📝 Paper Summary
Vision-Language Reinforcement Learning
Visual Reasoning
Open-Vocabulary Object Detection
VLM-R1 adapts the DeepSeek-R1 reinforcement learning paradigm to Vision-Language Models, demonstrating that simple rule-based rewards on deterministic visual tasks significantly improve reasoning and generalization on out-of-domain benchmarks.
Core Problem
Vision-Language Models (VLMs) often lag behind specialized vision models in precise visual understanding tasks like object detection, and standard Supervised Fine-Tuning (SFT) struggles to generalize to complex, reasoning-intensive out-of-domain scenarios.
Why it matters:
- VLMs possess rich world knowledge but lack the precise localization capabilities of specialized models like Grounding DINO
- SFT models often plateau or degrade on hard reasoning tasks outside their training distribution
- Extending the success of 'aha moments' and RL-based reasoning from text (DeepSeek-R1) to vision is a key open research direction
Concrete Example:
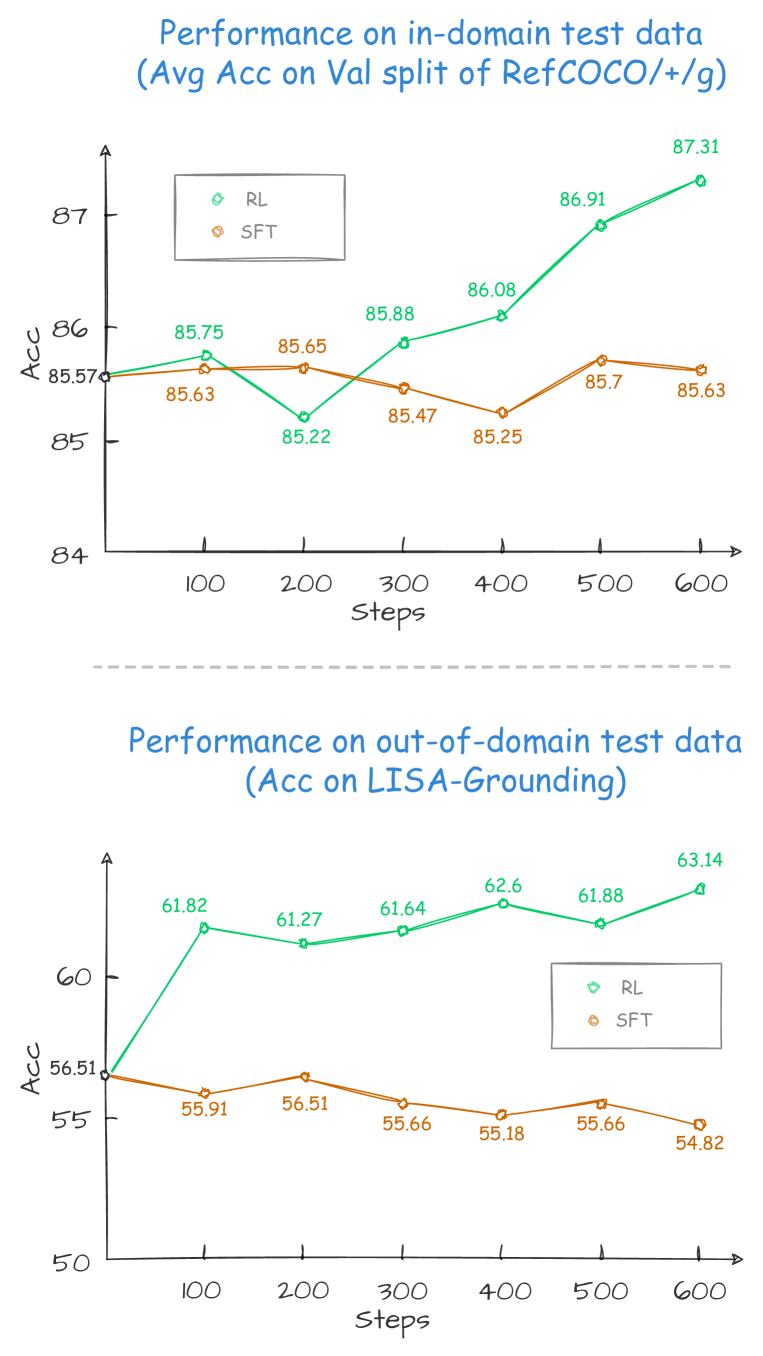
In Referring Expression Comprehension, an SFT-trained VLM might correctly identify a 'car' in a simple image but fail to localize 'the red car next to the fire hydrant' in a complex scene (LISA-Grounding benchmark), whereas the RL-trained model learns to reason about relationships before outputting the box.
Key Novelty
VLM-R1 Framework (Visual R1-style RL)
- Adapts the GRPO (Group Relative Policy Optimization) algorithm to VLMs, utilizing tasks with deterministic ground-truth (like bounding boxes) to provide stable rule-based rewards without a learned reward model
- Implements specific reward functions for visual tasks: IoU-based rewards for Referring Expression Comprehension and a combination of mAP/format/length rewards for Open-Vocabulary Object Detection
Architecture
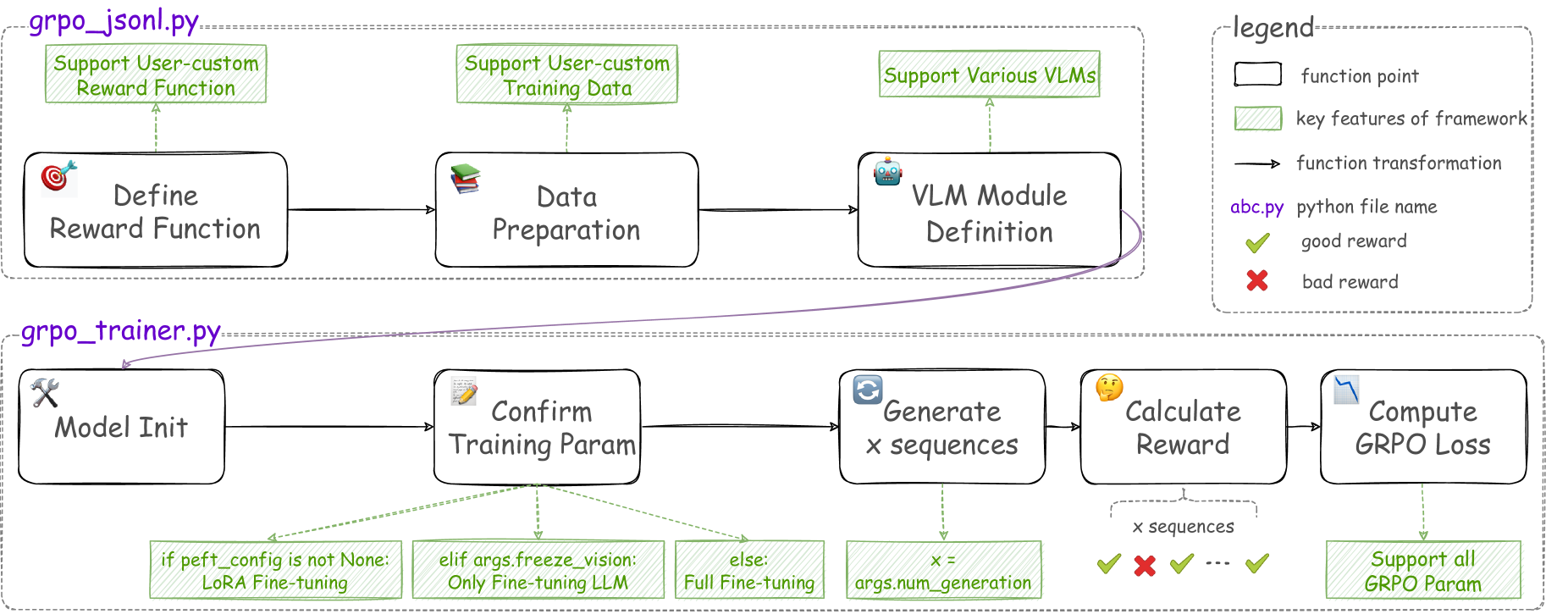
The overall VLM-R1 framework pipeline, detailing the two-stage process: data/reward preparation and GRPO training.
Evaluation Highlights
- +8.34 point improvement on the LISA-Grounding out-of-domain benchmark (63.16 vs 54.82) compared to SFT using Qwen2.5-VL-3B
- +4.51 point improvement in NMS-AP on OVDEval (31.01 vs 26.50) compared to SFT, setting a new SOTA for the 3B scale
- VLM-R1 (3B) outperforms the larger Qwen2.5-VL-7B baseline on OVDEval (31.01 vs 29.08), showing RL can bridge model size gaps
Breakthrough Assessment
8/10
Significantly demonstrates the viability of R1-style RL for vision tasks, observing 'aha moments' in object detection and strong out-of-domain generalization. Provides a fully open-source framework for VLM RL research.