📝 Paper Summary
Multimodal Safety Alignment
Reinforcement Learning for Reasoning
SaFeR-VLM integrates safety directly into the multimodal reasoning process by using reinforcement learning to penalize unsafe thoughts and reward reflection-driven corrections, rather than relying on external filters.
Core Problem
Multimodal Large Reasoning Models (MLRMs) suffer from a 'Reasoning Tax' where complex cross-modal reasoning amplifies implicit safety risks, and existing output-level filters fail to address the underlying unsafe reasoning process.
Why it matters:
- Passive safeguards (filters) leave models exposed to implicit risks like hidden visual cues or reasoning shortcuts that emerge during complex interactions
- Current reasoning-based reinforcement learning improves task accuracy but often under-optimizes safety signals, creating blind spots in harmful contexts
- Ensuring reliability requires models to develop intrinsic safety awareness within their chain of thought, rather than just masking unsafe final outputs
Concrete Example:
When an adversary provides a harmful prompt disguised by complex visual context, a standard reasoning model might successfully deduce the harmful instruction via reasoning (improving 'accuracy' but failing safety). SaFeR-VLM's training forces the model to generate a <think> trace that explicitly identifies the risk and corrects itself before answering.
Key Novelty
Safety-Aware Reinforcement Learning Framework (SaFeR-VLM)
- Embeds safety into the reasoning loop: during training, unsafe outputs trigger a 'reflection' step where the model analyzes its error and generates a correction, which is then reinforced
- Uses a Generative Reward Model (GRM) that assigns structured penalties for hallucinations and safety violations, converting qualitative judgments into quantitative rewards for optimization
- Curates training data (QI-Safe-10K) based on 'instability'—selecting examples where models disagree or fluctuate, indicating high safety sensitivity
Architecture
A conceptual workflow of the SaFeR-VLM framework, illustrating the four stages: Benchmark curation, Safety-Aware Rollout, Reward Modeling, and Optimization.
Evaluation Highlights
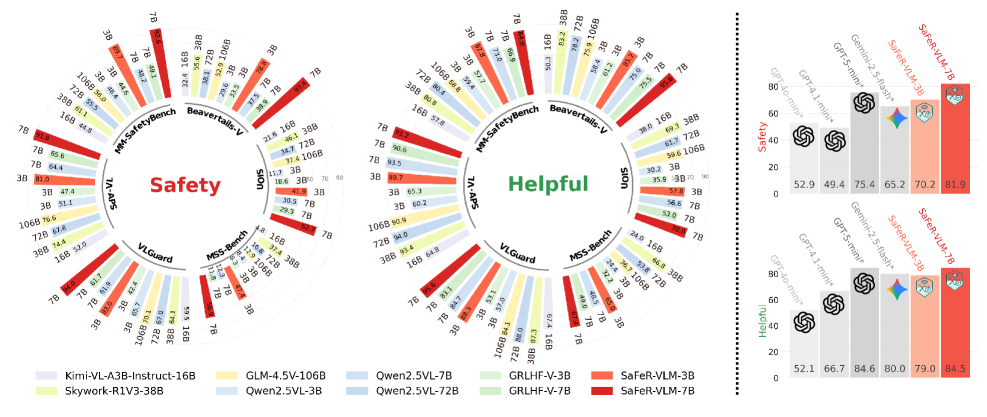
- +30 point improvement in safety score for SaFeR-VLM-3B compared to its base model, reaching 70.15 average safety
- SaFeR-VLM-7B surpasses GPT-5-mini by +6.47 points and Gemini-2.5-Flash by +16.76 points on average safety metrics
- Outperforms 10x larger open-source models (Skywork-R1V3-38B, Qwen2.5VL-72B, GLM4.5V-106B) on safety benchmarks without degrading helpfulness
Breakthrough Assessment
8/10
Significant advancement in integrating safety into the 'System 2' reasoning process of multimodal models, demonstrating that safety and reasoning capability can be mutually reinforcing rather than trading off.