📝 Paper Summary
Synthetic Data Generation
Tabular Deep Learning
Tabby modifies transformer LLMs by replacing standard layers with column-specific Mixture-of-Experts blocks, enabling high-fidelity tabular data synthesis when combined with a simplified 'Plain' training method.
Core Problem
Existing LLM-based tabular synthesis methods require complex preprocessing or permutation schemes and struggle to model column interdependencies, while non-LLM methods (GANs, Diffusion) often fail on mixed-type data.
Why it matters:
- Tabular data is ubiquitous (healthcare, finance, logs) but under-researched compared to text/images
- Creating a 'Large Tabular Model' from scratch is resource-prohibitive due to data scarcity and compute costs
- Prior adaptations of LLMs to tables treat columns as generic text, failing to capture specific statistical properties of distinct features
Concrete Example:
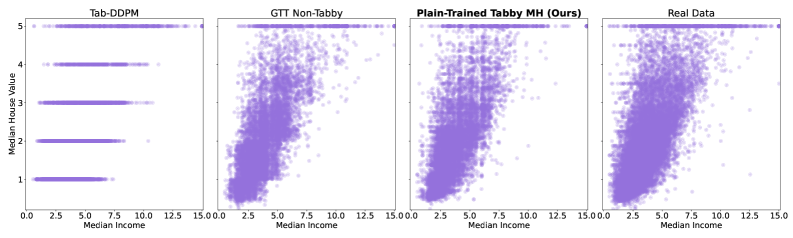
In the Rainfall dataset, prior SOTA LLM methods (GReaT) fail to produce any valid samples in 3/3 runs, while diffusion models like Tab-DDPM cannot model non-integer regression targets, distorting the distribution.
Key Novelty
Column-Specific Mixture-of-Experts (Tabby) + Simplified Serialization (Plain)
- Replaces specific LLM layers (e.g., the language head) with a Mixture-of-Experts block where each 'expert' is dedicated to a single column in the table
- Uses a deterministic gating function that routes tokens to the expert corresponding to the current column being generated
- Introduces 'Plain' training: a simple serialization format (Value is Value <EOC>) without the complex permutations or conditioning used in prior works like GReaT
Architecture
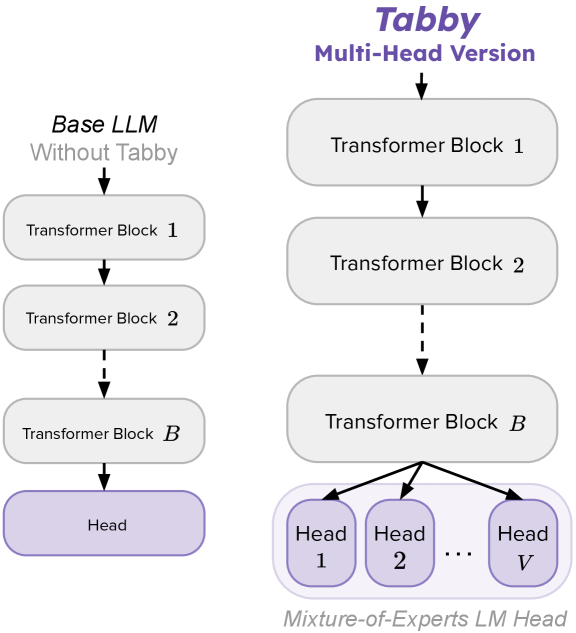
Comparison of Standard LLM vs. Tabby LLM architecture. Shows how specific blocks (like the LM Head) are replaced by a bank of experts.
Evaluation Highlights
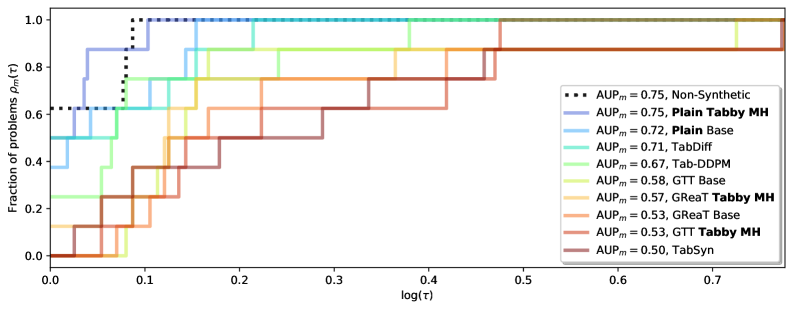
- Achieves parity with real data (Machine Learning Efficacy score) on 5 out of 8 datasets, effectively serving as a drop-in replacement
- Outperforms the prior SOTA diffusion model (TabDiff) and LLM method (GTT) in aggregate Area Under Performance Profile (AUP) score
- Small Tabby models (Distilled-GPT2, ~82M params) outperform much larger non-Tabby Llama-3-8B models on tabular synthesis tasks
Breakthrough Assessment
8/10
Significantly simplifies LLM tabular training while beating complex diffusion and GAN baselines. The architectural modification is elegant and enables small models to punch well above their weight.