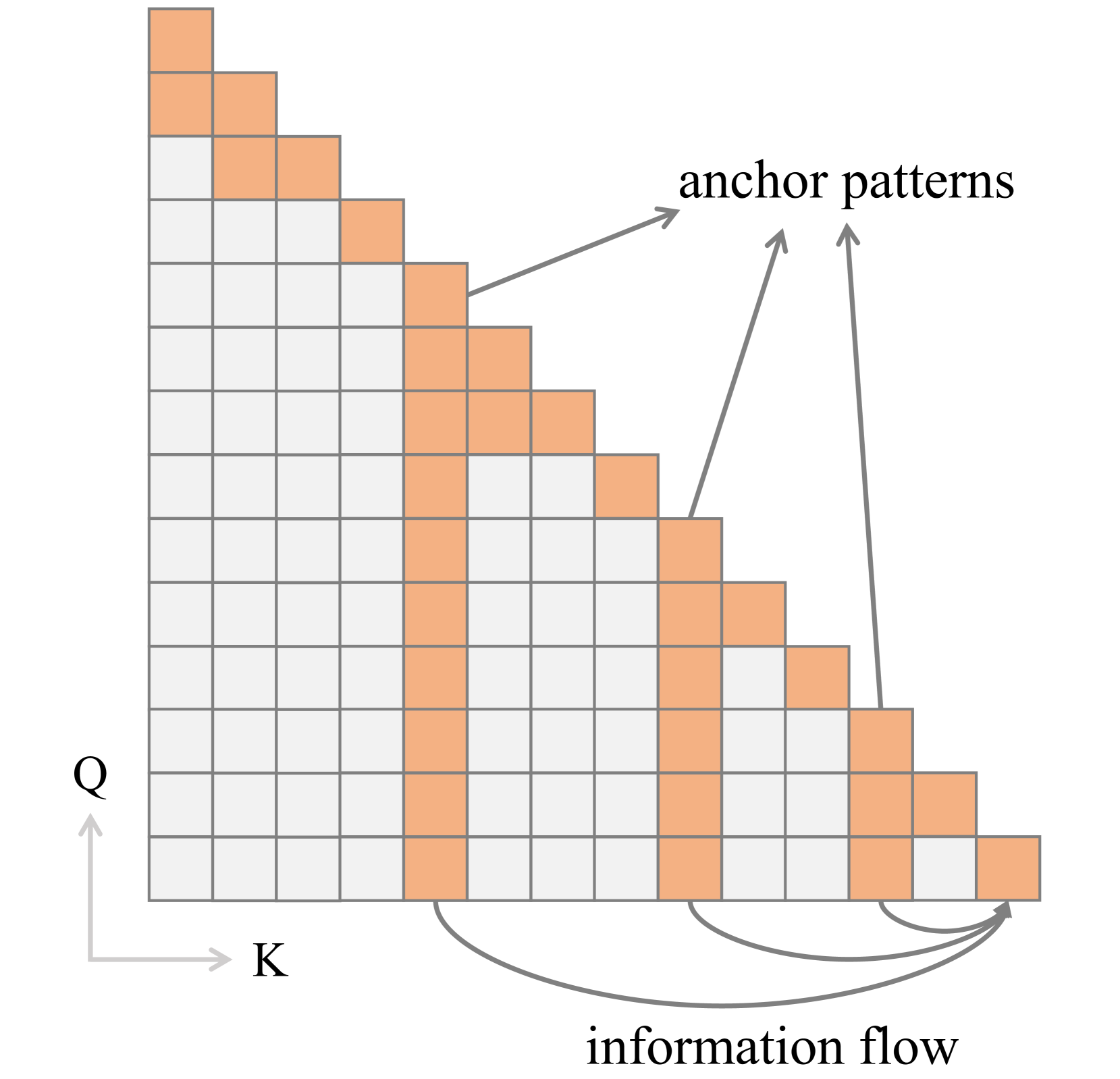
- Identifies a 'columnar attention pattern' where models over-rely on specific summary tokens (like punctuation), leading to hallucinations.
- Introduces a logit penalty during beam search that discourages selecting candidates exhibiting this over-trust attention pattern.
- Implements a 'rollback' strategy: if the over-trust pattern is detected retrospectively, the decoder backtracks to the summary token and forces a different selection path.
Architecture
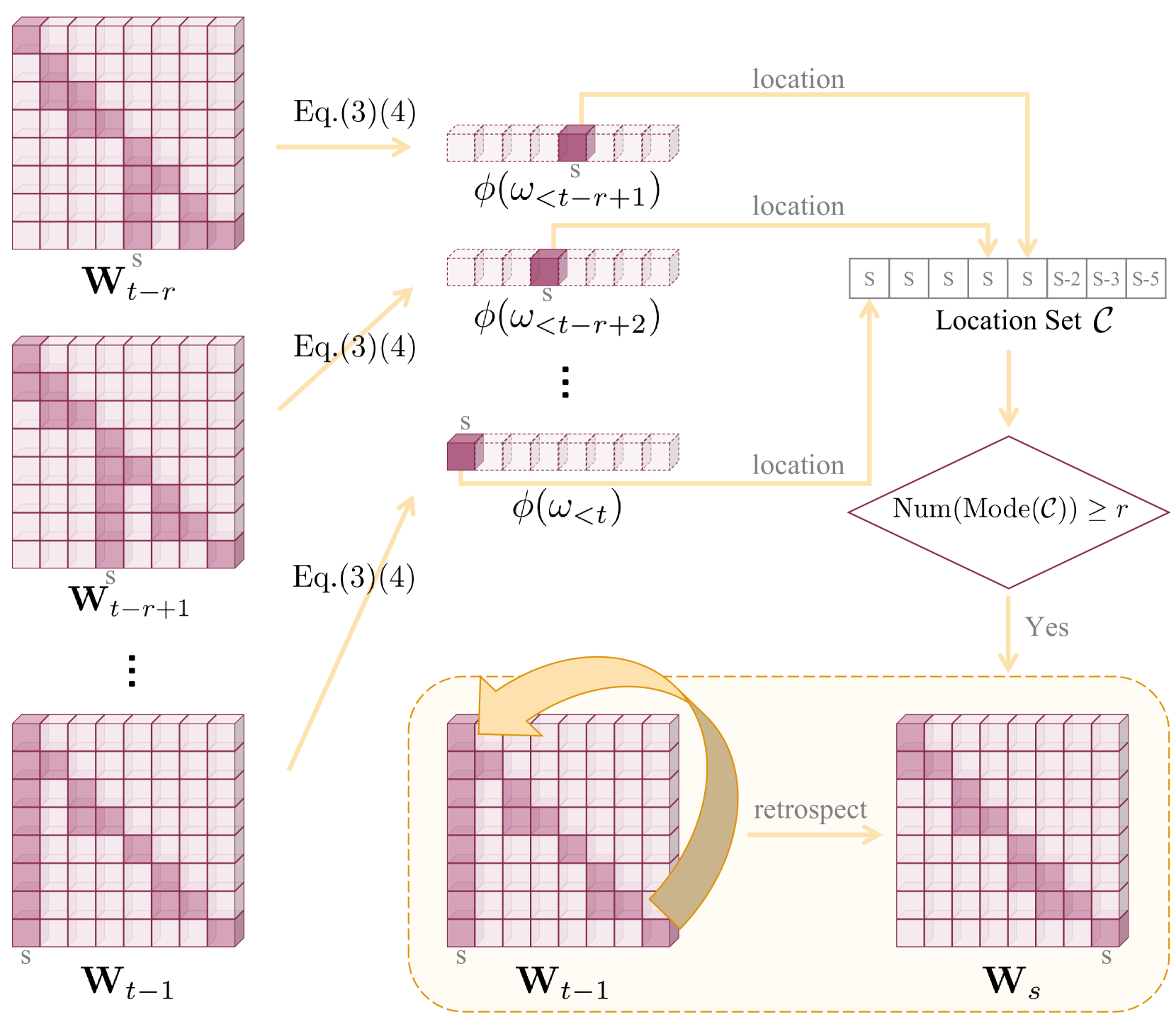
The flowchart of the OPERA decoding strategy, specifically the Retrospection-Allocation mechanism.
Evaluation Highlights
- Achieves up to +35.8% improvement on the CHAIR metric (hallucination evaluation) compared to baseline decoding methods.
- Consistently improves performance across multiple MLLMs (InstructBLIP, MiniGPT-4, LLaVA, Shikra) without any training.
- Outperforms other decoding strategies like Greedy, Nucleus Sampling, and DoLa on the POPE benchmark.
Breakthrough Assessment
8/10
Offers a 'free lunch' solution to a critical problem (hallucination) by modifying decoding dynamics rather than retraining. The observation of 'summary tokens' as hallucination triggers is a significant insight.