📝 Paper Summary
Medical Vision-Language Models (Med-VLMs)
Gaze-guided machine learning
The paper trains medical VLMs to follow the sequential visual search patterns of radiologists by using ordered eye-gaze data to supervise dedicated latent gaze tokens.
Core Problem
Standard VLMs process images as tokens but perform reasoning primarily in text space, ignoring the structured, sequential visual search process radiologists use to gather evidence.
Why it matters:
- Radiology diagnosis is inherently visual and sequential; converting visual signals immediately to text loses critical temporal evidence-gathering cues
- Existing methods treat gaze merely as a static spatial attention map (heatmap), discarding the 'reasoning' encoded in the order of fixation
- Purely text-based reasoning in VLMs can lead to hallucinations or failures in grounding findings to specific image regions
Concrete Example:
A standard VLM might correctly identify 'edema' but fail to localize it or understand which regions confirmed the diagnosis. By contrast, this method forces the model to 'look' at the hilar regions first, then the lung bases, mirroring a radiologist's scanpath.
Key Novelty
Sequential Gaze-Supervised Tokens
- Introduces dedicated 'gaze tokens' into the VLM's vocabulary that act as placeholders for intermediate visual evidence
- Supervises these tokens to predict image patch indices in the exact temporal order of a radiologist's eye-tracking scanpath
- Forces the model to internalize a human-like 'where to look next' strategy rather than just learning a static heatmap of important regions
Architecture
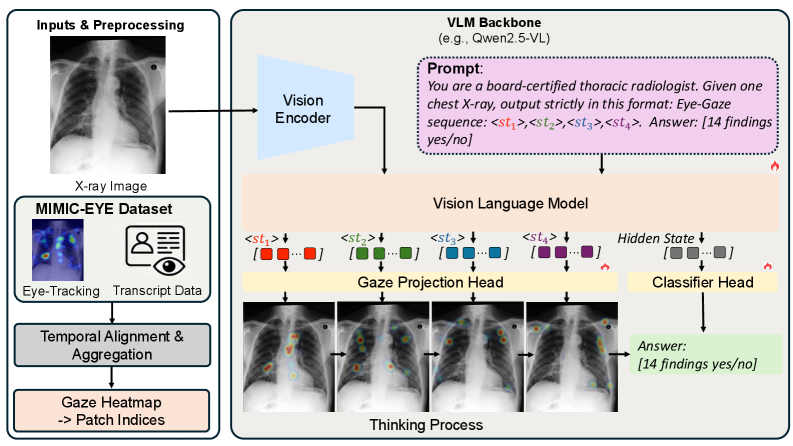
The model architecture showing the Qwen2.5-VL backbone, the insertion of special <st> tokens, and the two branches of supervision: patch index prediction (gaze) and text generation/classification.
Evaluation Highlights
- Achieves state-of-the-art in-domain performance on MIMIC-EYE (90.17 AUROC), surpassing both random (86.45) and shuffled (88.51) gaze baselines
- Demonstrates strong zero-shot robustness on external benchmarks, e.g., +5.09 F1 on RSNA compared to instruction-tuned baselines
- Original-ordered gaze consistently outperforms shuffled gaze, confirming that the temporal sequence of visual search encodes valuable reasoning signals
Breakthrough Assessment
8/10
Novel integration of temporal gaze sequences as direct token supervision rather than auxiliary loss. Strong empirical gains and improved interpretability in medical imaging.