📝 Paper Summary
Unified Multi-Modal Models
Interleaved Image-Text Generation
Mogao unifies autoregressive text generation and diffusion-based image generation in a single causal transformer using decoupled weights and efficient complete teacher forcing for seamless interleaved multi-modal interaction.
Core Problem
Current unified models struggle to balance text understanding and high-quality image generation, often suffering from task conflict in shared parameters, slow autoregressive image synthesis, or training-inference discrepancies in interleaved sequences.
Why it matters:
- Models need to process and generate arbitrary sequences of mixed text and images to interact naturally with humans (e.g., illustrated storytelling, visual editing)
- Unified models relying on shared parameters for both tasks often degrade performance in one modality due to conflicting gradients (understanding vs. generation)
- Standard autoregressive image generation is slower and lower quality than diffusion, but naive hybrid approaches lack efficient training strategies for long interleaved contexts
Concrete Example:
A user asks a model to 'Draw a cat' then 'Make it sleep'. A standard T2I model cannot handle the second turn because it lacks context memory. A shared-parameter unified model might generate the image but lose text coherence due to task conflict.
Key Novelty
Causal Omni-Modal Architecture with Decoupled Routing
- Integrates autoregressive text generation and diffusion-based image generation into one transformer, but routes them through separate QKV/FFN parameters to prevent task conflict
- Uses 'Efficient Complete Teacher Forcing' (ECTF) during training, which decouples clean history from noisy targets via masking, allowing simultaneous optimization of text and image generation without redundant computation
Architecture
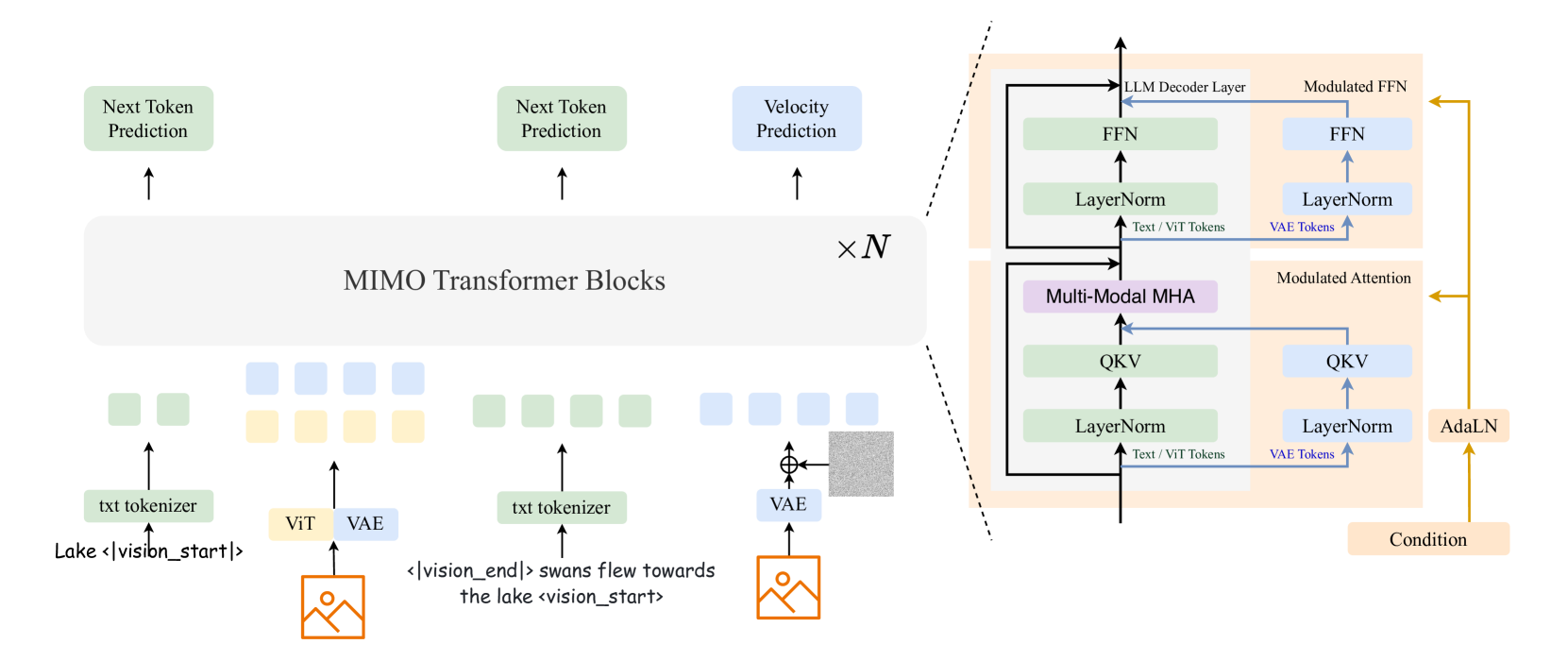
The overall architecture of Mogao, highlighting the unified transformer with decoupled pathways for text and visual modalities.
Evaluation Highlights
- Achieves state-of-the-art 83.3% on MME perception benchmark, outperforming Emu2 (78.3%) and Mantis-8B (80.6%)
- Surpasses SDXL and Emu2 in human evaluation for interleaved generation quality (Win Rate > 50%)
- Reduces training complexity for interleaved sequences from quadratic to linear via ECTF, enabling efficient scaling to long contexts
Breakthrough Assessment
8/10
Mogao effectively solves the 'jack of all trades, master of none' problem in unified models by decoupling parameters and introducing a novel training strategy (ECTF) for interleaved data.
