📝 Paper Summary
Embodied AI
Multi-modal Large Language Models (MLLMs)
Agent Evaluation
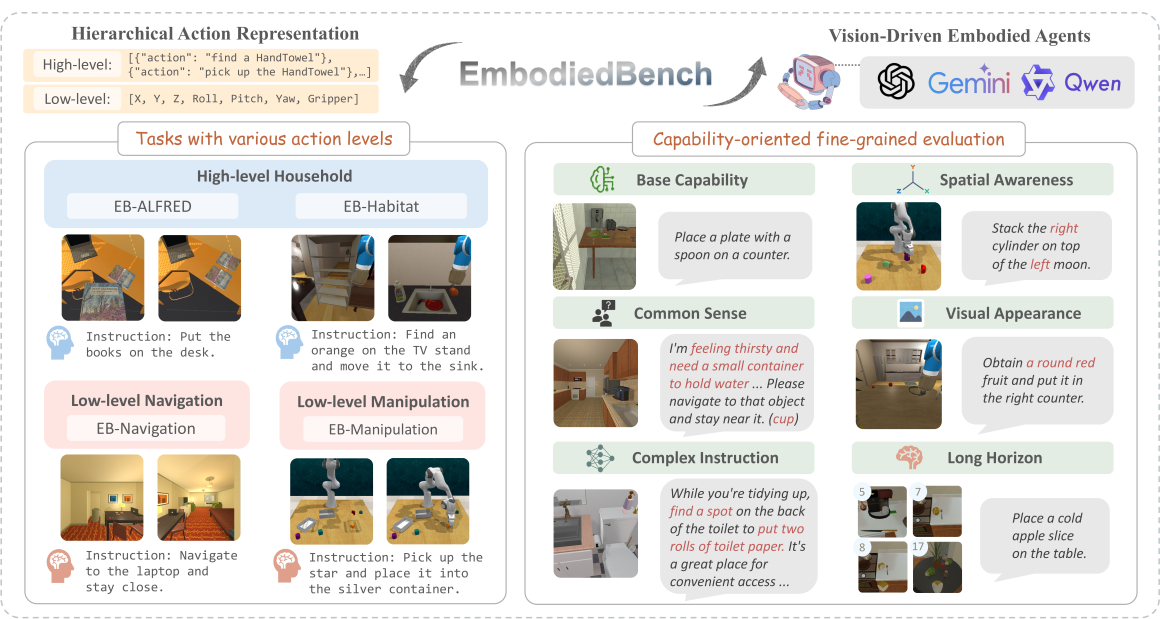
EmbodiedBench evaluates MLLM-based agents across 1,128 diverse embodied tasks, revealing that while models succeed at high-level planning, they struggle significantly with low-level manipulation and 3D spatial reasoning.
Core Problem
Existing benchmarks for embodied agents either focus only on high-level planning or specific modules, failing to evaluate how Multi-modal LLMs handle low-level vision-driven control (navigation, manipulation) and fine-grained capabilities.
Why it matters:
- Language-centric agents overlook the critical role of vision in low-level control, creating a blind spot in current evaluations.
- Without standardized evaluation for low-level actions, it is unclear if MLLMs can act as direct robotic controllers or only as high-level planners.
- Current benchmarks lack fine-grained diagnosis of specific failure modes like spatial awareness or long-horizon planning.
Concrete Example:
In a manipulation task like 'pick up the blue box', a high-level planner simply outputs 'pick(blue_box)', but a real robot needs a 7-dimensional vector [x, y, z, roll, pitch, yaw, gripper]. Current MLLMs fail to generate these precise continuous values even when given visual inputs.
Key Novelty
Multi-level Embodied Evaluation Framework
- Unifies evaluation across hierarchical action levels: from high-level semantic actions (e.g., 'slice apple') to low-level atomic actions (e.g., continuous joint control).
- Introduces 'Capability-Oriented' subsets: specifically isolates 6 skills (e.g., Spatial Awareness, Long-Horizon) rather than just measuring overall success rates.
- Deploys a standardized MLLM agent pipeline that integrates ego-centric vision, history, and feedback to fairly compare 24 distinct models.
Architecture

The unified MLLM agent pipeline for EmbodiedBench.
Evaluation Highlights
- Proprietary models dominate but struggle: GPT-4o achieves the highest average success rate of 28.9%, significantly outperforming open-source models but still failing >70% of tasks.
- Low-level manipulation is the hardest domain: GPT-4o scores only 20.3% on EB-Manipulation, compared to 52.3% on high-level EB-ALFRED tasks.
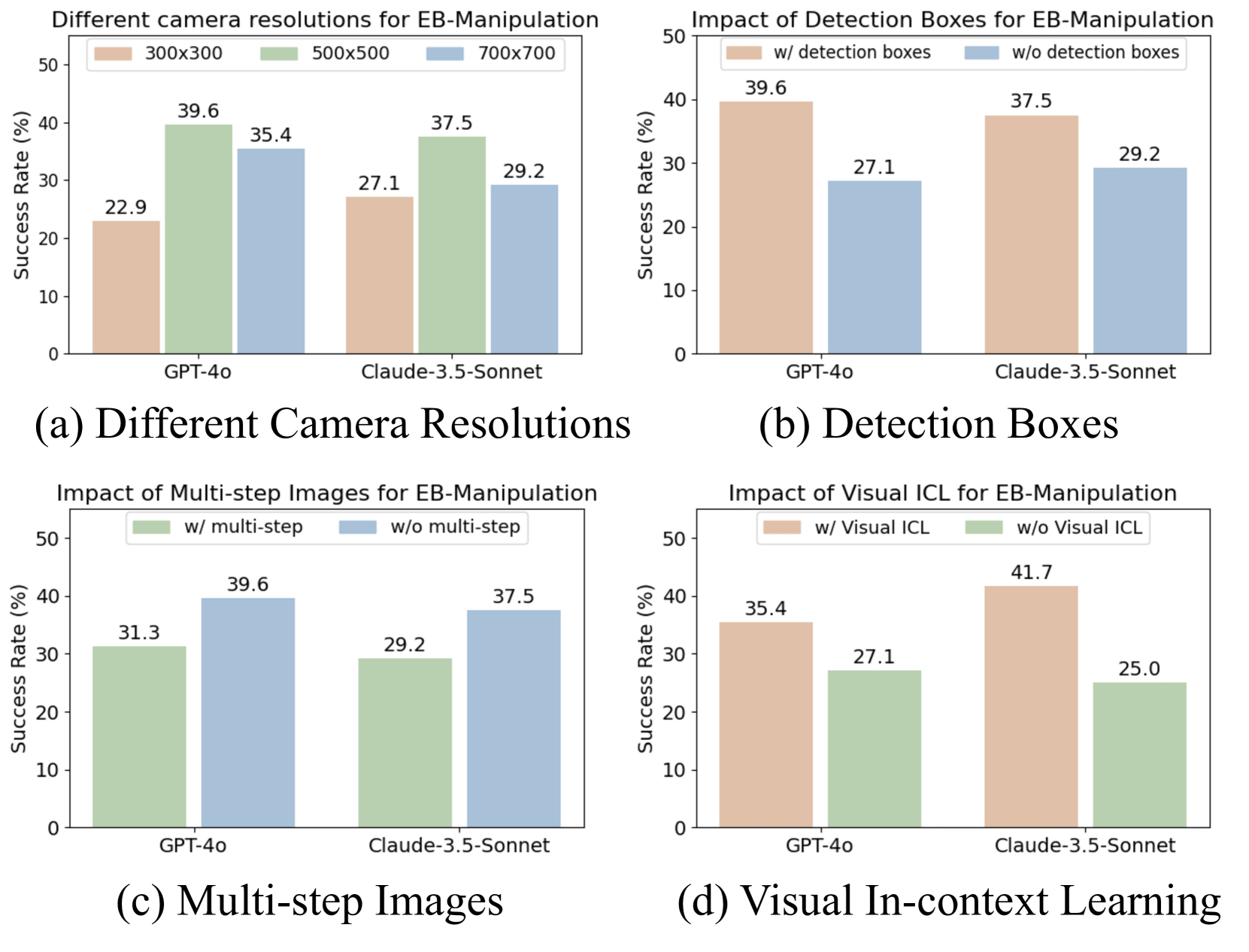
- Vision is critical for low-level tasks: Removing visual input drops performance by 40%-70% in navigation/manipulation, whereas high-level planning is minimally affected.
Breakthrough Assessment
8/10
A comprehensive, much-needed benchmark that exposes the severe limitations of current MLLMs in actual robotic control (low-level actions) versus abstract planning.