📊 Experiments & Results
Evaluation Setup
Zero-shot visual question answering on IQ puzzles
Benchmarks:
- VRIQ (Visual IQ Test (Abstract & Natural)) [New]
Metrics:
- End-to-End Accuracy
- P-only Failure Rate (Perception Bottleneck)
- R-only Failure Rate (Reasoning Deficit)
- P+R Failure Rate (Combined Failure)
- Statistical methodology: 95% confidence intervals reported for human performance baseline
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Overall performance of VLMs (averaged across models) shows significant deficits compared to human capability and reveals perception as the primary bottleneck. | ||||
| VRIQ (Abstract) | Average Accuracy | 25.00 | 28.00 | +3.00 |
| VRIQ (Natural) | Average Accuracy | 28.00 | 45.00 | +17.00 |
| VRIQ (Aggregate Failures) | Share of Failures (Perception Only) | 0.00 | 56.00 | +56.00 |
| VRIQ (Aggregate Failures) | Share of Failures (Reasoning Only) | 0.00 | 1.00 | +1.00 |
Experiment Figures
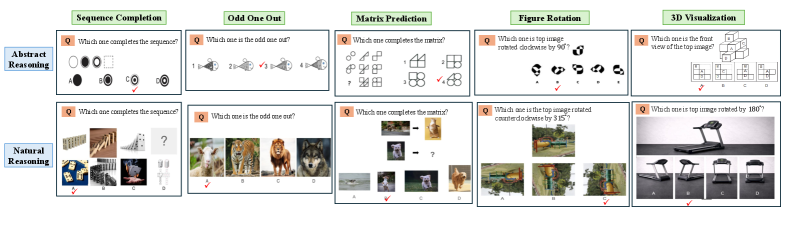
Paired examples of Abstract and Natural puzzles across the five reasoning categories (Sequence, Matrix, Odd One Out, Rotation, 3D)
Main Takeaways
- Perception is the dominant failure mode: VLMs struggle to count, identify shapes, and determine 3D orientation reliably, which prevents them from even attempting the reasoning step.
- Tool-augmented reasoning (OpenAI o3) provides only modest improvements, suggesting that current tools do not sufficiently bridge the raw perception gap.
- Models perform significantly better on Natural images than Abstract ones, likely due to the dominance of natural images in pre-training data.
- Fine-grained analysis reveals specific perception categories (e.g., 3D/depth, rotation) cause more failures than simple color/shape identification.