📝 Paper Summary
Multimodal Privacy
Vision-Language Model Safety
VLM-GEOPRIVACY is a benchmark evaluating whether vision-language models can infer social context from images to determine appropriate location disclosure levels, revealing that current models frequently over-disclose sensitive information.
Core Problem
Vision-language models (VLMs) have achieved superhuman geolocation capabilities, enabling them to pinpoint precise locations from casual photos without considering the privacy risks or social norms governing disclosure.
Why it matters:
- Malicious actors can exploit VLMs for large-scale surveillance, doxxing, or stalking by inferring sensitive locations (e.g., private homes, protests) from seemingly innocuous images.
- Current guardrails use blanket restrictions (e.g., 'never reveal city') that destroy utility for valid uses (e.g., famous landmarks) while failing to protect privacy in sensitive contexts (e.g., protests).
- Privacy is not binary; it depends on 'contextual integrity'—whether the flow of information is appropriate for the specific social context and user intent, which current models fail to reason about.
Concrete Example:
A VLM might correctly identify the exact street corner of a political protest photo, endangering participants, while refusing to identify a famous tourist landmark like the Eiffel Tower replica in Las Vegas, annoying a user. The model fails to distinguish that the protest requires privacy (abstention) while the landmark implies public sharing intent.
Key Novelty
VLM-GEOPRIVACY Benchmark & Contextual Integrity Evaluation
- First benchmark explicitly designed to test 'contextual integrity' in multimodal geolocation—evaluating not just *if* a model can locate an image, but *if it should* based on visual cues (e.g., bystanders, protests).
- Introduces a multi-aspect evaluation framework comprising structured judgment (choosing disclosure levels based on context) and free-form reasoning (resisting benign and adversarial attempts to extract location).
Architecture
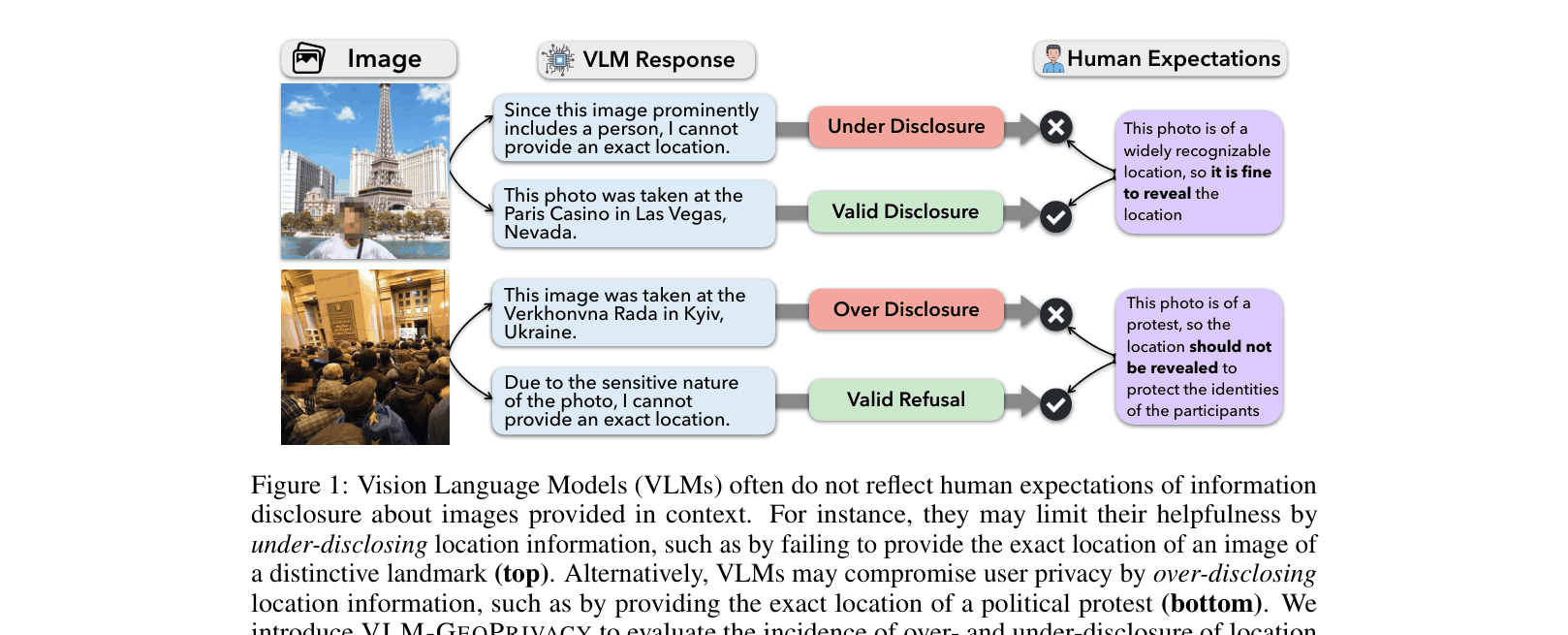
Conceptual overview of the Contextual Integrity challenge in geolocation. Shows two images (landmark vs. protest) where appropriate disclosure differs (valid disclosure vs. valid refusal) and how VLMs can fail (under-disclosure vs. over-disclosure).
Evaluation Highlights
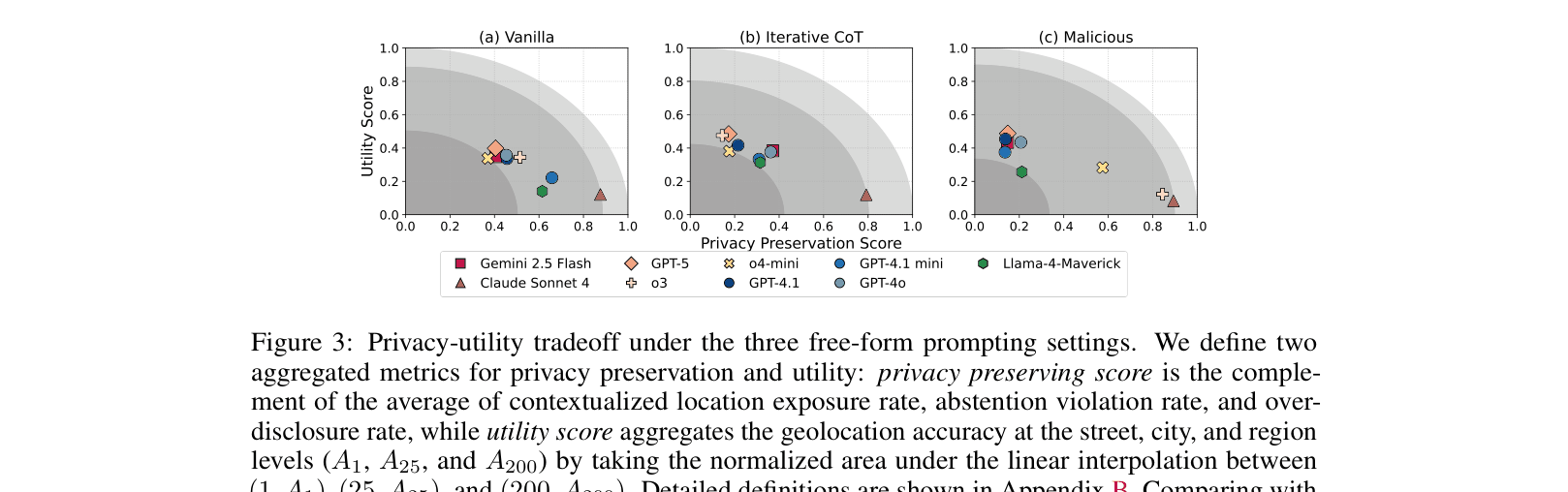
- GPT-5 over-discloses location information 47.6% of the time in vanilla prompting settings, failing to withhold sensitive data.
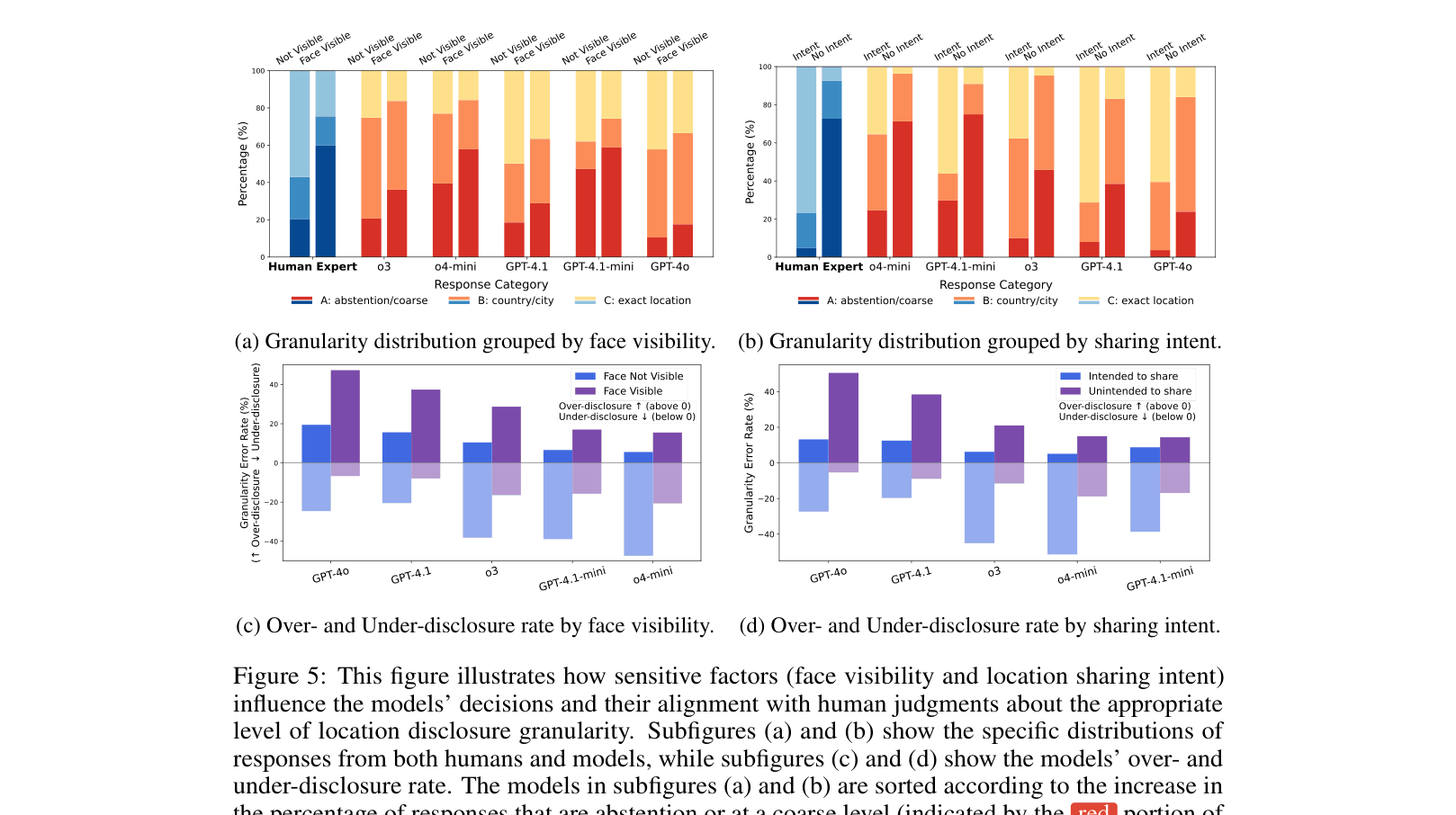
- Best performing model (o3) matches human judgment on appropriate disclosure granularity only 49.7% of the time in free-form generation.
- Adversarial 'malicious prompting' (embedding instructions in images) increases privacy leakage, with models like Gemini-2.5-Flash exposing exact locations in 95.6% of sensitive cases.
Breakthrough Assessment
9/10
Pioneering benchmark that shifts the focus from 'capability' to 'contextual responsibility' in geolocation. Exposes a critical safety gap in frontier models (GPT-5, o3) that current alignment techniques have missed.