📝 Paper Summary
Multi-modal Large Language Models (MLLMs)
Video Understanding Benchmarks
MVBench evaluates MLLMs on 20 temporal video tasks defined via a static-to-dynamic transformation method, revealing significant gaps in current models that VideoChat2 aims to close.
Core Problem
Existing MLLM benchmarks primarily focus on spatial understanding in static images, failing to assess temporal evolution and procedural activities crucial for video understanding.
Why it matters:
- Current benchmarks (e.g., MMBench) rely on static image QA, missing dynamic context like movement direction or action sequences
- Prior video benchmarks (e.g., VideoChatGPT) are limited to basic tasks or specific domains, lacking comprehensive temporal skill assessment
- Heavy reliance on manual annotation makes scaling video benchmarks expensive and slow
Concrete Example:
A static image task asks 'Is the man on the stage?', which only requires spatial perception. The corresponding video task asks 'What direction is the man moving?', requiring reasoning about temporal changes over multiple frames.
Key Novelty
Static-to-Dynamic Task Definition & VideoChat2 Baseline
- Systematically defines 20 temporal video tasks by converting 9 static image tasks into dynamic versions (e.g., 'Position' becomes 'Moving Direction')
- Automated QA generation pipeline converts 11 public video datasets into multiple-choice questions using LLMs, ensuring ground-truth accuracy without manual labeling
- Introduces VideoChat2, a strong baseline trained progressively with diverse instruction data (2M samples) to bridge the temporal understanding gap
Architecture
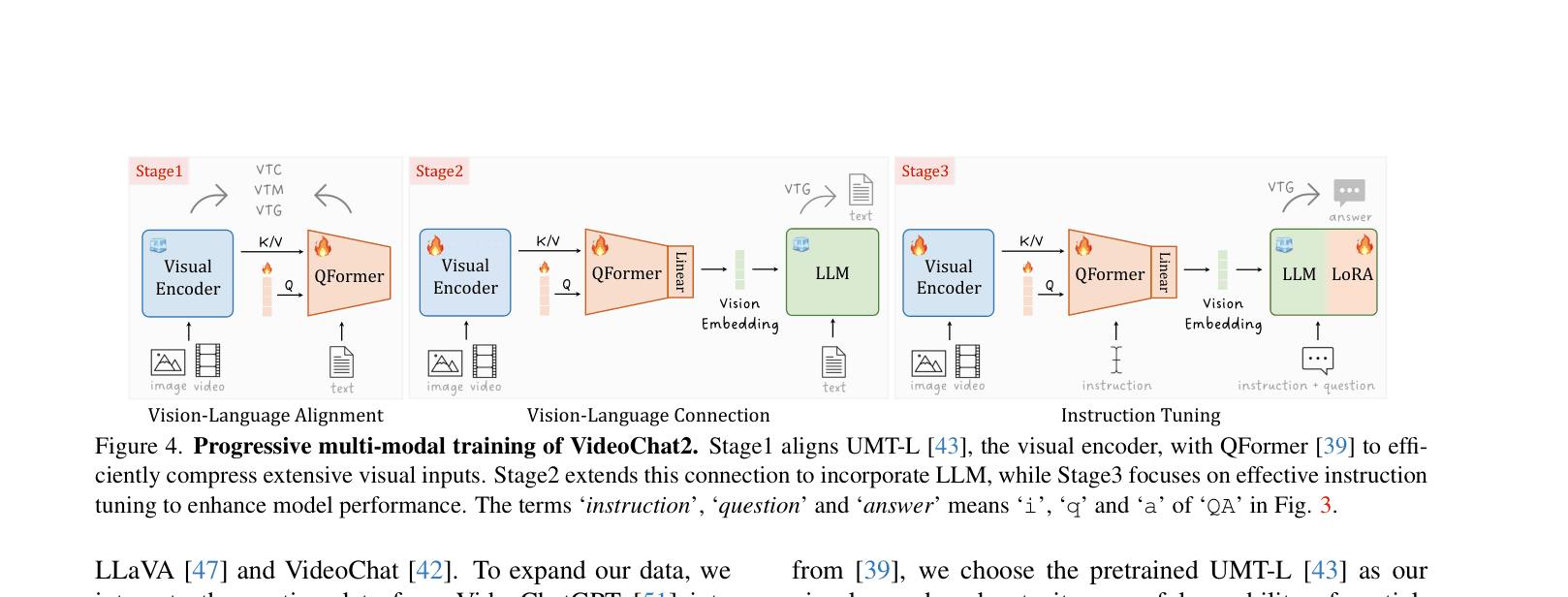
The progressive training pipeline of VideoChat2, detailing three stages of alignment and tuning.
Evaluation Highlights
- VideoChat2 achieves 51.1% average accuracy on MVBench, surpassing the previous best open-source model (VideoChat) by >15%
- VideoChat2 outperforms GPT-4V (43.5%) by 7.6% on MVBench average accuracy
- On the ActivityNet zero-shot QA benchmark, VideoChat2 achieves 49.1% accuracy, surpassing VideoChatGPT (35.2%) by ~14%
Breakthrough Assessment
8/10
Significantly advances video MLLM evaluation by focusing specifically on temporal tasks often ignored by image-based benchmarks. The proposed model establishes a strong new SOTA.
