📊 Experiments & Results
Evaluation Setup
Controlled generation of synthetic tasks evaluating memory capabilities.
Benchmarks:
- Minerva Memory Test (Search) (Information Retrieval) [New]
- Minerva Memory Test (Recall and Edit) (Content Transfer and Synthesis) [New]
- Minerva Memory Test (Match and Compare) (Processing and Basic Reasoning) [New]
- Minerva Memory Test (Stateful Processing) (Complex State Tracking) [New]
Metrics:
- Exact Match Accuracy
- ROUGE-L
- Jaccard Similarity
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Search tasks show that while most models handle simple retrieval well, subsequence search (finding multi-word phrases) remains challenging. | ||||
| String Search (Subsequence) | Accuracy | 0.55 | 0.90 | +0.35 |
| Recall and Edit tasks reveal that functional updates (applying a rule to change data) are much harder than simple recall. | ||||
| Functional Update | ROUGE-L | 1.00 | 0.80 | -0.20 |
| Stateful Processing tasks show the most dramatic separation between proprietary SOTA models and open weights. | ||||
| Quantity State Tracking | Accuracy | 0.00 | 1.00 | +1.00 |
| Set State Tracking | Jaccard | Not applicable | 0.68 | - |
| Composite tests cause performance to collapse across all models compared to atomic baselines. | ||||
| Theory of Mind | Accuracy | 0.68 | 0.45 | -0.23 |
Experiment Figures
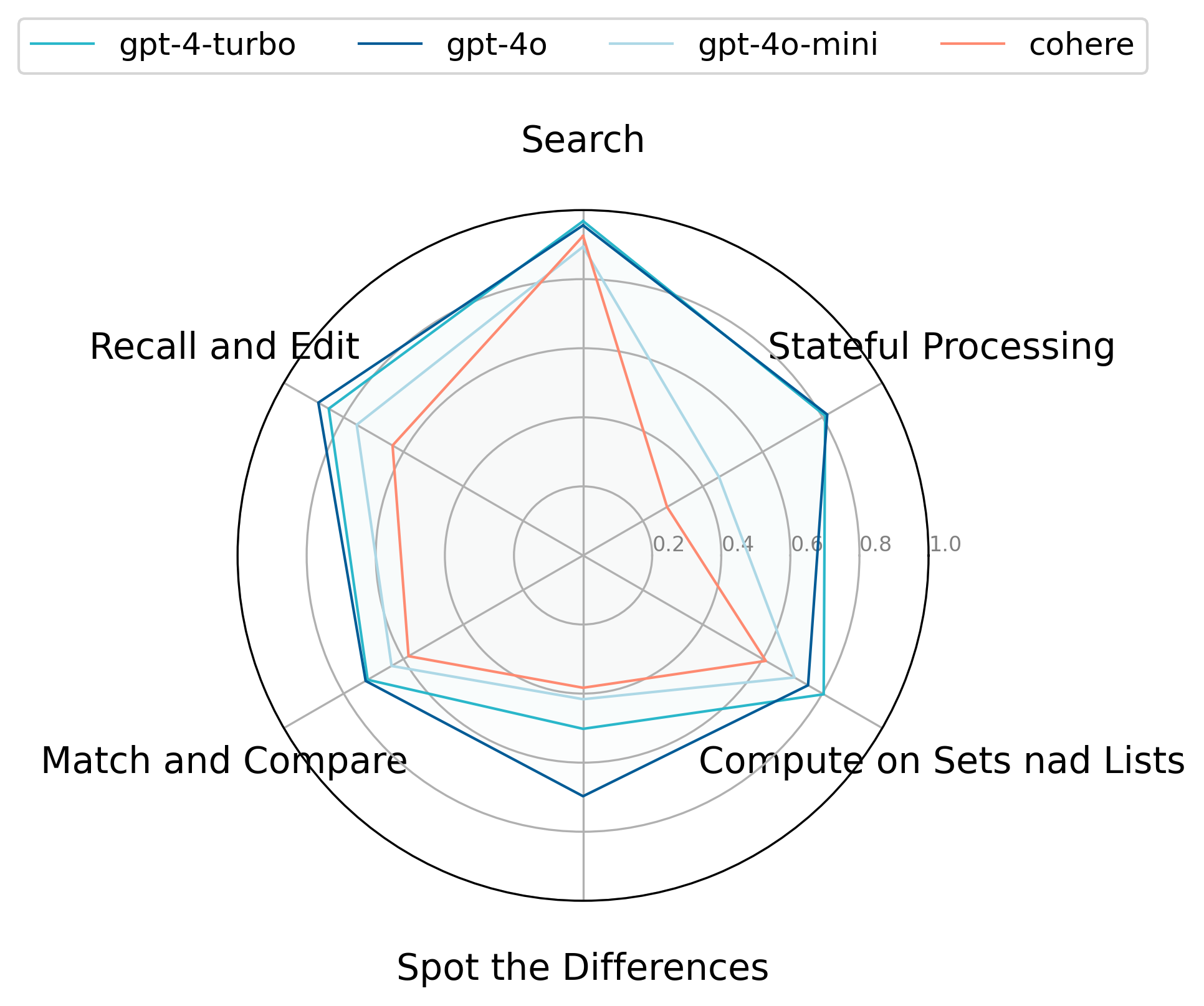
Radar chart comparing 9 models across 6 memory capability categories.
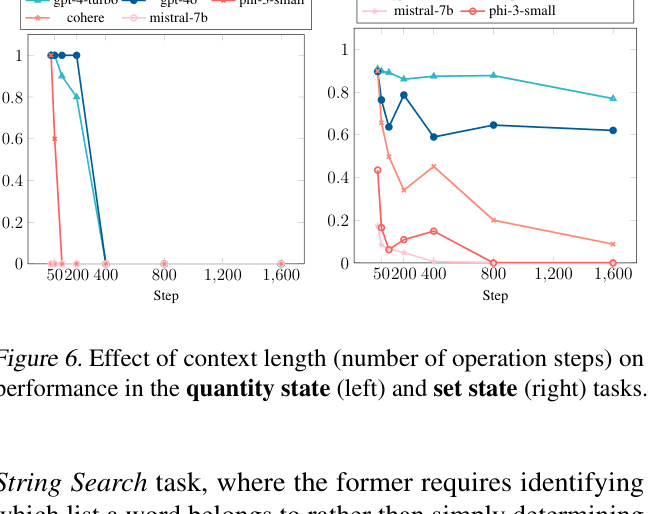
Performance curves for Stateful Processing (Quantity and Set) as the number of steps increases.
Main Takeaways
- High performance on NIAH (retrieval) does not predict performance on state tracking or editing; open-source models excel at search but fail at manipulation.
- Models struggle with negative constraints and comparisons (e.g., finding what is *not* present or identifying odd groups out).
- Composite tasks involving boundaries between memory compartments are significantly harder than their atomic components, highlighting a 'flattening' issue where models struggle to distinguish context sources.
- Increasing context length exacerbates failures in reasoning tasks (like Functional Updates) much faster than in retrieval tasks.