📝 Paper Summary
Vision-Language Reinforcement Learning (RL)
Synthetic Data Generation
Visual Reasoning
Game-RL utilizes video games to synthesize verifiable, multimodal reasoning tasks, enabling Vision Language Models to improve general reasoning capabilities through reinforcement learning on these synthetic game scenarios.
Core Problem
Vision Language Models (VLMs) struggle with complex multi-step reasoning, partially because current Vision-Language RL training is limited to narrow domains like geometry and charts.
Why it matters:
- Existing RL datasets lack the diversity needed for broad generalization, limiting VLM exploration and learning.
- Real-world reasoning tasks are complex and difficult to verify automatically, whereas games offer verifiable mechanics.
- Simply evaluating VLMs on games (as done in prior work) misses the opportunity to use games as a rich training ground for reasoning skills.
Concrete Example:
In a game like Sokoban, a model must predict where a player ends up after a specific sequence of moves (e.g., 'left, up, down'). Standard VLMs might hallucinate the final position because they lack grounded spatial reasoning training, whereas a game engine can deterministically verify the correct coordinate (2,2).
Key Novelty
Code2Logic: Transforming Game Code into Reasoning Logic
- Uses LLMs to adapt actual game source code into a 'data engine' that procedurally generates game states, reasoning questions, and verifiable ground-truth answers.
- Constructs a massive dataset (GameQA) of 30 games and 158 tasks with controllable difficulty, covering spatial perception, planning, and pattern recognition.
- Demonstrates that RL training on these synthetic game tasks transfers to improvements on unrelated general vision-language benchmarks.
Architecture
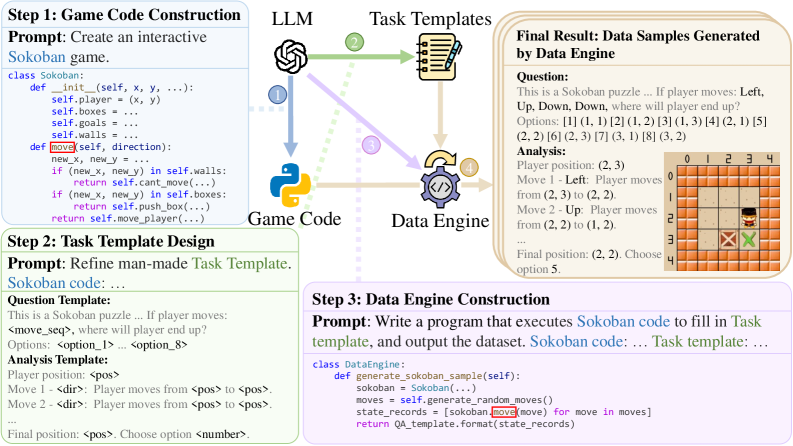
The Code2Logic pipeline: Steps to synthesize game data. (1) Construct Game Code, (2) Design Task Templates, (3) Build Data Engine.
Evaluation Highlights
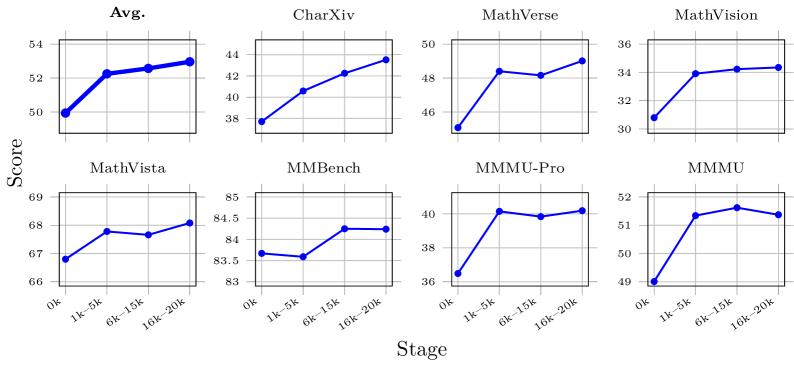
- +2.33% average improvement for Qwen2.5-VL-7B across 7 diverse vision-language benchmarks (e.g., MMMU, MathVista) after training solely on GameQA.
- GameQA-trained models outperform geometry-trained baselines (MAVIS, Multimodal-Open-R1) on general benchmarks despite using fewer training samples (5k vs 8k).
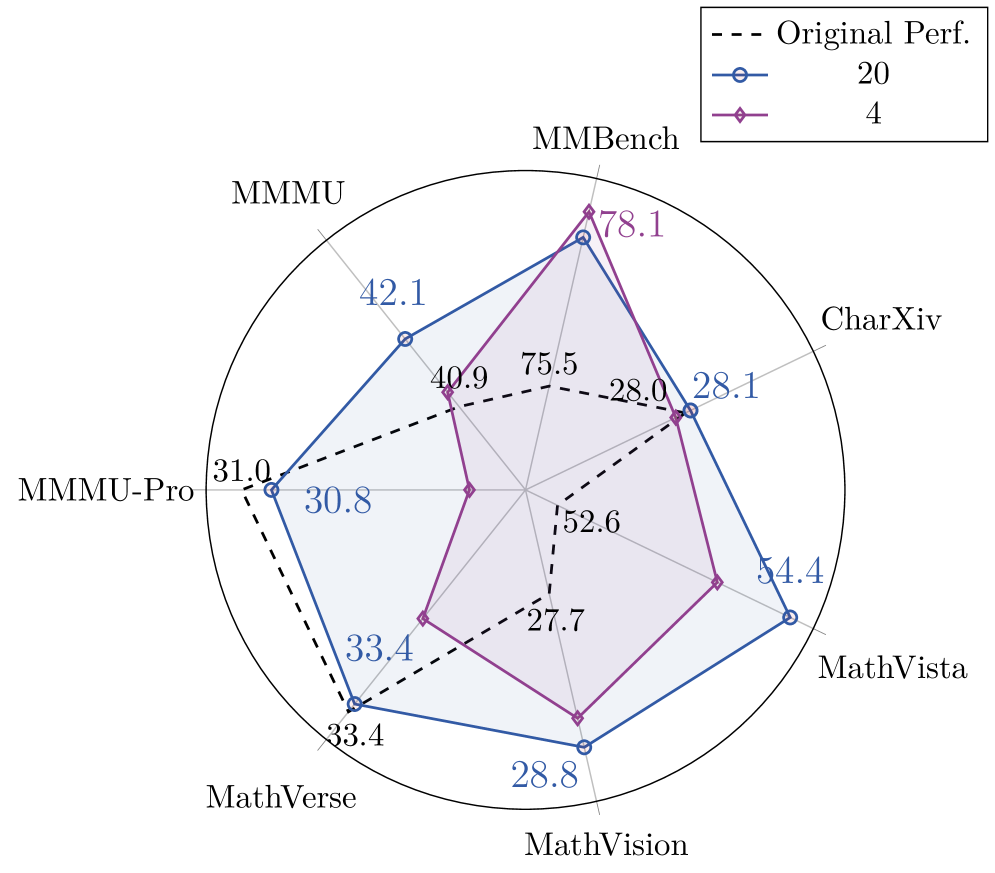
- Scaling game diversity from 4 to 20 games correlates positively with generalization performance on downstream tasks.
Breakthrough Assessment
8/10
Strong evidence that synthetic game data improves out-of-domain general reasoning, a significant finding for scaling VLM post-training data. The automated pipeline (Code2Logic) effectively solves the data verification bottleneck.