📝 Paper Summary
Medical Vision-Language Models
Interactive Visual Reasoning
Reinforcement Learning for VLMs
ViTAR enables medical VLMs to emulate expert diagnostic workflows by performing iterative visual reasoning ('think-act-rethink') and interacting with images via bounding boxes, optimized through supervised and reinforcement learning.
Core Problem
Current medical VLMs rely on single-pass inference that processes entire images globally, neglecting the iterative 'scan-focus-refine' cognitive process used by human experts to identify fine-grained visual cues.
Why it matters:
- Single-pass models often overlook fine-grained abnormalities critical for diagnosis because they lack mechanisms to focus attention on specific Regions of Interest (ROIs)
- Existing methods relying on static image-text pairs fail to capture the dynamic, back-and-forth reasoning chains inherent in clinical decision-making
- Without iterative grounding, models are prone to hallucinated interpretations and broken reasoning chains due to a disconnect between visual perception and logical deduction
Concrete Example:
A clinician diagnosing a scan first observes globally, then focuses on a suspicious nodule (ROI), and finally reasons about that specific area to conclude. A standard VLM attempts to answer immediately from the global view, potentially missing the small nodule entirely or misinterpreting it due to lack of focused attention.
Key Novelty
Visual Thinking and Action-centric Reasoning (ViTAR)
- Introduces a 'think-act-rethink-answer' cognitive cycle where the model explicitly generates a thought, executes an action (e.g., marking an ROI), and then refines its reasoning based on the visual feedback
- Utilizes a two-stage training strategy: Supervised Fine-Tuning (SFT) to learn the expert-like interaction trajectory, followed by Reinforcement Learning (RL) via GRPO (Group Relative Policy Optimization) to optimize autonomous decision-making
- Treats medical images as interactive objects rather than static inputs, allowing the model to dynamically modify its visual focus during the inference process
Architecture
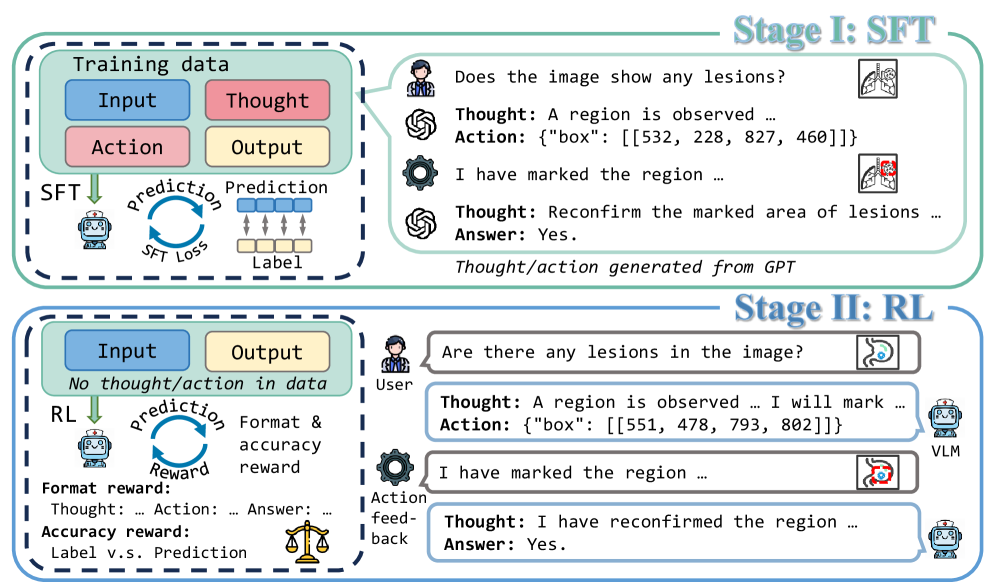
The ViTAR framework's 'think-act-rethink-answer' training and inference pipeline.
Evaluation Highlights
- Paper claims 'remarkable performance gains' across multiple medical VQA benchmarks compared to state-of-the-art models (exact numeric values not present in provided text snippet)
- Visual attention analysis demonstrates a shift in focus from global exploration in the 'think' phase to clinically critical regions in the 'rethink' phase
- Qualitative results show the model maintains high attention allocation to visual tokens throughout reasoning, mitigating the 'visual information diminishing' phenomenon
Breakthrough Assessment
8/10
Proposes a significant paradigmatic shift from static to interactive/iterative reasoning in medical VLMs, aligned with actual clinical workflows. The integration of RL for visual action optimization is a strong methodological contribution.
