📝 Paper Summary
Multi-modal Large Language Models (MLLMs)
Video Understanding Benchmarks
Video-MME is a comprehensive benchmark for evaluating multi-modal large language models on video analysis tasks across diverse domains, varying durations (11s to 1 hour), and multiple modalities (video, audio, subtitles).
Core Problem
Existing video benchmarks for Multi-modal Large Language Models (MLLMs) lack diversity in video types, fail to cover varying temporal durations (especially long videos), and often ignore audio/subtitle modalities.
Why it matters:
- Current evaluations focus heavily on static images or short clips, failing to test MLLMs on real-world long-form sequential data
- Ignoring audio and subtitles limits the assessment of a model's true multimodal understanding capabilities
- The lack of high-quality, diverse annotations for long videos hinders the development of models capable of complex temporal reasoning
Concrete Example:
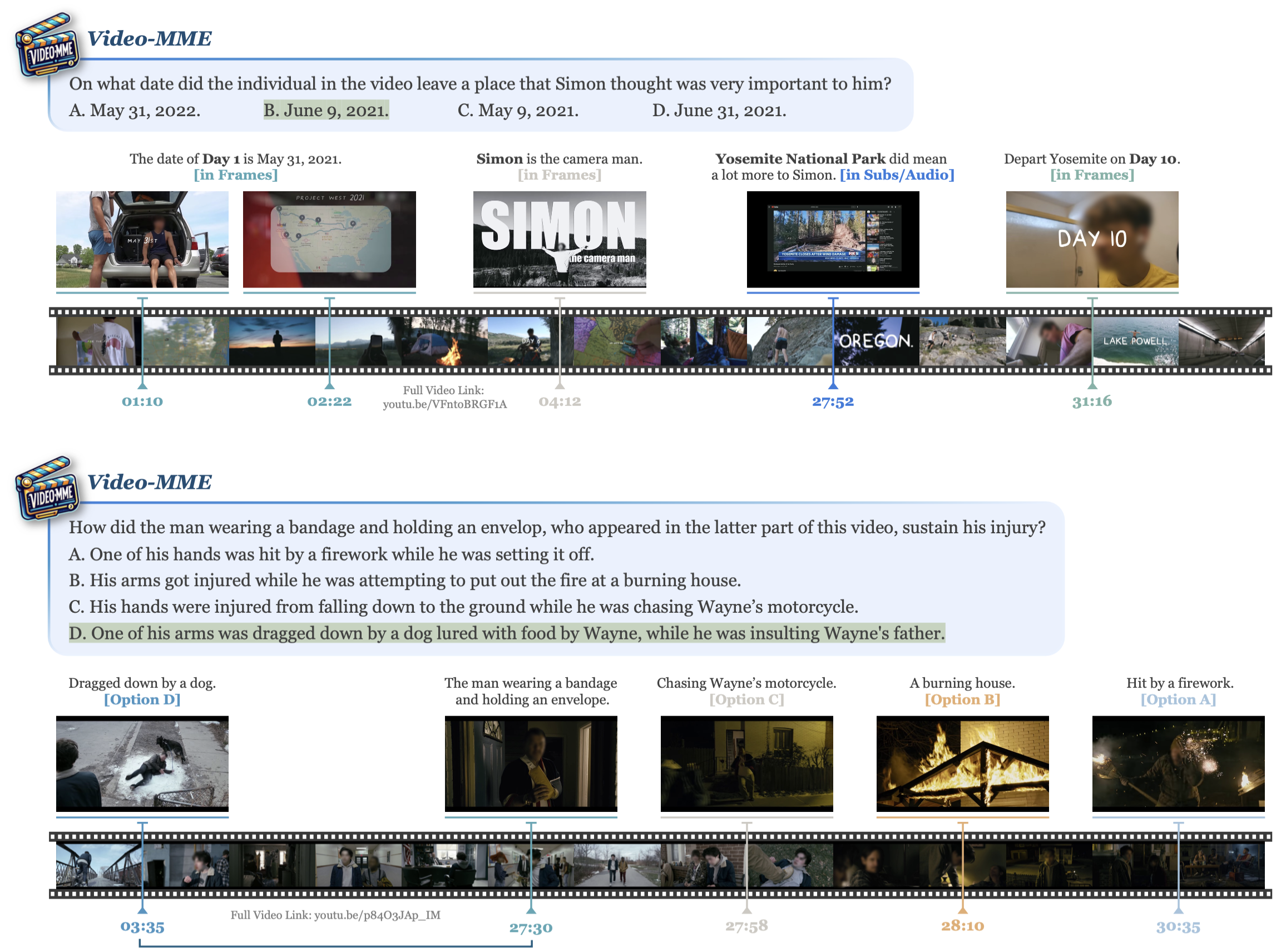
A question asking for the 'departure date' in a travel vlog might require reading a text overlay ('May 31') and listening to audio narration ('Day 1') simultaneously. Existing benchmarks might only provide the visual frames, making the question unanswerable, or use short clips where such context is cut off.
Key Novelty
Video-MME (Multi-Modal Evaluation benchmark)
- Constructs a dataset of 900 videos spanning varied durations (short, medium, long) and 6 diverse domains to test generalization
- Integrates multi-modal inputs explicitly: evaluates performance with and without subtitles/audio to measure their contribution
- Uses 'certificate length' analysis to ensure questions require digesting significant portions of the video, preventing shortcuts
Architecture
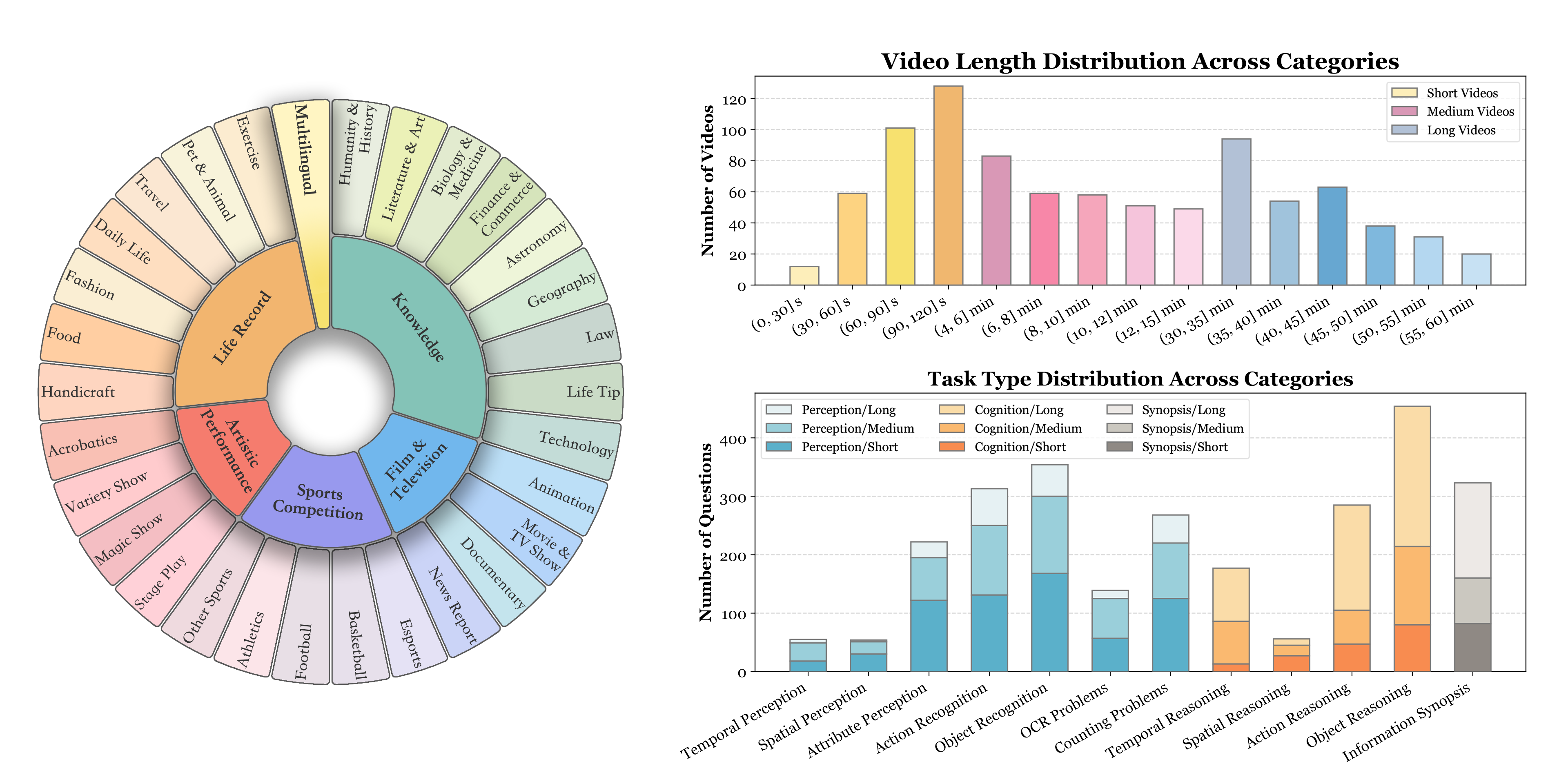
The data construction statistics and hierarchy, illustrating the domain distribution and duration breakdown.
Evaluation Highlights
- Gemini 1.5 Pro achieves 81.3% accuracy with subtitles, significantly outperforming GPT-4o (77.2%) and open-source models
- Integrating subtitles and audio boosts Gemini 1.5 Pro's performance by 6.2% and 4.3% respectively, with larger gains in longer videos
- Performance drops as video length increases: Gemini 1.5 Pro drops from 81.7% on short videos to 67.4% on long videos (without subtitles)
Breakthrough Assessment
9/10
Sets a new standard for video MLLM evaluation by addressing the critical gap in long-context and multi-modal (audio/subtitle) assessment. The rigorous manual annotation and 'certificate length' validation make it highly robust.