📝 Paper Summary
Multimodal Evaluation Benchmark
Vision-Language Models (VLMs)
MMBench is a comprehensive bilingual benchmark with over 3,000 multi-choice questions that uses a circular evaluation strategy and ChatGPT-assisted answer extraction to robustly assess vision-language models.
Core Problem
Existing VLM benchmarks suffer from false negatives due to exact matching requirements, lack fine-grained ability analysis, and subjective human evaluations are non-scalable and biased.
Why it matters:
- Traditional metrics (e.g., VQAv2 accuracy) penalize correct answers phrased differently (e.g., 'bicycle' vs 'bike'), obscuring true model capability.
- Subjective evaluations (e.g., OwlEval) are expensive and hard to reproduce, while objective benchmarks often fail to measure instruction-following limitations accurately.
- Lack of standardized bilingual benchmarks prevents fair apples-to-apples comparison of VLMs in English and Chinese contexts.
Concrete Example:
In VQA, if the reference answer is 'bike' but a model predicts 'bicycle', standard metrics assign a negative score. Similarly, models with poor instruction following might output 'the meaning of choice A' instead of just 'A', causing rule-based matching to fail even if the reasoning is correct.
Key Novelty
MMBench: Robust Bilingual Circular Evaluation
- Introduces CircularEval: Feeds the same multiple-choice question to the VLM multiple times with shuffled choices to ensure the model actually knows the answer rather than guessing based on position bias.
- Uses LLM-based Choice Extraction: Instead of rigid rule-based matching, employs GPT-4 to map free-form VLM predictions to specific multiple-choice options, salvaging correct answers from models with weak instruction-following.
Architecture
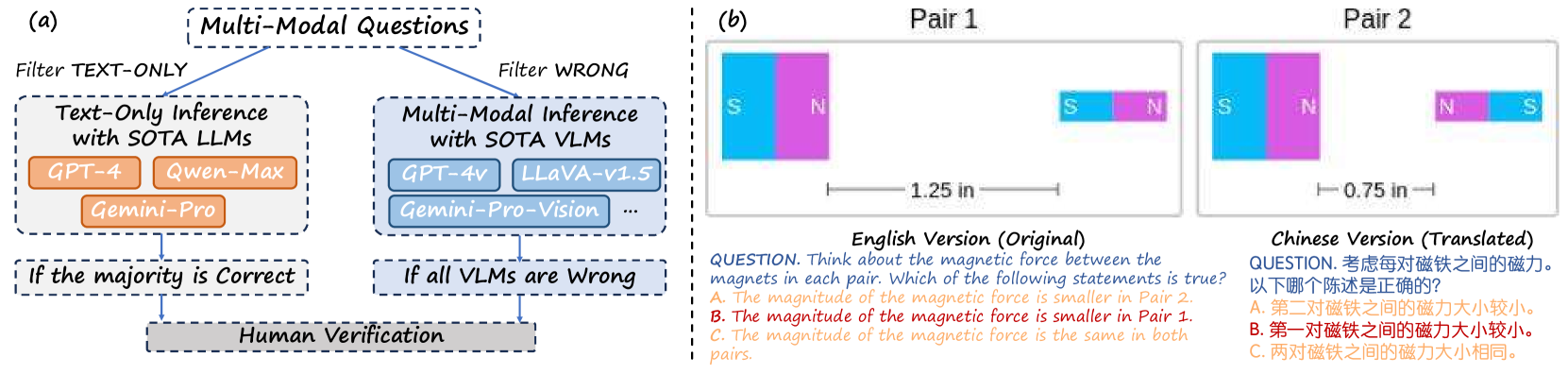
The pipeline for data construction and evaluation strategy, specifically highlighting the filtering process and the choice extraction flow.
Evaluation Highlights
- GPT-4-based choice matching aligns with human assessment in 91.5% of cases, significantly reducing false negatives compared to traditional exact matching.
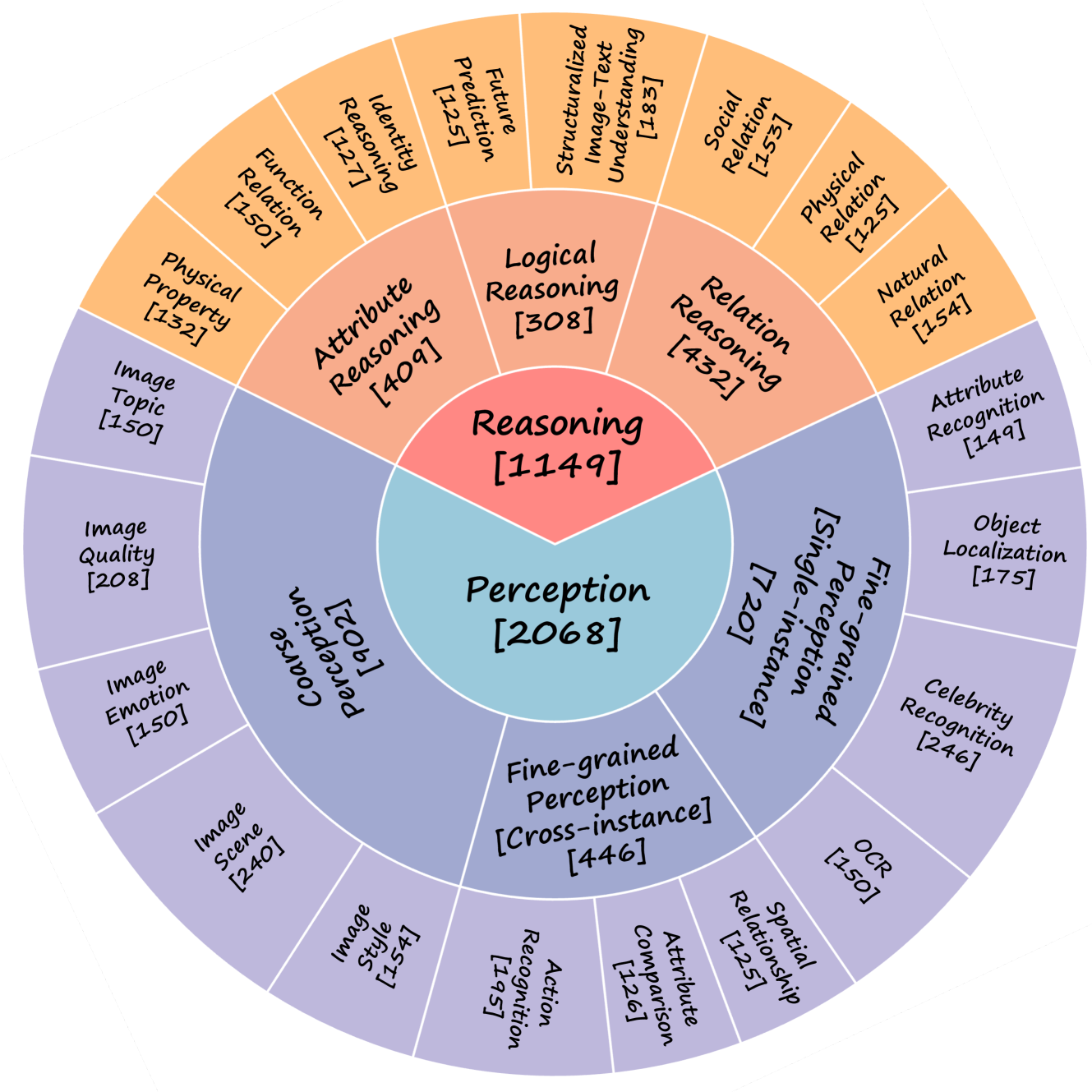
- Constructed a dataset of 3,217 questions covering 20 fine-grained abilities (e.g., object localization, social reasoning) with rigorous quality control involving LLM voting and manual verification.
- Evaluates 21 major vision-language models, revealing that proprietary models (like GPT-4v) generally outperform open-source ones, though instruction-following varies significantly.
Breakthrough Assessment
8/10
Significantly improves VLM evaluation robustness by addressing the 'exact match' problem and position bias. The integration of CircularEval and LLM-based extraction is a practical methodological advance for the field.