📝 Paper Summary
Vision-Language Alignment
Data Engineering for Multi-Modal Models
ShareGPT4V introduces a large-scale dataset of highly descriptive captions generated by GPT4-Vision and a specialized captioner, demonstrating that high-quality textual descriptions significantly improve multi-modal model performance compared to standard brief captions.
Core Problem
Existing Large Multi-Modal Models (LMMs) suffer from sub-optimal modality alignment because mainstream image-text datasets use simplistic, brief captions that lack fine-grained semantics and world knowledge.
Why it matters:
- Vision is inherently rich in information, but standard short captions (like COCO) reduce this richness to simple object lists, losing spatial, aesthetic, and attribute details.
- Brief captions constrain the model's ability to align visual features with complex language understanding, limiting performance on tasks requiring detailed reasoning or world knowledge.
- Prior data enhancement methods (like LaCLIP) rely on text-only LLMs to hallucinate details from short captions rather than 'seeing' the image, leading to inaccuracies.
Concrete Example:
A standard dataset might describe the Eiffel Tower simply as 'a tall iron tower' or a picture of Einstein as 'an old man.' ShareGPT4V, by contrast, includes the specific name, location, historical context, and aesthetic qualities, enabling the model to learn specific world knowledge.
Key Novelty
ShareGPT4V Dataset and Captioner
- Uses GPT4-Vision with data-specific prompts to generate 100K highly descriptive captions covering world knowledge, spatial relations, and aesthetics.
- Trains a specialized 'Share-Captioner' on this high-quality subset to efficiently scale up caption generation to 1.2 million images.
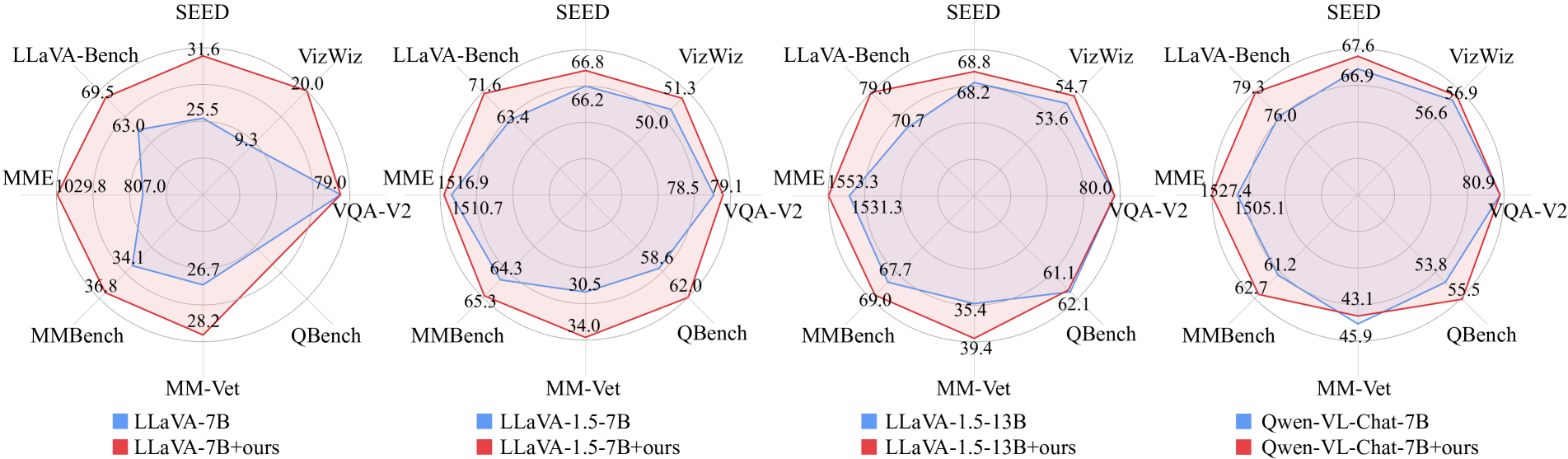
- Demonstrates that substituting even a small fraction of SFT data with these detailed captions yields significant performance gains across benchmarks.
Architecture

The ShareGPT4V-7B architecture, identical to LLaVA-1.5
Evaluation Highlights
- +36.1 points improvement on MME perception benchmark compared to LLaVA-1.5-13B, despite using a smaller 7B model.
- Achieves 68.8% accuracy on MMBench, surpassing the second-best model by 1.1%.
- Surpasses Qwen-VL-Chat-7B (trained on 1.4 billion samples) by 95.6 points on the MME benchmark total score.
Breakthrough Assessment
9/10
Significantly advances LMM performance purely through data quality rather than architectural changes. The release of 1.2M high-quality captions resolves a major bottleneck in vision-language alignment.